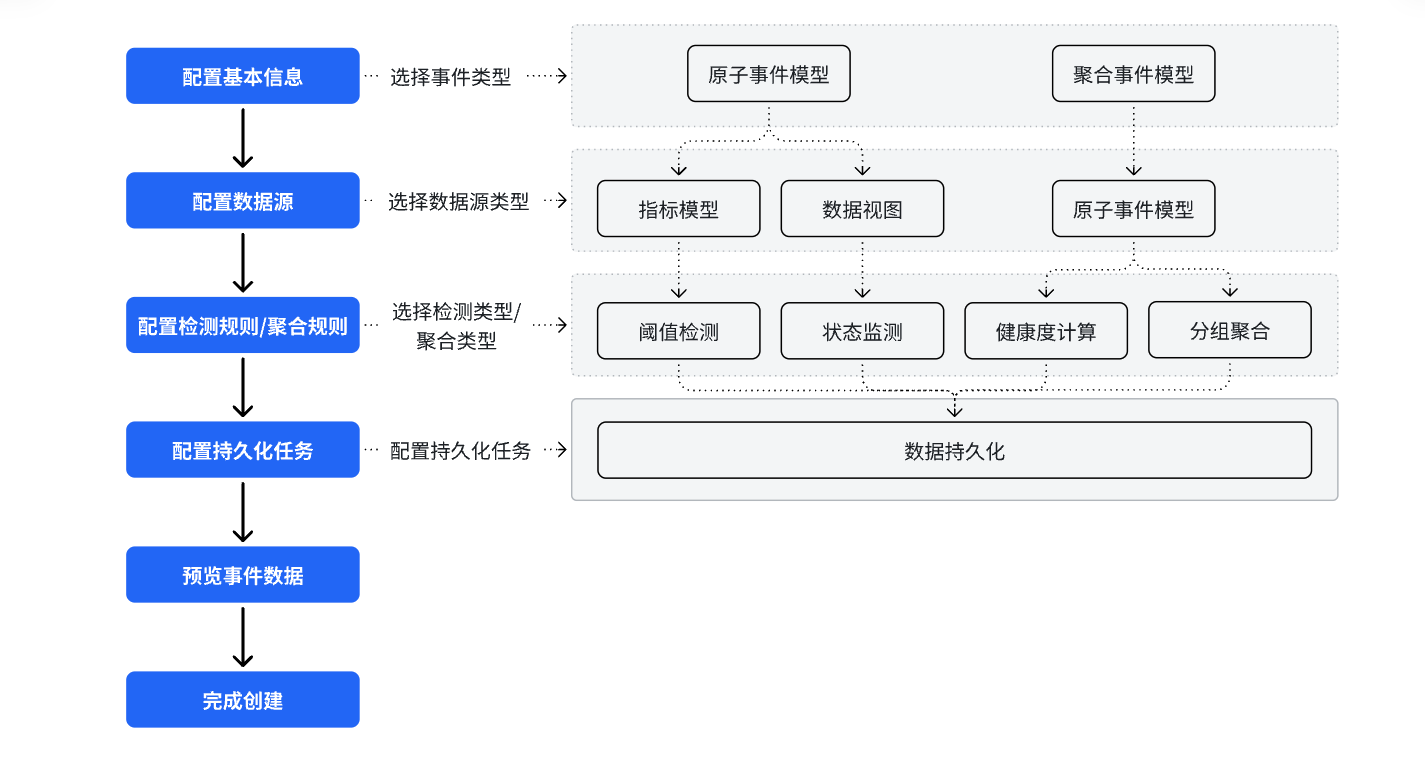
AnyRobot事件模型管理模块支持创建原子事件、聚合事件两种类型的事件模型,不同类型事件模型支持配置的数据源类型、检测规则/聚合规则类型不同,并支持配置事件数据的持久化。创建事件模型需要完成事件模型基本信息、数据来源、检测规则及数据持久化等参数的配置操作,具体配置流程如下:
快速阅读链接如下:
_61.png) 提示:您可以参照下方详细配置说明,手动创建所需事件模型。您也可以导入包含事件模型配置参数的合规文件,批量创建事件模型。
提示:您可以参照下方详细配置说明,手动创建所需事件模型。您也可以导入包含事件模型配置参数的合规文件,批量创建事件模型。
进入数据管理>数据模型>事件模型配置页面,点击【+新建】,进入“新建事件模型”的配置流程,如下所示:
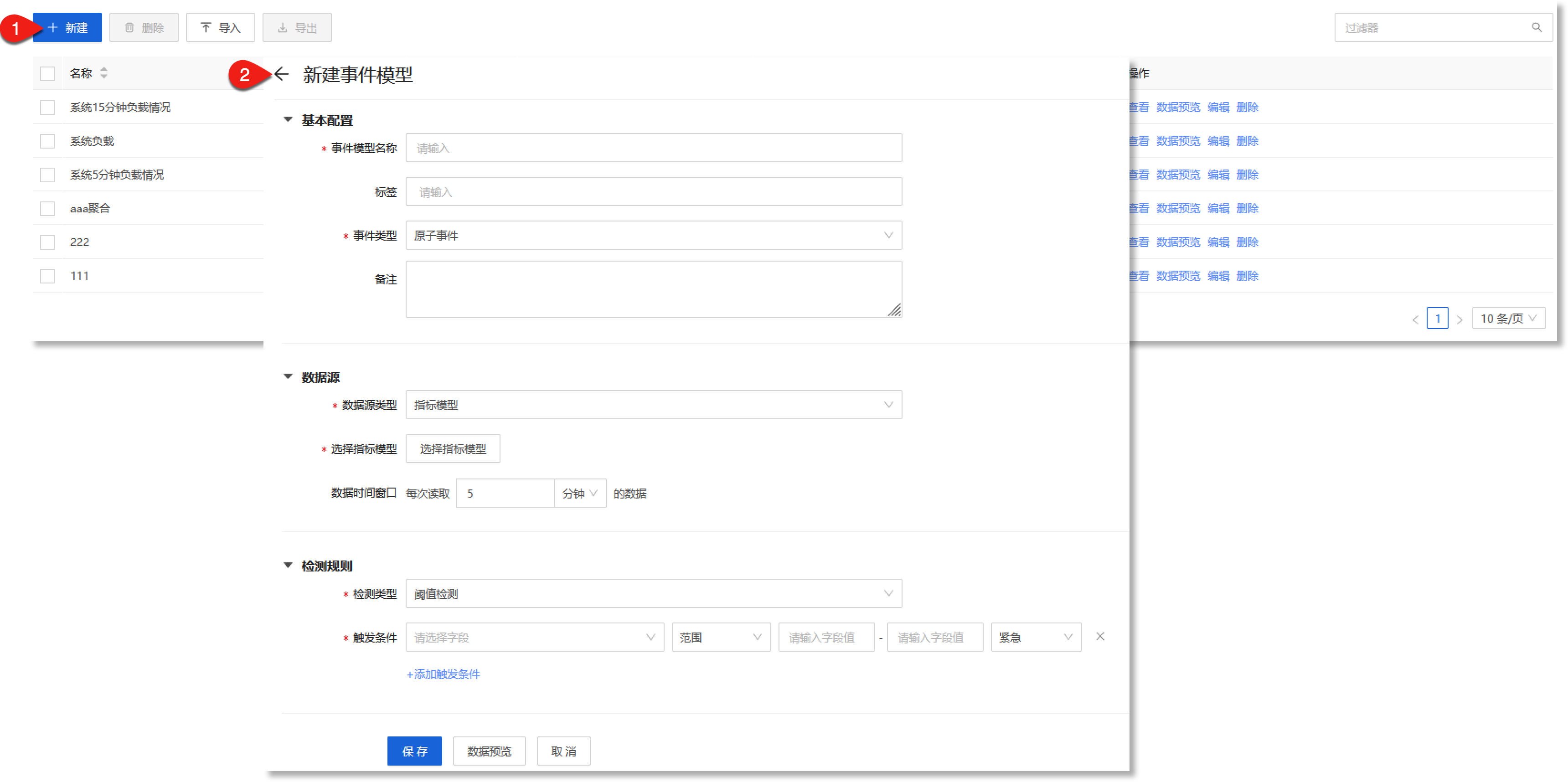
配置事件模型名称、所属*事件类型(原子事件或聚合事件)等基本信息,配置参数说明如下:
• *事件模型名称:填写事件模型的名称,此名称具有全局唯一性。
说明:事件模型名称不能重复,且不能为空,需≤40个字符。
• 标签:设置事件模型的标签信息,通过回车键可以添加多个标签,后续可以作为过滤条件进行查询。
说明:最多支持创建5个标签。
• *事件类型:配置原子事件模型的事件类型,此项为必填项,支持配置"原子事件"或"聚合事件",具体如下:
-原子事件:原子事件模型是事件模型中的基本构成单位,主要应用于机器数据异常检测场景。
-聚合事件:聚合事件是建立在原子事件之上的,对事件更高层次的表示。聚合事件模型是对原子事件数据的进一步分析,用于表达更复杂、更全面的事件关系,通常应用于异常事件的健康度计算、根因定位和告警降噪等场景。
• 备注:填写事件模型的其他属性信息。
说明:需≤255个字符。
不同事件类型的事件模型支持配置的数据源不同,具体如下:
› 原子事件模型支持配置“指标模型”、“数据视图”两种类型的数据源,对应的配置窗口如下所示:
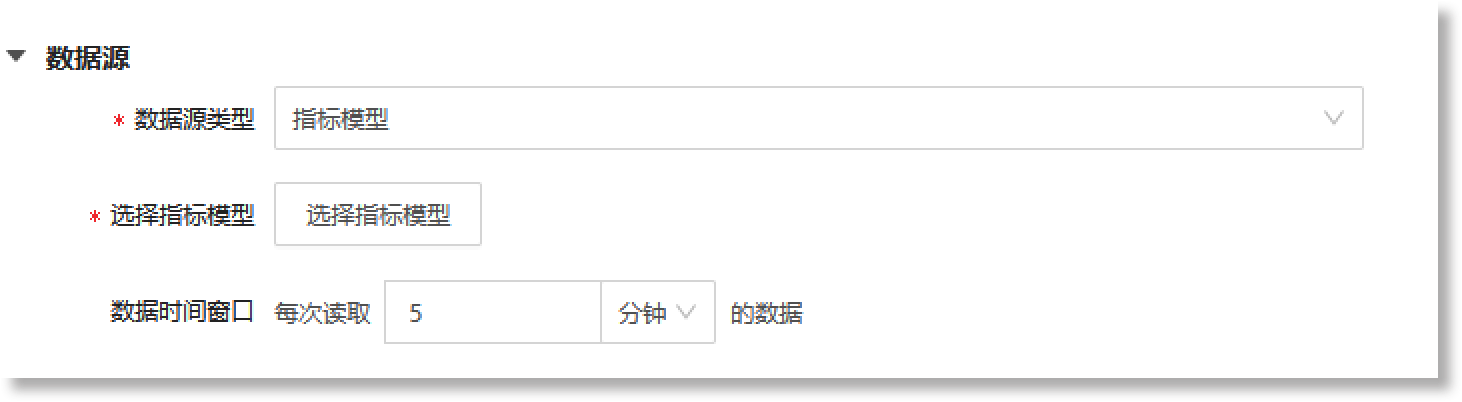
配置参数说明如下:
• *数据源类型:设置原子事件模型的数据来源类型,支持“指标模型”、“数据视图”,默认为“指标模型”。
• *数据来源:设置原子事件模型的数据来源,支持配置“指标模型”或“数据视图”:
-
- 当”*数据源类型“配置为“指标模型”时,点击【选择数据来源】选择所需指标模型作为数据来源,支持配置多个指标模型。抽屉列表中展示了系统已有的指标模型,点击“
 ”按钮可以查看此模型的配置信息,包括指标模型的计算公式信息。具体配置时,支持在列表上方通过添加筛选条件快速查询所需模型,也可以点击抽屉最下方的“新建指标模型”,创建符合需求的指标模型。
”按钮可以查看此模型的配置信息,包括指标模型的计算公式信息。具体配置时,支持在列表上方通过添加筛选条件快速查询所需模型,也可以点击抽屉最下方的“新建指标模型”,创建符合需求的指标模型。 - 当”*数据源类型“配置为“数据视图”时,点击【选择数据来源】勾选所需数据视图作为数据来源。抽屉列表中展示了系统已有的数据视图,点击“”按钮可以查看数据视图的备注、过滤条件、数据来源等配置信息。具体配置时,支持在列表上方通过添加筛选条件快速查询所需数据视图,也可以点击抽屉最下方的“新建数据视图”,创建符合需求的数据视图。
- 当”*数据源类型“配置为“指标模型”时,点击【选择数据来源】选择所需指标模型作为数据来源,支持配置多个指标模型。抽屉列表中展示了系统已有的指标模型,点击“
• 数据时间窗口:设置读取指标数据/数据视图的时间范围。此项为选填项,具体配置时需要在文本配置框中填写具体数值,并选择其时间单位,可选时间单位:分钟、小时、天。
需注意,数据来源配置为“数据视图”时,建议数据时间窗口配置在1小时以内,否则会产生性能问题。设置数据时间窗口时,需在文本框中输入正整数数字;当时间单位为“分钟”,最大输入数字为59;当时间单位为“小时”,最大输入数字为24;当时间单位为“天”,最大输入数字为1。
› 聚合事件模型是对原子事件数据的进一步分析,当前仅支持配置“原子事件模型”作为数据源,配置窗口如下所示:
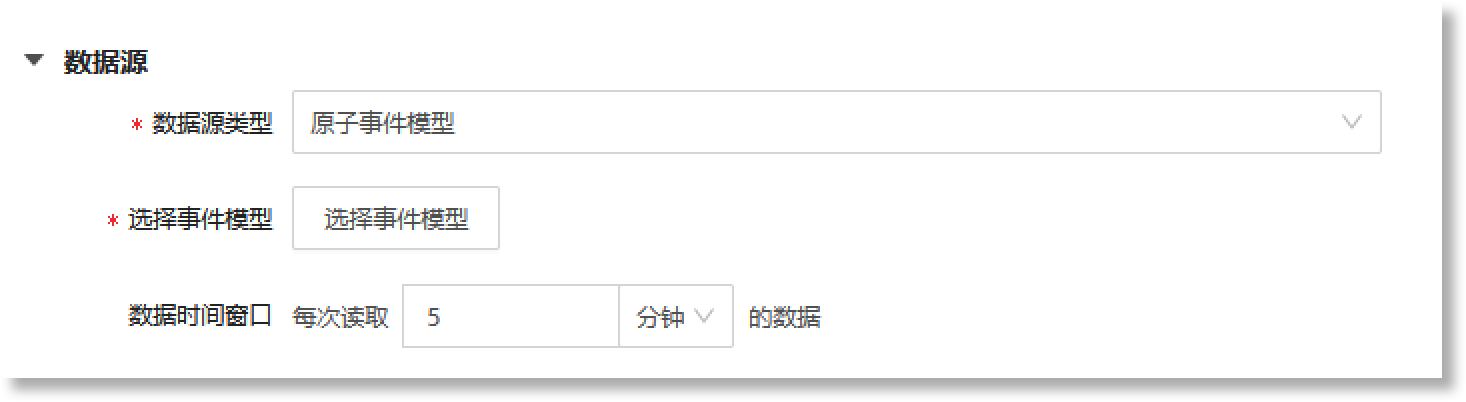
相关配置参数说明如下:
• *数据源类型:设置聚合事件模型的数据来源类型,默认为“原子事件模型”。
说明:聚合事件模型是基于原子事件数据更高层级的事件表示,因此,聚合事件模型当前仅支持配置“原子事件模型”类型的来源数据。
• *选择事件模型:选择聚合事件模型的来源原子事件数据,支持配置多个原子事件。点击【选择事件模型】按钮,在页面右侧的配置抽屉中选择所需事件模型。抽屉列表中展示了系统当前已创建的所有事件模型,您可以添加筛选条件快速筛选出所需的原子事件模型,也可以点击列表中事件模型前的“![]() ”按钮,查看事件模型的详情信息后,再进行选择。
”按钮,查看事件模型的详情信息后,再进行选择。
说明:若找不到所需事件模型,也可点击抽屉最下方的跳转链接,创建符合需求的事件模型。
• 数据时间窗口:根据实际数据需求,设置读取原子事件数据的时间范围。点击文本配置框,在文本框中填写具体数值,并选择时间单位,可选单位:分钟、小时、天。
说明:设置数据时间窗口时,需在文本框中输入正整数数字;当时间单位为“分钟”,最大输入数字为59;当时间单位为“小时”,最大输入数字为24;当时间单位为“天”,最大输入数字为1。
原子事件模型支持阈值检测、状态检测两种检测规则;聚合事件模型支持健康度计算、分组聚合两种聚合规则,具体如下:
› 配置原子事件模型的检测规则。阈值检测用于实现指标数据的检测(数据源为“指标模型”时),状态检测用于实现日志数据多字段的联合检测(数据源为“数据视图”时),具体如下:
当事件模型的“*事件类型”为“原子事件”,且”*数据源类型“为“指标模型”时,事件模型的”*检测类型”支持配置为“阈值检测”。"检测规则"的配置窗口如下所示:
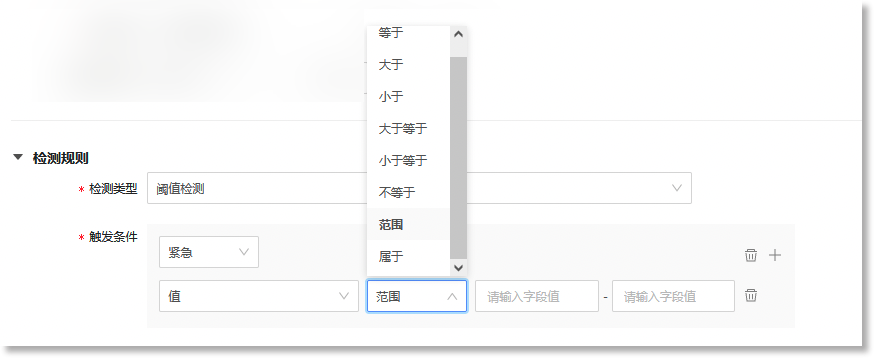
阈值检测“*触发条件”即事件模型基于来源指标数据生成原子事件数据的规则。当来源指标数据命中下方配置的检测规则时,事件模型将生成格式统一的事件数据。阈值检测规则可配置的触发条件包括:触发字段、操作符、目标值/目标区间、事件等级,具体如下:
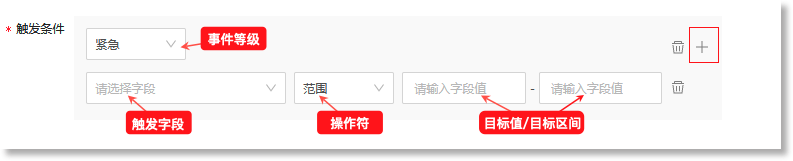
• 触发字段:数据源中触发事件的具体字段。数据来源为“指标模型”时,触发字段为来源指标数据中的“值”字段;
• 操作符:定义触发字段与目标值之间的关系。可配置的操作符包括:等于、大于、小于、大于等于、小于等于、不等于、范围、属于;
• 目标值/目标区间:命中检测规则时,触发字段值的目标数值或所在数值范围。若操作符为“范围”,则“触发值”需配置为一个值区间。若操作符为“属于”,则可以添加多个目标数值;
• 事件等级:设置命中上述触发条件后此事件对应的事件等级。可配置的等级包括:紧急、主要、次要、警告、不明确、清除,具体如下:
-
- 紧急:表示导致系统服务不可用的事件,如设备或资源完全不可用。针对此等级的事件,您需要立即采取恢复动作。
- 主要:表示影响系统服务质量的事件,如设备或资源处于可用状态,但系统提供的服务质量已有严重下降的趋势。针对此等级的事件,您需要采取紧急补救动作。
- 次要:表示可能影响服务质量的事件。您需要持续观测此等级的事件,并在适当时间进行排查处理,否则此类事件存有严重影响服务质量的风险。
- 警告:表示存在潜在影响服务质量的事件。针对此等级的事件,您需要保持观察并根据具体的错误采取不同的处理措施。
- 不明确:表示暂时不能明确事件级别的事件。针对此等级的事件,您需要根据具体环境进行具体判定。
- 清除:表示异常已被清除,前序状态为异常当前恢复为正常状态的事件(判定为同一事件的标准:事件模型ID相同且Label相同)。
添加多个触发条件:同一检测规则支持配置多个触发条件。点击上图红框所示的“![]() ”按钮,可以添加多个不同等级的触发条件。
”按钮,可以添加多个不同等级的触发条件。
注意:最多支持添加6条触发条件,且不支持配置重复事件等级的触发条件。
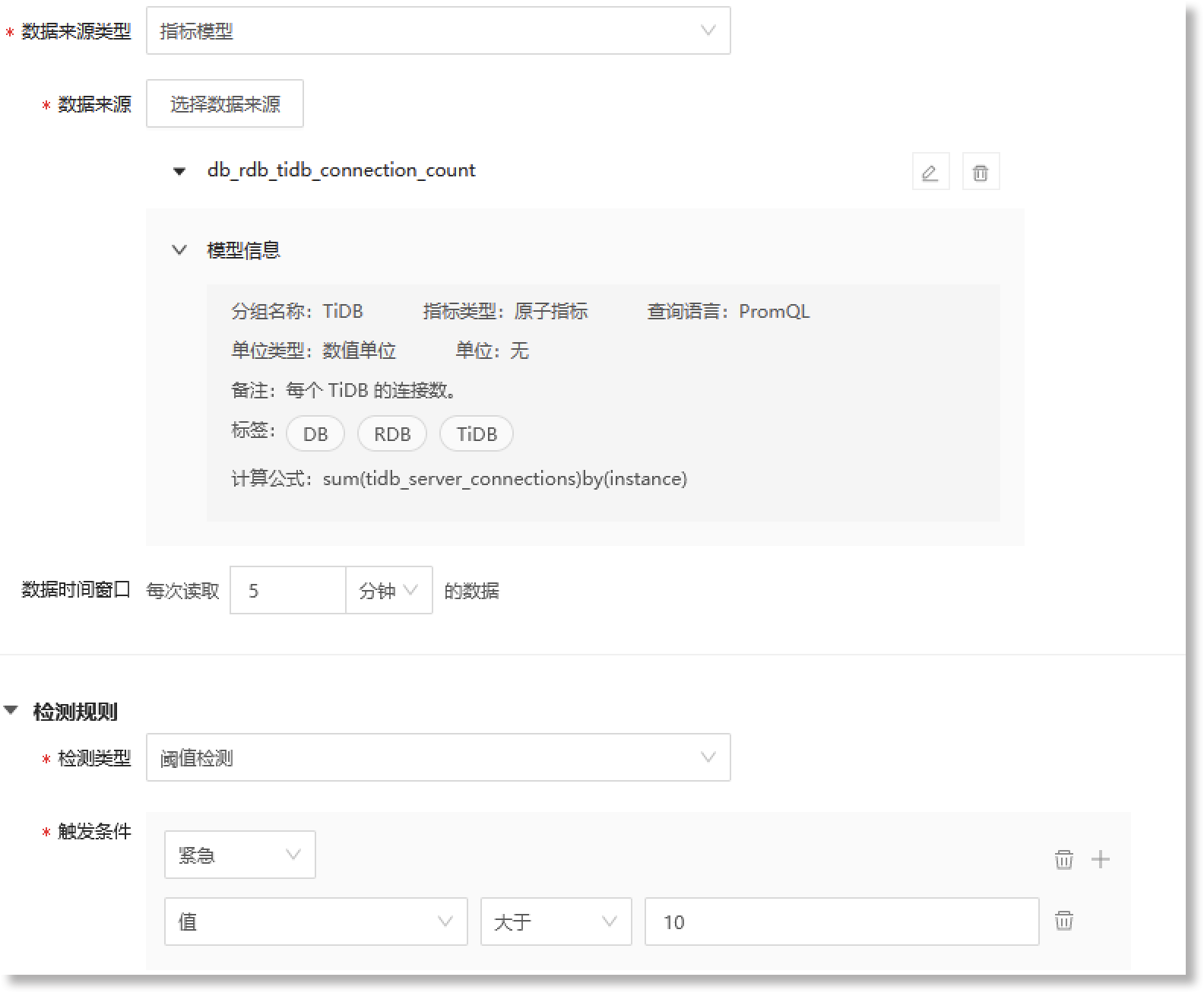
完成触发条件的配置后,您可以在 数据预览 中查看事件模型对应的事件内容描述信息。如下图所示的检测规则:事件模型数据源选择指标数据(每个TiDB连接数),当事件模型检测到来源指标数据中的连接数的值大于“10”时,将被判定等级为“紧急”的异常事件。
当事件模型的“*事件类型”为“原子事件”,且”*数据源类型“为“数据视图”时,事件模型的”*检测类型”支持配置为“状态检测”。"检测规则"的配置窗口如下所示:
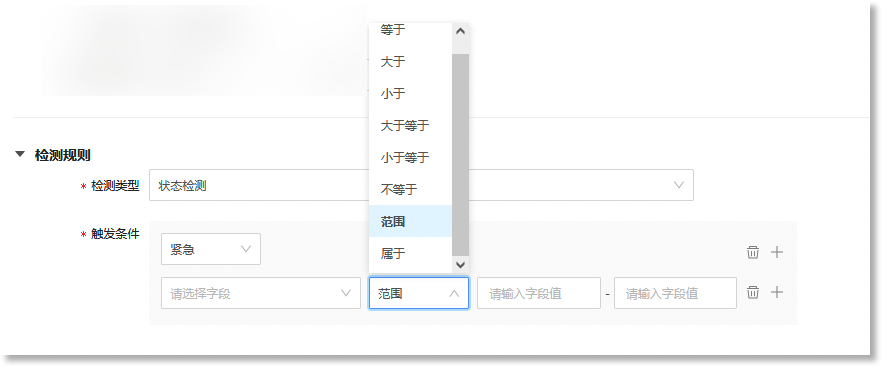
状态检测“的*触发条件”即事件模型基于来源日志数据(数据视图)生成原子事件数据的规则。当来源日志数据命中下方配置的检测规则时,事件模型将生成格式统一的事件数据。状态检测可配置的触发条件包括:触发字段、操作符、目标值/目标区间、事件等级,具体如下:
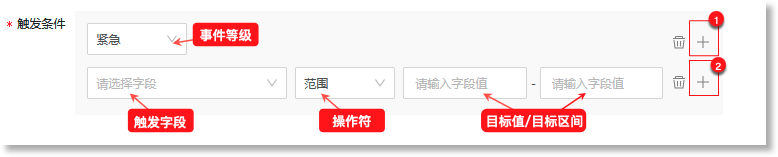
• 触发字段:数据源中触发事件的具体字段。数据来源为“数据视图”时,触发字段为来源数据视图中的指定字段;
• 操作符:定义触发字段与目标值之间的关系。可配置的操作符包括:等于、大于、小于、大于等于、小于等于、不等于、范围、属于;
注意:不同类型的字段支持配置的操作符不同。例如:
-
- date类型的字段支持“范围”操作符;
- text、keyword类型的字段支持“等于、包含、不包含、属于”操作符;
- double类型的字段支持“等于、大于、小于、大于等于、小于等于、不等于、范围、属于”操作符。
• 目标值/目标区间:命中检测规则时,触发字段值的目标数值或所在数值范围。若操作符为“范围”,则“触发值”需配置为一个值区间。若操作符为“属于”,则可以添加多个目标值;
• 事件等级:设置命中上述触发条件后此事件对应的事件等级。可配置的等级包括:紧急、主要、次要、警告、不明确、清除,具体如下:
-
- 紧急:表示导致系统服务不可用的事件,如设备或资源完全不可用。针对此等级的事件,您需要立即采取恢复动作。
- 主要:表示影响系统服务质量的事件,如设备或资源处于可用状态,但系统提供的服务质量已有严重下降的趋势。针对此等级的事件,您需要采取紧急补救动作。
- 次要:表示可能影响服务质量的事件。您需要持续观测此等级的事件,并在适当时间进行排查处理,否则此类事件存有严重影响服务质量的风险。
- 警告:表示存在潜在影响服务质量的事件。针对此等级的事件,您需要保持观察并根据具体的错误采取不同的处理措施。
- 不明确:表示暂时不能明确事件级别的事件。针对此等级的事件,您需要根据具体环境进行具体判定。
- 清除:表示异常已被清除,前序状态为异常当前恢复为正常状态的事件(来源数据为数据视图时,因数据视图无Label字段,判定为同一事件数据的标准仅考虑所属事件模型ID是否相同)。
添加多个触发条件:同一检测规则支持配置多个触发条件。点击上图①号红框中的“![]() ”按钮,可以添加不同等级的事件触发条件。
”按钮,可以添加不同等级的事件触发条件。
注意:最多支持添加6条触发条件,且不支持配置重复事件等级的触发条件。
支持多规则联合检测:点击上图②号红框中的“![]() ”按钮,可以配置针对不同字段的多条检测规则,多条检测规则之间支持配置“且”与“或”的逻辑运算关系(点击下图左侧红框中的“且”/“或”按钮即可切换逻辑关系)。如下所示:
”按钮,可以配置针对不同字段的多条检测规则,多条检测规则之间支持配置“且”与“或”的逻辑运算关系(点击下图左侧红框中的“且”/“或”按钮即可切换逻辑关系)。如下所示:
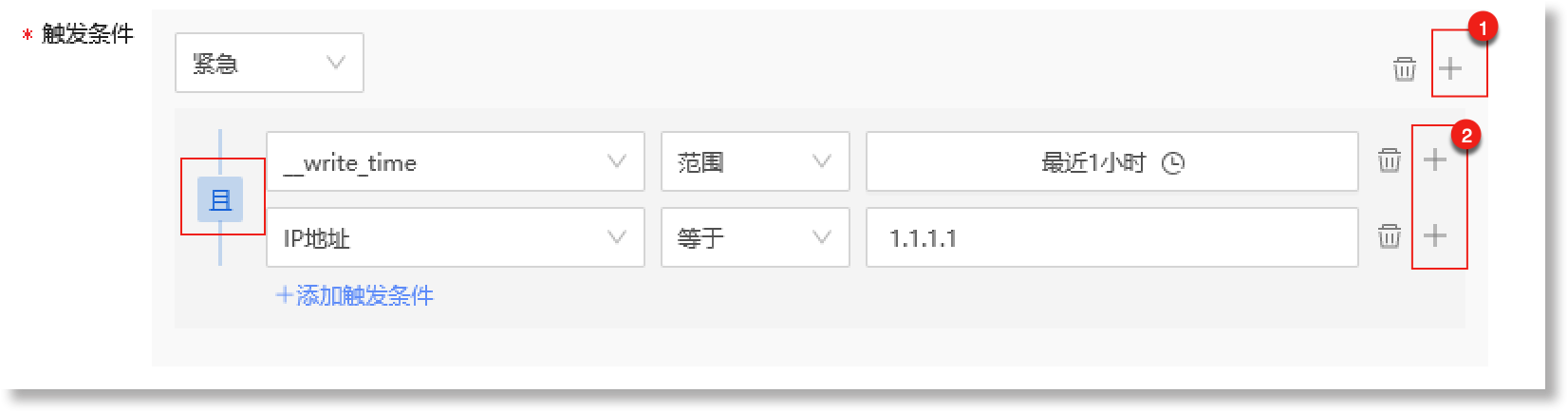
完成触发条件的配置后,您可以在 数据预览 中查看事件模型对应的事件内容描述信息。如上图所示的状态检测规则中,事件模型数据源选择数据视图(ar_audit_log),当事件模型检测到数据视图中的“IP地址”字段值等于“1.1.1.1”且“__write_time”字段值在“最近1小时”的范围内时,此事件将被判定等级为“紧急”的异常事件。
针对“聚合事件”类型的事件模型,支持配置"健康度计算"、"分组聚合"两种类型的聚合规则,适用场景如下:
- 健康度计算:聚合事件模型将基于内置聚合算法评估异常事件的严重等级、健康分数。后续在基于此类数据的分析应用中,帮助从全局视角了解监控对象的健康状态,优先处理最严重的异常事件。具体应用可参考 全景图 > 创建全景图 章节。
-分组聚合:聚合事件模型将对检测后的异常事件中若干字段进行分组处理,并归类生成异常事件消息。此类消息在后续的数据应用中将会嵌入到告警通知中,方便您在告警邮件中直接查看异常通知。
具体配置说明如下:
当"*聚合类型"配置为"健康度计算"时,"聚合规则"的配置界面如下所示:
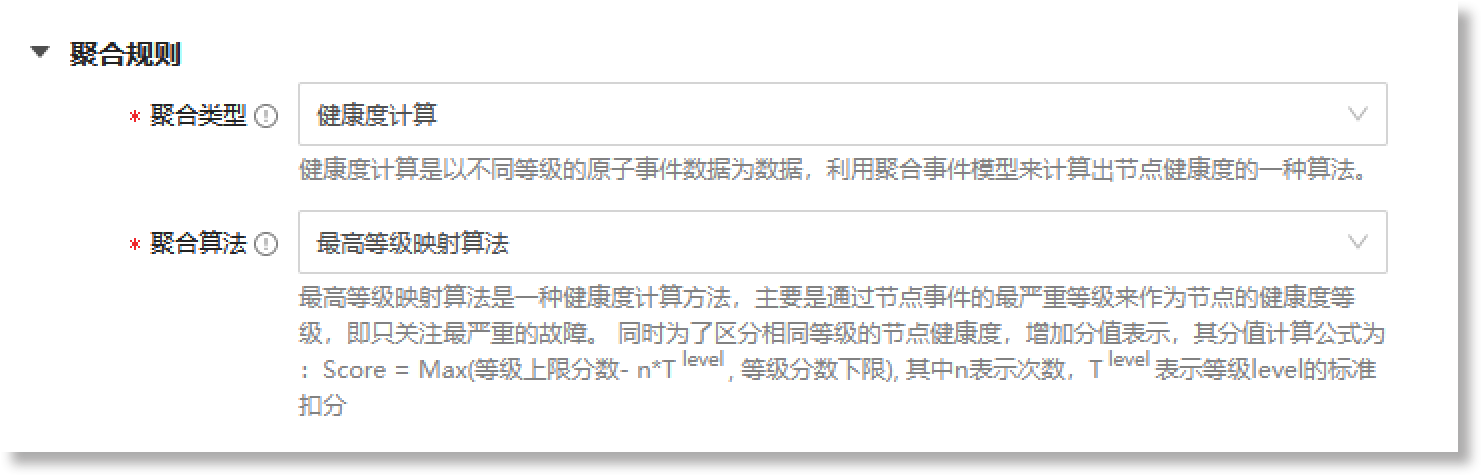
聚合事件模型的聚合规则默认采用"最高等级映射算法"。此算法是一种计算节点健康度的方法:基于不同等级的原子事件数据,将节点事件中最严重等级作为节点的健康度等级。同时,此算法也提供了用于计算健康度具体分值的计算公式(参见上图"聚合算法"提示信息),分值越低表示严重程度越高,基于此分值可以帮助区分处于同一健康度等级事件的严重性,优先处理最严重的异常事件。
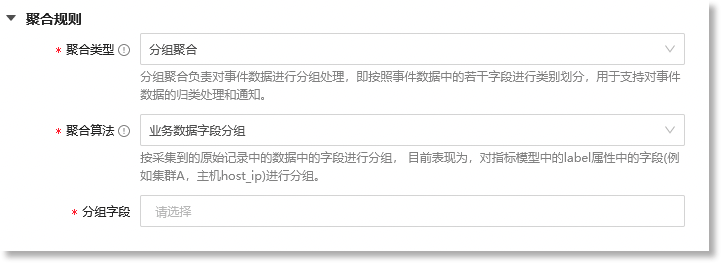
当"*聚合类型"配置为"分组聚合"时,"聚合规则"的配置界面如下所示:
| 配置参数 | 参数说明 |
| *聚合算法 |
选择分组聚合的数据来源,可选项:"业务数据字段分组"、"事件数据字段分组",具体如下: • 业务数据字段分组:按照原子事件数据中的业务字段进行分组。当前可以理解为,按照指标数据label属性(业务维度)中的字段进行分组,例如cluster,host_ip等字段; • 事件数据字段分组:按照原子事件数据本身的固定属性字段进行分组。当前可以理解为,按照事件数据中的title,type,level,event_model_id,event_model_name字段进行分组。 |
| *分组字段 |
配置具体的分组字段,具体如下: • 当聚合算法选择"业务数据字段分组"时,可以选择的分组字段为原子事件数据中的业务字段,即指标数据label属性中的字段,例如cluster,host_ip等字段; • 当聚合算法选择"事件数据字段分组"时,可以选择的分组字段为原子事件数据本身的固定属性字段,即事件数据中的title,type,level,event_model_id,event_model_name字段。 |
完成分组聚合后,分组后每个组别内事件数据的事件等级将由该组内严重性等级最高的事件等级决定,即严重等级最高的事件等级将作为该组的事件等级。
事件模型的数据持久化是指将事件模型定义的事件数据存储到AnyRobot的指定索引库中,以确保事件数据及其状态的长期存储,进而提升系统性能,为事件数据在复杂场景的查询、可视化、告警等应用提供高性能支持。
AnyRobot提供了默认的事件模型持久化任务参数,在创建事件模型时,您可以选择直接采用默认持久化任务参数,或根据实际需求自定义持久化任务参数。
需注意:事件模型创建完成后,其持久化任务将默认处于关闭状态,您需要进入事件模型管理列表开启对应的持久化任务,否则此模型将默认不进行数据持久化,具体操作请参见 启用/关闭持久化任务。另外,事件模型管理列表也提供了针对持久化任务配置及任务运行状态的监控信息,具体操作请参见 查看持久化任务状态。
进入事件模型配置页面的“持久化配置”区域,系统提供了持久化默认配置参数,包括持久化任务的默认执行频率、持久化数据的默认存储索引库等,如下所示:
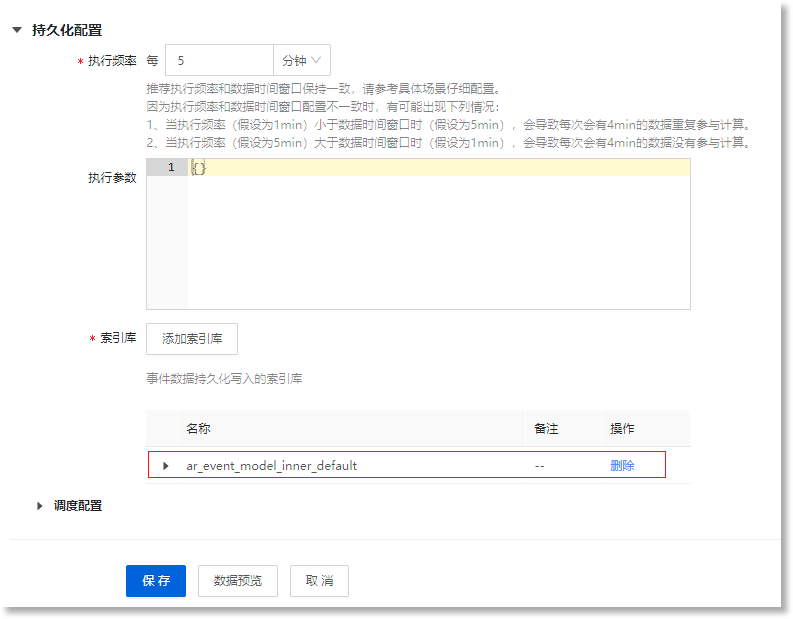
若无特殊配置需求,您可直接使用默认的持久化参数,点击最下方的【保存】按钮,快速创建事件模型。
您也可以根据实际需求,自行定义持久化任务参数,配置参数说明如下:
• *执行频率:设置持久化任务的运行时间间隔,默认为每“5”分钟。点击文本配置框,填写或点击“![]() ”按钮配置具体时间数值,并选择其时间单位,可选单位:分钟、小时、天。例如:当执行频率设置为“每5分钟”,则此事件模型将每隔5分钟执行一次持久化任务。
”按钮配置具体时间数值,并选择其时间单位,可选单位:分钟、小时、天。例如:当执行频率设置为“每5分钟”,则此事件模型将每隔5分钟执行一次持久化任务。
说明:执行频率不能为空,且必须为正整数数字。配置时,建议执行频率与数据时间窗口配置的时间参数相等,以保证数据的一致性。具体配置时,您可以参照下文说明,并结合实际数据需求进行配置:
-
- 当执行频率=时间窗口时,表示每次执行持久化任务都可以涵盖一个完整的时间窗口,能够确保数据的完整性和一致性;
- 当执行频率>时间窗口时,表示每次执行持久化任务超过一个完整的时间窗口,相隔持久化任务之间数据重叠,可能会造成资源浪费;
- 当执行频率<时间窗口时,表示每次执行持久化任务不足一个完整的时间窗口,相隔持久化任务之间数据覆盖不全,可能会造成重要数据遗漏。
• 执行参数:根据实际需求配置任务执行参数,事件检测规则或聚合规则中的算法可以基于此处配置的算法参数或自适应参数执行特定逻辑,用于调整算法效果。
• *索引库:AnyRobot提供了默认的写入索引(上图红框所示),方便您直接勾选引用;若您对持久化数据有分类管理的需求,可以点击【添加索引库】,在右侧弹出的“添加索引库”抽屉中,勾选用于存储此事件模型持久化数据的指定索引库。若列表中没有所需索引库,需要点击下方“新建索引库”进行创建。
说明:索引库不能为空。
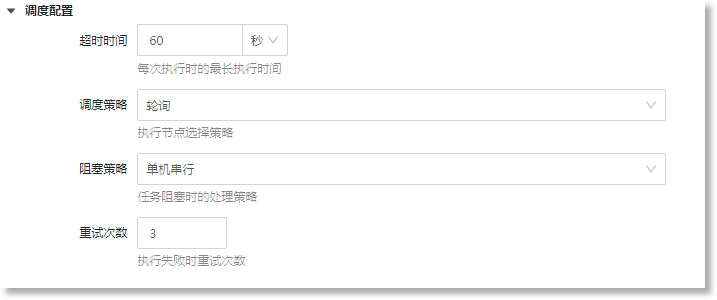
• 调度配置:
点击"![]() ",打开"调度配置"收折页面,配置持久化任务调度参数(可选):
",打开"调度配置"收折页面,配置持久化任务调度参数(可选):
| 配置参数 | 参数说明 | 限制条件 |
| 超时时间 |
设置每次执行持久化任务的最长时间,默认为60秒。如果任务在规定的超时时间内未完成,系统将中断此持久化任务。点击文本框,填写或点击“ |
• 仅支持选择时间单位为“秒”,文本框中需填写≥0,且≤60的正整数 |
| 调度策略 |
调度策略定义了执行节点的选择策略,默认策略为“轮询”,可配置策略的具体含义如下: • 最后一个:表示选择最后一个注册的执行节点。适用于需要最新配置的任务场景; • 轮询:表示按照执行节点的注册顺序,依次选择执行节点。适用于执行节点之间没有性能差异的场景; • 随机一致性HASH:表示使用一致性哈希算法随机选择执行节点。适用于集群中存有多个执行器,并希望任务能够均匀分布在各执行节点的场景; • 使用频率最低优先:表示选择使用频率最低的执行节点。适用于需要较长执行时间的任务场景; • 最久未使用优先:表示选择最久未被使用的执行节点。适用于平衡执行节点资源使用的场景,避免某个执行器长时间得不到使用; • 故障转移:表示在节点故障时选择备用的执行节点。适用于执行节点可能会发生故障的场景,配置为"故障转移"策略后 ,任务能够在备用的执行节点继续执行; • 忙碌转移:表示在节点繁忙时选择备用的执行节点。适用于任务执行节点可能会处于高负载状态的场景,配置为"忙碌转移"策略后,任务将被分配在备用的执行节点执行; • 分片广播:表示将任务广播到所有分片。适用于需要任务并行执行的场景,当此类任务可以进行分片处理时,可以使用该策略提高任务执行效率。 |
- |
| 阻塞策略 |
阻塞策略定义了持久化任务在阻塞时的处理策略,默认策略为“单机串行”,可配置策略的具体含义如下: • 单机串行:表示当任务阻塞时,新的调度任务将等待当前任务执行完毕后再进行。适用于任务之间存在依赖关系的场景; • 丢弃后续调度:表示当任务阻塞时,新的调度任务将会被丢弃,并标记为失败,不等待当前任务完成。适用于耗时较长的任务,避免等待时间过长,提高整体调度效率; • 覆盖之前调度:当任务阻塞时,新的调度任务将会覆盖当前的任务,保留最新的调度任务。适用于更新频率较高的任务,确保任务及时更新,避免过时的任务仍在被执行。 |
- |
| 重试次数 |
重试次数定义了任务在执行时允许的最大重试次数,通过任务重试增加任务成功的机会。 |
- |
完成上述配置后,您可以点击配置窗口下方的【数据预览】按钮,预览基于当前配置参数生成的事件数据内容,便于及时根据需求调整事件模型配置参数。操作流程如下所示:
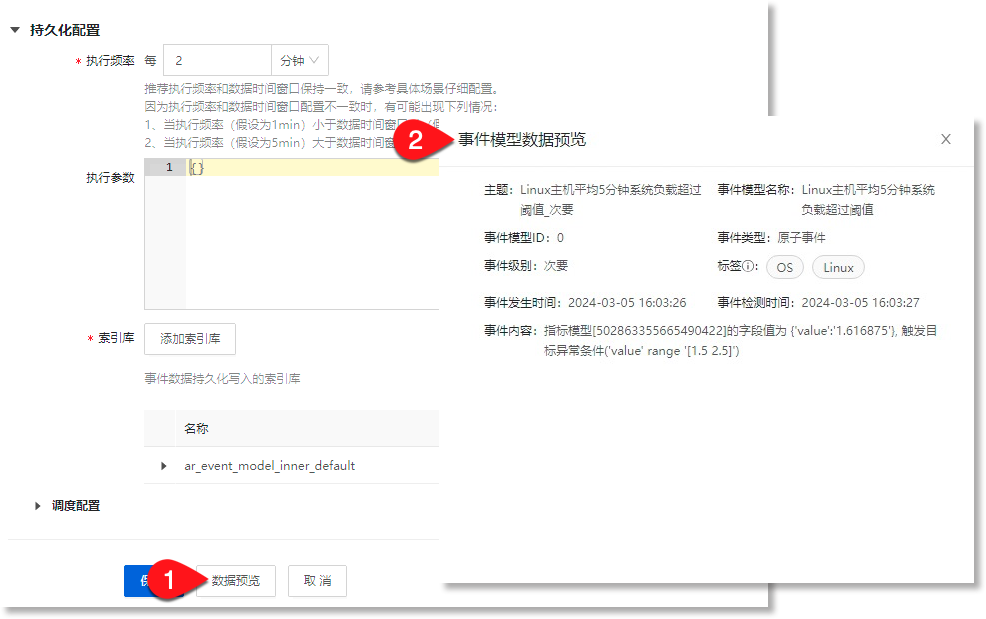
完成上述配置后,点击【保存】按钮即可完成事件模型的创建操作。
除了手动配置,您也可以基于事件模型的导入功能批量创建事件模型。进入事件模型配置页面,点击列表上方的【导入】按钮,在弹出的窗口中选中包含事件模型配置信息的文件,点击【打开】后即可批量导入并创建事件模型。
注意:
1. 仅支持导入json格式的文件;
2. 支持同时导入多个事件模型:
导入原子事件模型时,若原子事件模型绑定的指标模型不存在,则导入操作失败;
导入聚合事件模型时,若聚合事件绑定的原子事件不存在,则导入操作失败。您需完成模型绑定的数据来源创建后,再进行导入操作。
同时导入原子事件模型及聚合事件模型时,若任一原子事件模型导入失败,则导入操作失败;若原子事件模型全部导入成功,引用此原子事件模型的聚合事件模型导入失败,则已导入的原子事件不会被删除。进行二次导入时,需要删除已导入的原子事件模型后,才能成功导入。
3. 导入时,若系统中存有重名的事件模型对象,则导入动作将停止,导入失败;
4.导入时,系统会保留持久化任务的原有开启/关闭状态;若导入的事件模型持久化任务参数为空,系统将自动为其添加默认的持久化任务参数,并将默认任务处于关闭状态。
5. 导入失败后,您可在审计日志中查看对应的“失败”记录。
事件模型成功创建后,您可以在AnyRobot数据应用模块直接引用事件数据资源,进一步对模型定义的事件数据进行多维度可视化分析,实现对异常事件的监控及异常告警。详情请参见 事件模型应用 章节。