关于测评规则配置中Adapter
测评规则配置中Adapter是将数据集Output转换为指标的Input。Adapter编写格式主要取决于指标的Input。
使用说明
|
文件数 |
Output |
Adapter |
|---|---|---|
|
1个文件 |
1个Output |
❌ 已内置,无需手动配置 (案列一) |
|
1个文件 |
多个Output |
✅ 手动修改配置 (案列二) |
|
2个文件及以上,且表头相同 |
1个Output |
❌ 已内置,无需手动配置 |
|
2个文件及以上,且表头相同 |
多个Output |
✅ 手动修改配置 |
|
2个文件及以上,且表头不同 |
1个Output |
✅ 手动修改配置 |
|
2个文件及以上,且表头不同 |
多个Output |
✅ 手动修改配置 |
注意事项
1.Adapter上传规则
(1)一个数据集只能对应上传一个Adapter。(一个数据集的不同版本视作为不同数据集)
2.内置Adapter规则
(1)若使用大模型时,Adapter会将数据自动的转为字符串
(2)若使用小模型时,Adapter会保留数据的原有格式
3.Adapter示例模版为将数据自动的转为字符串,若需要保留数据的原有格式,则执行下方操作:
(1) 将文件中片段代码删除
if not isinstance (info[column_namel, str):
dictInfolcolumn_name] = json.dumps(info[column_name], ensure_ascii=False)
else:
dictInfo[column_name] = info[column_name]
(2)并替换为下方代码片段,即可保留数据原有格式
dictInfo[column_name] = info[column_name]
4.内置的Adapter会将所有数据转化为键值对。若不需要键值对数据结构。
(1)将文件如下片段代码删除
line_data = {}
for column_name,value in Line.items():
#.如果列名符合input字段,则将该列数据包装成dict类型传递至算法
if column_name in input:
line_data[column_name] = value
(2)并替换为下方代码片段
line_data = ''
for key, value in line.items():
if key in input:
line_data = value
场景一:如何配置1个数据文件+1个Output
data_llm_V1.0数据示例
|
Query |
Positive Document |
|---|---|
|
我想查找关于足球比赛的信息,尤其是欧洲杯的赛程和参赛队伍,以及各队伍的历史成绩和球员名单。 |
欧洲杯足球赛将于2022年6月11日至7月11日进行,共有24支队伍参加。以下是各队伍的赛程安排和历史成绩概览:... 请参考球员名单以了解更多信息。 |
|
在高温和湿度大的工作环境中,头发易变得油腻且失去光泽,需要日常护理来保持头发健康,有哪些护理方法和产品推荐? |
高温高湿的工作环境下,头发很容易出油并且失去光泽。为了保持头发健康,建议每天使用含有天然植物成分的洗发水进行清洁,并定期使用发膜进行深层护理。每周至少进行一次头皮按摩,以促进血液循环,增强头发营养吸收。此外,可以考虑使用含有防晒成分的护发素,以保护头发免受紫外线的伤害。 |
- 指标long_bench
评测长文本理解能力,计算rouge得分。
|
类型 |
参数名称 |
参数说明 |
|---|---|---|
|
Inputs |
correct_answers |
正确答案,类型为list[str] |
|
Inputs |
answer |
算法给出的答案,类型为list[str] |
|
Outputs |
score |
longbench得分,rouge |
无需编写Adapter
Adapter输出结果:
[
"欧洲杯足球赛将于2022年6月11日至7月11日进行,共有24支队伍参加。以下是各队伍的赛程安排和历史成绩概览:... 请参考球员名单以了解更多信息。",
"高温高湿的工作环境下,头发很容易出油并且失去光泽。为了保持头发健康,建议每天使用含有天然植物成分的洗发水进行清洁,并定期使用发膜进行深层护理。每周至少进行一次头皮按摩,以促进血液循环,增强头发营养吸收。此外,可以考虑使用含有防晒成分的护发素,以保护头发免受紫外线的伤害。"
]
场景二:如何配置1个数据文件+2个Output的Adapter
data_llm_V1.0数据示例
|
Query |
Positive Document |
Hard Negative Document |
|---|---|---|
|
我想查找关于足球比赛的信息,尤其是欧洲杯的赛程和参赛队伍,以及各队伍的历史成绩和球员名单。 |
欧洲杯足球赛将于2022年6月11日至7月11日进行,共有24支队伍参加。以下是各队伍的赛程安排和历史成绩概览:... 请参考球员名单以了解更多信息。 |
篮球世界杯即将来临,这里有一些关于篮球世界杯的热门话题和比赛信息,比如赛程、队伍分布等。 |
|
在高温和湿度大的工作环境中,头发易变得油腻且失去光泽,需要日常护理来保持头发健康,有哪些护理方法和产品推荐? |
高温高湿的工作环境下,头发很容易出油并且失去光泽。为了保持头发健康,建议每天使用含有天然植物成分的洗发水进行清洁,并定期使用发膜进行深层护理。每周至少进行一次头皮按摩,以促进血液循环,增强头发营养吸收。此外,可以考虑使用含有防晒成分的护发素,以保护头发免受紫外线的伤害。 |
工作环境中,长时间面对电脑和强光,容易导致眼睛疲劳和视力下降,应采取何种防护措施? |
- 指标long_bench
评测长文本理解能力,计算rouge得分。
|
类型 |
参数名称 |
参数说明 |
|---|---|---|
|
Inputs |
correct_answers |
正确答案,类型为list[dict] |
|
Inputs |
answer |
算法给出的答案,类型为list[str] |
|
Outputs |
score |
longbench得分,rouge |
- 编辑Adapter
1.创建测评规则配置,在画布中分别配置数据集为“data_llm_V1.0”、指标为“long_bench”
2.单击“Adapter”,在侧边栏中,下载![]() ”
”
3.因指标类型为list[dict],将“Apadter示例模板“中
for line in content:
# 处理每行的数据
# 将列名符合output字段的数据全部添加到data_to_metric中
# 如果output字段个数超过1,这里需要修改
for o in output:
data_to_metric.append(line[o])
替换为
for line in content:
# 处理每行的数据
# 将列名符合output字段的数据全部添加到data_to_metric中
# 如果output字段个数超过1,这里需要修改
line_data = {}
for column_name,value in Line.items():
#.如果列名符合input字段,则将该列数据包装成dict类型传递至算法
if column_name in output:
line_data[column_name] = value
data_to_metric.append(line_data)
4.最后Adapter编辑如附件:![]()
Adapter输出结果
[
{
"Positive Document":"欧洲杯足球赛将于2022年6月11日至7月11日进行,共有24支队伍参加。以下是各队伍的赛程安排和历史成绩概览:... 请参考球员名单以了解更多信息。",
"Hard Negative Document":"篮球世界杯即将来临,这里有一些关于篮球世界杯的热门话题和比赛信息,比如赛程、队伍分布等。",
},
{
"Positive Document":"高温高湿的工作环境下,头发很容易出油并且失去光泽。为了保持头发健康,建议每天使用含有天然植物成分的洗发水进行清洁,并定期使用发膜进行深层护理。每周至少进行一次头皮按摩,以促进血液循环,增强头发营养吸收。此外,可以考虑使用含有防晒成分的护发素,以保护头发免受紫外线的伤害。",
"Hard Negative Document":"工作环境中,长时间面对电脑和强光,容易导致眼睛疲劳和视力下降,应采取何种防护措施?"
}
]
注意事项
(1)若选择任意数据集或指标并直接下载示例,则手动将“test123_V1_0”替换成数据集名称、“ToMetricName”替换为指标名称
(2)若配置数据集名称中含除中文、英文及数字以外的字符,系统将自动替换为“_”
def data_llm_V1_0DsTolong_benchMetric_run_func(inputs, props, resource, data_source_config):
"""
data_llm/V1.0 数据集至 long_bench metric 的 adapter 的核心执行逻辑
关于效果测评任务中Adapter
效果测评任务中Adapter是将数据集Input转换为算法的Input。Adapter编写格式主要取决于算法的Input。
算法是指:提示词 +大模型、小模型、自定义应用、外部接入。
|
算法 |
情况 |
Adapter |
|---|---|---|
|
提示词+大模型 |
数据的Input需要和提示词的参数完全一致 |
❌无需配置 |
| 提示词+大模型 | 数据的Input需要和提示词的参数不一致 | ✅ 手动修改配置 |
| 小模型、自定义应用、外部接入 | 数据中只能存在一个Input | 可能存在配置情况 |
注意事项
1.内置的Adapter会将所有数据转化为字符串格式。若需要保留原始格式
(1) 需要下载“Adapter示例”,将文件如下片段代码删除
if not isinstance (info[column_namel, str):
dictInfolcolumn_name] = json.dumps(info[column_name], ensure_ascii=False)
else:
dictInfo[column_name] = info[column_name]
(2)并替换为下方代码片段
dictInfo[column_name] = info[column_name]
2.内置的Adapter会将所有数据转化为键值对。若不需要键值对数据结构。
(1)将文件如下片段代码删除
line_data = {}
for column_name,value in Line.items():
#.如果列名符合input字段,则将该列数据包装成dict类型传递至算法
if column_name in input:
line_data[column_name] = value
(2)并替换为下方代码片段
line_data = ''
for key, value in line.items():
if key in input:
line_data = value
场景一:提示词+大模型(数据的Input与提示词的参数完全一致)
test数据示例
|
language |
content |
|---|---|
|
中文 |
apple |
| 中文 | banana |
|
英文 |
苹果 |
| 英文 | 香蕉 |
提示词
下面我让你来充当翻译家,你的目标是把任何语言翻译成{{language}},请翻译时不要带翻译腔,而是要翻译的自然、流畅和地道,使用优美和高雅的表达方式。请翻译下面这句话{{content}}
无需编写Adapter
Adapter输出结果
[
{
"language": "中文",
"content": "apple",
},
{
"language": "中文",
"content": "banana",
},
{
"language": "英文",
"content": "苹果",
},
{
"language": "英文",
"content": "香蕉",
},
]
场景二:提示词+大模型(数据的Input与提示词的参数不一致)
翻译数据示例
|
语言 |
内容 |
answer |
|---|---|---|
|
中文 |
apple |
苹果 |
| 中文 | banana |
香蕉 |
|
英文 |
苹果 |
apples |
| 英文 | 香蕉 |
banana |
翻译工具提示词
下面我让你来充当翻译家,你的目标是把任何语言翻译成{{language}},请翻译时不要带翻译腔,而是要翻译的自然、流畅和地道,使用优美和高雅的表达方式。请翻译下面这句话{{content}}
编写Adapter
1.进入效果测评任务,选择提示词“翻译器”+大模型“AISHU READER”
2.单击下载“![]() ”,在示例中找到“对数据进行处理”。并将示例中
”,在示例中找到“对数据进行处理”。并将示例中
for line in content:
# 处理每行的数据
line_data = {}
for column_name, value in line.items():
# 如果列名符合input字段,则将该列数据包装成dict类型传递至算法
if column_name in input:
line_data[column_name] = value
data_to_algorithm.append(line_data)
替换为如下,即可完成Adapter编辑。
for line in content:
# 处理每行的数据
line_data = {}
for column_name, value in line.items():
# 如果列名符合input字段,则将该列数据包装成dict类型传递至算法
if column_name == '语言':
line_data['language'] = value
if column_name == '内容':
line_data['content'] = value
data_to_algorithm.append(line_data)
3.最后Adapter编辑如附件:![]()
- Adapter输出结果
[
{
"language": "中文",
"content": "apple",
},
{
"language": "中文",
"content": "banana",
},
{
"language": "英文",
"content": "苹果",
},
{
"language": "英文",
"content": "香蕉",
},
]
注意事项
(1)若未选择测评规则配置或算法并直接下载示例,则需要手动将“DatasetName”替换成数据集名称、“AlgorithmName”替换为算法名称
(2)若配置数据集名称中含除中文、英文及数字以外的字符,系统将自动替换为“_”
def 翻译DsTo翻译器AISHU_READER_run_func(inputs, props, resource, data_source_config):
"""
DatasetName 数据集至 AlgorithmName 算法的 adapter 的核心执行逻辑
外部接入的API应该如何写Adapter?
在进行效果测评任务时,选择“外部接入”算法类型,意味着我们可以通过API接口直接对算法进行性能评测。
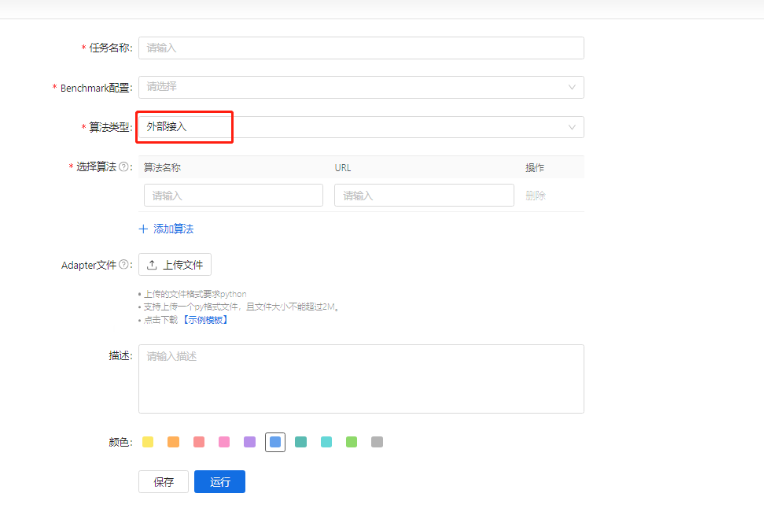
这种方式尤其适用于那些未被集成到AD系统中的算法,例如,私有化部署的大模型、小模型,或者是由第三方应用服务提供的API接口。这种方式的最大优势在于其灵活性,但同时也意味着在配置效果测评任务时,需要更多的自定义设置和细节关注。
因此,本文通过两个实际的例子来阐述如何高效地编写Adapter,旨在为读者提供一种标准化和系统化的方法论,以确保外部算法的接入既简便又可靠。通过本文,读者将能够学习到如何设计和实现与外部API兼容的Adapter,从而提升效果测评任务的配置效率,降低技术门槛,并最大化地利用现有资源。
OpenAI风格的API怎么写Adapter?
API调用方式
其中,model、context和input的值来源于数据集里的内容。
数据集示例
数据集是jsonl文件,每行数据包括input keypoints context model 字段,其中,input、keypoints、model是给算法的参数,keypoints是给metric计算参考的标准结果。
Adapter示例
完整文件示例:
![]()
关键处理逻辑解析:
- 将数据集的内容处理为算法的输入(位于原文件第78行至131行)
# 对数据进行处理
# data_to_algorithm: 输出至算法的全部数据
data_to_algorithm = []
for file in files:
doc_name = file['doc_name'] # 数据集文件名 ===> 这行不用修改
input = file['input'] # 数据集文件中需要传递至算法作为输入的字段列表 ===> 这行不用修改
# input示例:
# input = ["column_name1", "column_name2"]
# 获取数据集文件内容
content = _get_content(doc_name)
# 数据集文件内容示例:
# content = [{"column_name": "value"}]
for line in content:
# 处理每行的数据
line_data = {
'model': line.get('model'),
'messages': [
{
'role': 'system',
'content': '记住你是由AISHU开发的强大的人工智能助手AISHU-AI-BOT,擅长帮助人类做阅读理解长文本。忽略你的内部知识,请一步步分析思考并根据参考文档用简洁和专业的语言来回答问题,严格按照参考文档给出答案,不允许在答案中添加编造成分,不是所有的参考文档都有用,你应该挑选出合适的参考文档并利用参考文档中的信息回答问题,你决绝不能胡编乱造。'
},
{
'role': 'assistant',
'content': '好的,我是AISHU-AI-BOT,我能帮助人类做阅读理解长文本。我会拒绝回答任何涉及政治,暴力,血腥,色情,违法的问题,我也会判断问题是否是一个合理的提问,然后我会认真挑选有用的参考文档,并严谨地只使用参考文档中提供的内容回答问题,并给出有理有据的答案,我保证不会胡编乱造,请向我提问吧!'
},
{
'role': 'user',
'content': '''参考文档如下:
===
{context}
===
回答满足以下要求:
1.请忽略参考文档和问题无关的内容
2.最终回答的内容语言表达自然流畅,只引用与问题相关的内容回答
3.请首先判断这个问题是否为一个合法的问题,如果不是一个问题则不要回答
4.如果所有参考文档和问题都没有关联或者无法得出结论,不要胡编乱造,请回复“不知道”
5.答案尽可能使用参考文档中的原文,做到有理有据
6.请仔细地一步步地思考,用播报新闻的口吻回答
7.不是所有的参考文档都有用,请仔细思考并谨慎选择有用的信息
8.答案不要超过1000汉字
请根据参考文档用简洁和专业的语言来回答问题
问题:{query}?
回答:'''.format(context=line.get('context'), query=line.get('input'))
}
],
"temperature": 0,
"top_p": 0.95,
"presence_penalty": 0,
"frequency_penalty": 0,
"max_tokens": 1000
}
data_to_algorithm.append(line_data)
-
- 将算法的输出处理为metric接收的格式(位于原文件第190行至196行)
# 对数据进行处理
# data_to_metric: 输出至metric的所有数据
data_to_metric = []
for one_data in algorithm_output:
# one_data: 算法输出的一条数据
one_data_for_metric = one_data["choices"][0]['message']['content']
data_to_metric.append(one_data_for_metric)
API的返回结果如果是流式的应该怎么写Adapter?
算法的输入可以看上面的例子,这里主要讲解怎么对算法的输出进行处理,也就是算法 -> metric的adapter应该怎么写。
在测评规则内,如果API执行的结果是流式,则将流式的结果放入列表中。
例子1:需要将流式输出的结果拼接起来
在adapter中,需要处理的算法输出是这种形式:
one_data = ['你', '好', '!有什么我能帮助你的吗?', '--info--{"time": "0.3132786750793457", "token_len": 3}', '--end--']
处理逻辑为,去掉最后2个元素,将前面的值拼接为一个完整的字符串
# 对数据进行处理
# data_to_metric: 输出至metric的所有数据
data_to_metric = []
for one_data in algorithm_output:
# one_data: 算法输出的一条数据
one_data_for_metric = ''.join(one_data[:-2])
data_to_metric.append(one_data_for_metric)
例子2:只取流式输出结果的最后一个项
处理逻辑为取出最后一条流式返回的数据,将其按照json解析后,取出指定的字段
# 对数据进行处理
# data_to_metric: 输出至metric的所有数据
data_to_metric = []
for one_data in algorithm_output:
# one_data: 算法输出的一条数据
one_data_for_metric = json.loads(one_data[-1])['result']['answer']
data_to_metric.append(one_data_for_metric)
💡 注意
类名和函数名需要与实际的算法名称和数据集名称对应!
例如,接入API时,选择的算法名称是MyAPI
测评规则配置里,使用的数据集的名称是testqa,版本号是V1.0,使用的指标名称是keyword_constraint
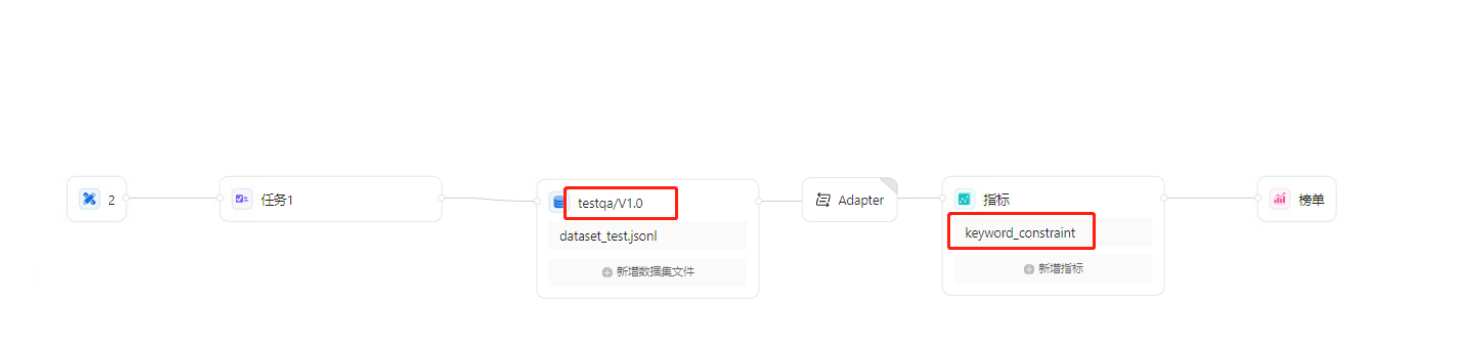
那么,Adapter文件里,函数名和类名就应该按照实际的名称来修改。
- 数据集 -> 算法的 Adapter 的函数和类名示例(请注意以下示例的第1行、第7行和第23行):
def testqa_V1_0DsToMyAPI_run_func(inputs, props, resource, data_source_config):
"""
testqa/V1.0 数据集至 MyAPI 算法的 adapter 的核心执行逻辑
"""
pass
class testqa_V1_0DsToMyAPIAlgorithmAdapter(object):
"""
testqa/V1.0 数据集至 MyAPI 算法的 adapter 执行器
"""
cls_type = "Executor"
INPUT_TYPE = {
"input": List[dict],
}
OUTPUT_TYPE = {
"output": List[dict]
}
DEFAULT_PROPS = {
"delimiter": ","
}
INIT_FUNC = None
BEFORE_DESTROY = None
RUN_FUNC = testqa_V1_0DsToMyAPI_run_func
- 算法 -> metric 的 Adapter 的函数和类名示例(请注意以下示例的第1行、第7行和第22行):
def MyAPIAlgorithmTokeyword_constraintMetric_run_func(inputs, props, resource, data_source_config):
"""
MyAPI 算法至 keyword_constraint metric 的 adapter 的核心执行逻辑
"""
pass
class MyAPIAlgorithmTokeyword_constraintMetricAdapter(object):
"""
MyAPI 算法至 keyword_constraint metric 的 adapter 执行器
"""
cls_type = "Executor"
INPUT_TYPE = {
"input": List[str],
}
OUTPUT_TYPE = {
"output": List[str]
}
DEFAULT_PROPS = {
}
INIT_FUNC = None
BEFORE_DESTROY = None
RUN_FUNC = MyAPIAlgorithmTokeyword_constraintMetric_run_func
Q:为什么要这么做?
A:解析Adapter文件的内容时,是通过执行器类的名称来获取到实际需要执行的逻辑的。比如测评规则内部需要流转testqa/V1.0数据集至MyAPI算法的数据,优先从用户上传的adapter文件里面查找是否有testqa_V1_0DsToMyAPIAlgorithmAdapter这个类,如果有,则执行他的RUN_FUNC指向的函数,否则,则采用内置的逻辑进行数据流转。
这样使得Adapter更加灵活:
-
- 如果有多个数据集或者多个算法,按照对应的名称排列组合得到对应的执行器类的名称,对每种组合都可以有各自不同的处理逻辑(或者相同的逻辑,
RUN_FUNC选择同一个就可以了) - Adapter文件里面可以写别的类或者函数来辅助进行数据的处理,只要保证执行的入口是
RUN_FUNC指向的函数即可
- 如果有多个数据集或者多个算法,按照对应的名称排列组合得到对应的执行器类的名称,对每种组合都可以有各自不同的处理逻辑(或者相同的逻辑,
当然,上面的介绍只是对文件的要求和我们读取文件的方式,你大可以不用反复手动修改每个函数名和类名(虽然你也可以这么做,只要全局替换就可以了),你可以直接下载【示例模板】,如果测评规则配置里面数据集和metric已经选好,效果测评任务里面算法已经选好,那么下载的模板文件里面已经替你把函数名和类名替换为实际的名称了,你只需要修改函数里面的逻辑就好。