服务器管理
注意:如果发现安装控制台报错,请先查看安装AnyBackup服务端软件,按照步骤执行,并且确保自己输入的命令正确。
Q1:把网卡绑定为逻辑网卡,服务器安装失败。
【问题原因】:网卡绑定后,配置文件中没有mac地址导致机器码无法正常生成。
【解决方案】:
-
执行
service network restart命令,重启网络,机器码重新生成。 -
执行
./uninstall.sh命令,卸载控制台残留,重新解压安装包后进行安装即可成功。
Q2:软件版控制台安装报错。
安装前检查配置文件/etc/sysctl.conf是否有如下两段配置:
net.ipv6.ip_nonlocal_bind=1
net.ipv4.ip_nonlocal_bind=1
若没有,需添加上:
命令参考:vi /etc/sysctl.conf,在最后一行加入上面两条命令,保存。
保存后执行sysctl –p命令生效。
若无此两段配置则会报错“Error:pls insert net.ipv4.ip_nonlocal_bind=1 to /etc/sysctl.conf”、
“Error:pls insert net.ipv6.ip_nonlocal_bind=1 to /etc/sysctl.conf”
配置文件中不添加此两段配置可能会导致安装WebService失败。
请安装前请务必检查添加,添加好后必须执行sysctl –p命令生效,否则依旧会报错。
Q3:软件版控制台安装中途集群服务报错“Error:Initialization of ABClusterService database failed。
此问题可能是由于操作系统时区不同导致,检查系统时区timedatectl,需要显示Asia/Shanghai。
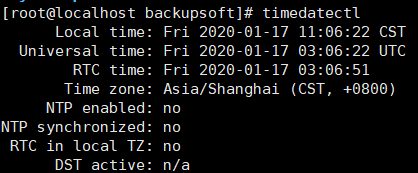
如不是上海时区,需修改为上海时区。命令:timedatectl set-timezone Asia/Shanghai。
执行后再检查一下,卸载后重装控制台。
Q4:控制台安装报错 “User already exists in uid,please replace UID !”
【问题原因】:控制台安装时,生成了eab用户,并固定uid为2048,当系统中已经存在uid为2048的用户后就会报此错误。
【解决方案】:报此错误后,先查看系统上uid为2048的用户是否可以删除。如果可以,请删除。
Q5:控制台安装报错 “ERROR”,如下图:
【问题原因】:此种错误多数情况下均为tar解压时添加 -o参数,导致软件包权限混乱。软件包在出厂时为了安全已经限定权限。
【解决方案】:请勿使用tar -zxvof解压软件包。

Q6:某些场景下需要重启服务器,使用reboot命令或safe_reboot.sh脚本重启控制台服务器后发现重启时间过长。
【问题原因】: 服务器原本自身启动时间有时即会较长,约达到3-10分钟。另外软件在停止时,服务是同步停止,如果DB服务先于其他服务停止,会导致某些服务停止时查询数据库,造成无法停止等待。在30-40分钟左右会超时自动退出,重启时间会在30-50分钟之间。
【解决方案】:可耐心等待一段时间。
集群管理
Q1:部署软件前,selinux状态未关闭,节点关机开机后,导致集群节点不可用。
【问题原因】:selinux状态开启状态,重启节点后,所有服务的进程及文件权限会被SELinux阻止,Svr服务自启动失败,无法拉起其他所有服务。
【解决方案】:操作节点开关机&重启操作之前,关闭selinux状态。若在节点重启后发现Selinux状态未关闭导致节点不可用,则操作selinux关闭后,需重启节点生效。集群环境需要检查所有节点的selinux均为关闭状态。
关闭方式:执行命令vi /etc/selinux/config打开config文件,将SELINUX=enforcing修改为SELINUX=disabled
Q2:集群部署完成后,用户登录一直提示 “用户可能在其他地方登录”,后台ip addr检查出现多个vip。
【问题原因】:此问题出现原因有多种。
-
安装集群的时候没有按顺序安装;
-
网络故障,各节点之间无法正常通信。
【解决方案】:
-
安装集群必须顺序安装,主节点安装完成后,再安装第一个从节点,安装完成后,再安装第二个从节点。
-
网络方面,需要保障两层网络可以通信。
Q3:集群安装为三节点之后不可再卸载。
【问题原因】:安装好集群后,不可再卸载还原为单节点。不可剔除节点,不可重装节点。
Q4:系统告警:证书即将过期。
【问题原因】:客户端线程会定期检查CA目录下client.pem和ca.pem证书的有效期,当证书有效期进入客户端检测线程所设置的阈值时,客户端会按照检测线程设置周期向服务端发出告警。
Q5:集群场景下,出现断电或断网后发现某些服务异常。
【问题原因】:集群场景下由于各节点需要同步数据,在突然断电或断网后会对数据库集群造成影响。启动时数据库服务和KAD服务拉起过程中等待其他节点启动。启动过程中某些python未启动,或KAD检测到某些服务异常,会将自己停止防止脑裂。
【解决方案】:三节点启动成功后,在三个节点上执行命令systemctl -a | grep AB,查看所有服务状态。查看到ABDBService和ABKADService状态均running正常的情况下,有其他服务异常,可以尝试重启异常服务。如果ABDBService和ABKADService状态异常,请联系技术或研发查看。
Q6:重启关机,如果大于两个节点的管理节点比业务节点开机晚,业务节点服务会一直卡在数据库连接上。
【可能原因】:业务节点检测的依旧是刚开机时候的dbvip的状态,未更新。
【解决方案】:输入systemctl restart ABSvrMgmService.service重新启动业务节点的SvrMgm服务,重新获取dbvip的状态,进行数据库连接。
Q7:重启节点或KMCService服务,会短暂出现无法进行加解密服务。
【问题原因】:重启KMC服务后,由于开源软件ekvdb选主机制的缺陷导致需要重新选主。
【解决方案】:等待ekvdb选主完成(5分钟内)。
Q8:登录后立即提示登录授权信息已失效,请重新登录。
【问题原因】:集群各节点时区或时间不一致。
【解决方案】:将集群的每个节点时间与时区修改为统一时间与时区。
Q9:断电关机重启节点,KMC加解密服务挂掉。
【问题原因】:节点恢复正常后,由于开源软件ekvdb选主机制的缺陷导致选主错误。
【解决方案】:需要手动介入拉起KMC服务,执行命令:systemctl restart ABKMCService。
Q10:集群节点操作异常断电断网重启后,DBService出现崩溃连接不上。
【问题原因】:数据库崩溃或者断电后,数据库的seqno值为-1,数据库选主错误导致数据库无法启动。
【解决方案】:数据库崩溃后,通过 --wsrep-recover方式获取当前本地数据库的seqno,再重新进行数据库选主,需要手动介入拉起DB服务:systemctl restart ABDBService。
注意:
- 三台控制节点都异常导致集群不可用,那么在重启开机的时候需要三台都开机,三台节点都异常的前提,如果开机一台或者两台,那么数据库会一直在拉起。
- 三个控制节点,异常一台或者两台,则无需同时开机或者重启异常节点。
Q11:内置客户端无法上线,ClientService状态出现如图箭头标注性错误。

【问题原因】:systemd系统机制问题:出现该错误会直接导致客户端启动的systemd unit直接崩溃消失掉,内置客户端无法上线。
【解决方案】:手动启动ClientService服务:systemctl restart ABClientService。
Q12:控制台出现“上报【节点IP】访问网络xxx链路不可达“。
**【**问题原因】:该IP网络不健康,不符合预期。
【解决方案】:可执行命令确认网络的监控状态:ping (ping6) ip -c count -W 5, count默认为10,丢包阈值默认为20%。
注意:丢包率大于20%认为网络不健康,上报 [节点ip] 访问网络xxx链路不可达。小于或等于20%则忽略,不上报。