OpenSearch默认设置是在综合考虑数据可靠性、搜索实时性以及写入速度等因素下进行的配置。实际使用场景中,我们通常会针对客户的真实数据与场景需要进行细粒度的优化操作。如下分别从写入与搜索两个层面阐述AnyRobot做的优化工作。
写入优化
➢ translog flush间隔调整
这是影响OpenSearch写入的最大因素。translog flush操作是将内存中的数据写入磁盘,典型的IO操作。OpenSearch为了写入的可靠性,默认采用的是每个写入请求都flush到磁盘的机制,确保写操作是可靠的。此处可通过引入异步写入机制提升写入性能,但前提是牺牲了一定的可靠性,因此需要根据实际场景选择性的使用,配置如下:
index.translog.durability: async
index.translog.sync_interval: 120s
index.translog.flush_threshold_size: 1024mb
如上,采用async异步方式进行写入,若满足120s或者1024mb任一条件,则进行flush刷盘操作。AnyRobot当前的索引模式都分别设置了上述配置,在写入性能上有了较大的提升。同时这个特性需要结合客户的真实数据场景决定是否选择该模式。
➢ 索引刷新间隔refresh_interval调整
每次索引的refresh操作均会产生一个新的Lucene段,增大refresh间隔,可减少段的创建以及后续的Force Merge操作。这里提升性能的前提是增加写入数据可读的时间。
index.refresh_interval: 120s
如上,AnyRobot将索引刷新间隔从默认的1s调整为120s,这优化了写入牺牲了数据可搜索的时间。对于日志处理系统这类写多读少的场景,往往推荐增大该配置。
➢ indexing buffer
indexing buffef在为doc创建索引时应用,当该缓冲区满了后数据会刷入磁盘,生成一个新的segment。因此,适当的增加该值能够提升写入性能。
indices.memory.index_buffer_size:10%
该值默认为整个Java Heap空间的10%,有些场景下AnyRobot系统会将该值调整到15%左右,当然这里需要结合OpenSearch节点可用Heap空间与Shard数量综合考虑后作调整。
➢ 使用批处理的方式写入
批量写效率更高,每个请求最好避免超过几十兆,避免给集群带来压力。AnyRobot系统中,Logstash服务当前以1000~1500 Docs的批处理方式写入OpenSearch,利用批处理的高效写入方式。也可进一步根据真实数据场景,同时结合机器资源实践出最佳批处理Docs的数量。
➢ 数据写入使用自动生成的DocID
如果写入doc时指定了DocID,则OpenSearch会先尝试读取原来doc的版本号以判断是否需要更新,这会涉及一次读取磁盘的操作。总结如下:
-
- 减少磁盘的IO操作;
- 自动生成的DocID具有一定的规律,有利于FST的压缩。
当前AnyRobot系统中,Logstash对于写入OpenSearch中的每个Doc没有明确定义DocID,每个Doc的ID均由OpenSearch自动生成。
➢ 对数据进行精准建模(重要的性能优化点)
-
- 准确知道写入的字段后续的查询用途,比如:如果没有查询操作可直接设置为高效的keyword类型;
- 将不需要建立索引的字段的index属性设置为not_analyzed,对字段不分词或者不索引,可以减少很多运算操作,降低CPU使用;
- 如果在搜索字段时不需要计算打分,则可以禁用字段的Norms属性。
当前AnyRobot系统中对一些基础字段默认配置的schema为keyword类型,即OpenSearch底层对此不分词,直接当成term创建倒排索引。当前查询默认以时间为基准进行排序,因此AnyRobot系统写入的每个字段默认都是关闭Norms属性的,在索引数据阶段减少了一定的计算开销。
➢ 分词器选用ik_max
OpenSearch在索引数据过程中,不同的分词器因为其内部运算复杂度的不同,因此在数据写入性能方面也会有一些差异。AnyRobot当初在选型分词器时对ik_max与hanlp两种常用的分词器进行了对比分析,性能测试如下:
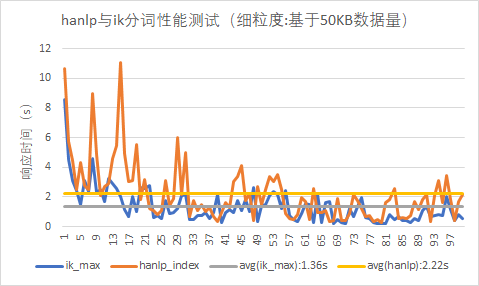
因为分词的内部机制不同,所以从测试结果可知ik_max的写入性能要优于hanlp。当然hanlp在对自然语言的分词处理中表现的更加精确。结合AnyRobot系统处理的日志场景分析来看,总结为以下两点:
-
- 日志主要是记录操作行为、程序系统行为、告警记录等,且绝大多数为英文,同时不会产生太多语义分词差异;
- 应用hanlp在索引数据上性能不如ik_max。
综上,在均能满足日志数据分词处理的场景下,ik_max在分词处理上需要做的工作更少(比如:doc数量、词频、positions、offset等),因此在一定程度上降低了索引过程中的运算任务,进一步提升了写入性能。
搜索优化
➢ 为OS Cache预留足够的内存
命中Cache可以降低对磁盘的直接访问频率,搜索很依赖对OS Cache的命中。如果某个请求需要从磁盘读取数据,则一定会产生相对较高的延迟。因此应该至少为OS Cache预留一半的可用物理内存,更大的内存有更高的Cache命中率。OpenSearch底层以索引与数据分层的方式对搜索进行优化,对于类似匹配查找等的计算当然是放到内存中计算会更加高效。AnyRobot系统对OpenSearch进行配置时,默认会为Cache预留一般的资源,比如:给予OpenSearch容器配置62GB的内存,OpenSearch应用配置31GB,剩余31GB留给OS Cache。
➢ Hot节点使用更快的硬件
搜索性能在一般情况下更多依赖IO能力,使用SSD会比旋转类存储介质好的多。如果搜索类型包含较多的计算,则可以考虑使用更快的CPU。AnyRobot系统当前OpenSearch集群默认以Hot-Warm的架构部署,如果客户资源允许,默认会为Hot节点配置SSD,使得Hot节点能够支撑海量的数据写入与低延时的查询要求。
➢ 为只读索引执行force-merge操作
定期为不再更新的只读索引执行force merge操作,将OpenSearch分片下的多个分段合并为一个分段,有如下2个方面的好处:
-
- 一个分段对应到Lucene底层一个完整的倒排索引,倒排索引之间存储彼此独立,若把多个倒排索引单元合并为一个,则内部很多元数据部分可共用,比如:FST中的前缀字典树结构可共用,达到节省内存空间占用的目的;
- OpenSearch执行搜索过程中,会对分片下的所有分段进行一一遍历,然后获取结果。当分段数过多则遍历过程的性能消耗也会很大。若将众多分段合并为一个,则可提升遍历效率,进而提升搜索性能。
AnyRobot系统当前会定期的对只读索引进行force-merge操作,由于force-merge也会消耗一定的性能,因此通常会选定在夜间的业务低峰期执行force-merge,这样几乎不会影响到白天数据业务高峰期的数据处理。
➢ 基于索引名称的时间与类型信息,按需缩小搜索的索引范围
AnyRobot数据流在写入OpenSearch过程中,会把处理的业务数据对应的类型信息type与时间信息datetime填充到OpenSearch存储的索引名称中,比如:type-2021.01.01。对于日志的搜索,不管是搜索结果的处理还是聚合计算的分析,最基本的2个条件就是search_time_range(搜索时间范围)与search_logs_type(搜索日志类型)。
日志类型的处理AnyRobot系统内部同时引入了日志分组的概念用于大范围的表示日志类型;AnyRobot系统在处理搜索任务时,首先会依据search_time_range过滤出满足该时间段的索引集合a-indices,接着再根据选定的日志分组(若没有选定,则跳过此次索引集合过滤的处理)对a-indices进行进一步过滤,最终得到需要执行搜索的索引集合b-indices,此时OpenSearch底层真正需要处理的索引集合则变成了b-indices。实践证明该优化策略在搜索性能上的提升非常明显。