完成数据字典的配置后,您可以在数据解析模块直接使用键值型数据字典中已预置的数据映射关系,将解析后的日志数据与数据库中的业务数据进行关联整合,构建更丰富的数据基础;您也可以进入指标模型管理模块,基于指标模型PromQl查询语言的dict_labels及dict_values算子编写计算公式,利用维度型数据字典扩充指标序列,或将此维度型数据字典转化为可用于指标计算的指标。具体如下:
下文具体介绍如何使用键值型数据字典,将数据库中的数据添加到日志数据中的操作步骤:
进入AnyRobot 数据源>远程采集>数据库连接页面,点击【新建】按钮,进行连接AnyRobot数据库的相关配置操作。如下所示:
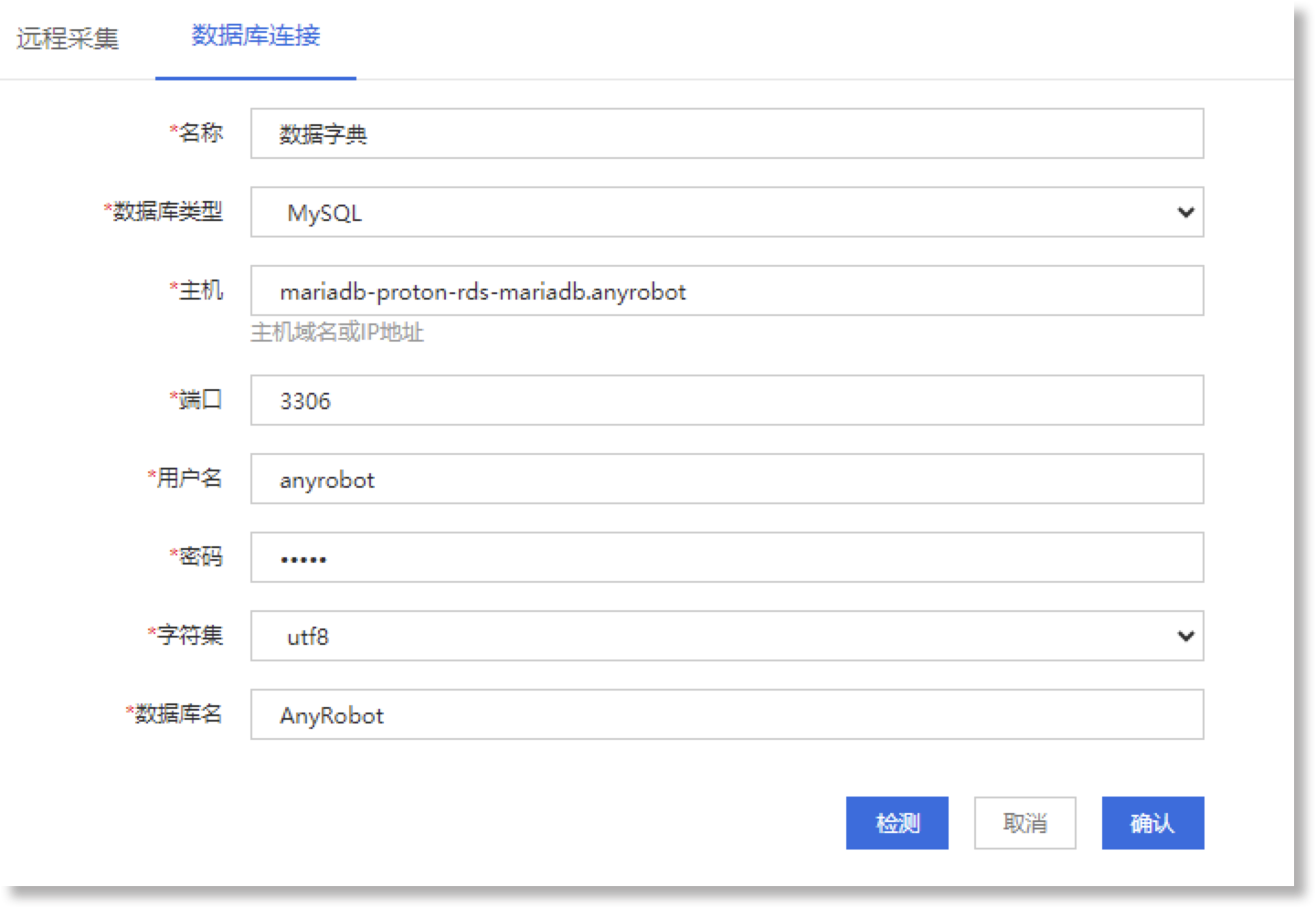
| 元素名称 | 元素说明 |
| *名称 | 设置数据库连接的名称。例如:数据字典 |
| *类型 | 选择AnyRobot数据库的类型。例如:MySQL |
| *主机 |
设置AnyRobot数据库的主机域名或IP地址。例如:mariadb-proton-rds-mariadb.anyrobot |
| *端口 |
设置AnyRobot数据库连接的端口。例如:3306(MySQL数据库的默认端口) |
| *用户名 |
设置AnyRobot MySQL数据库的登陆用户名。 提示:请联系 AnyRobot 管理员获取登录用户名信息 |
| *密码 |
设置AnyRobot数据库的登陆密码。 提示:请联系 AnyRobot 管理员获取登陆密码信息 |
| *字符集 |
设置数据库类型对应的字符集。例如:utf8 |
| *数据库名 |
设置数据库名称。例如:AnyRobot |
_61.png) 说明:上方以连接AnyRobot自身数据库为例进行了相应配置参数的示意,此场景下您可直接参考上方参数配置数据库连接,但具体配置参数仍需以实际场景需求为准。
说明:上方以连接AnyRobot自身数据库为例进行了相应配置参数的示意,此场景下您可直接参考上方参数配置数据库连接,但具体配置参数仍需以实际场景需求为准。
1)配置解析规则,解析日志数据
进入AnyRobot 数据管理>数据存储>解析规则页面,点击【新建】按钮,在配置页面中设置解析规则名称,添加筛选条件,对原始日志进行JSON解析。如下所示:
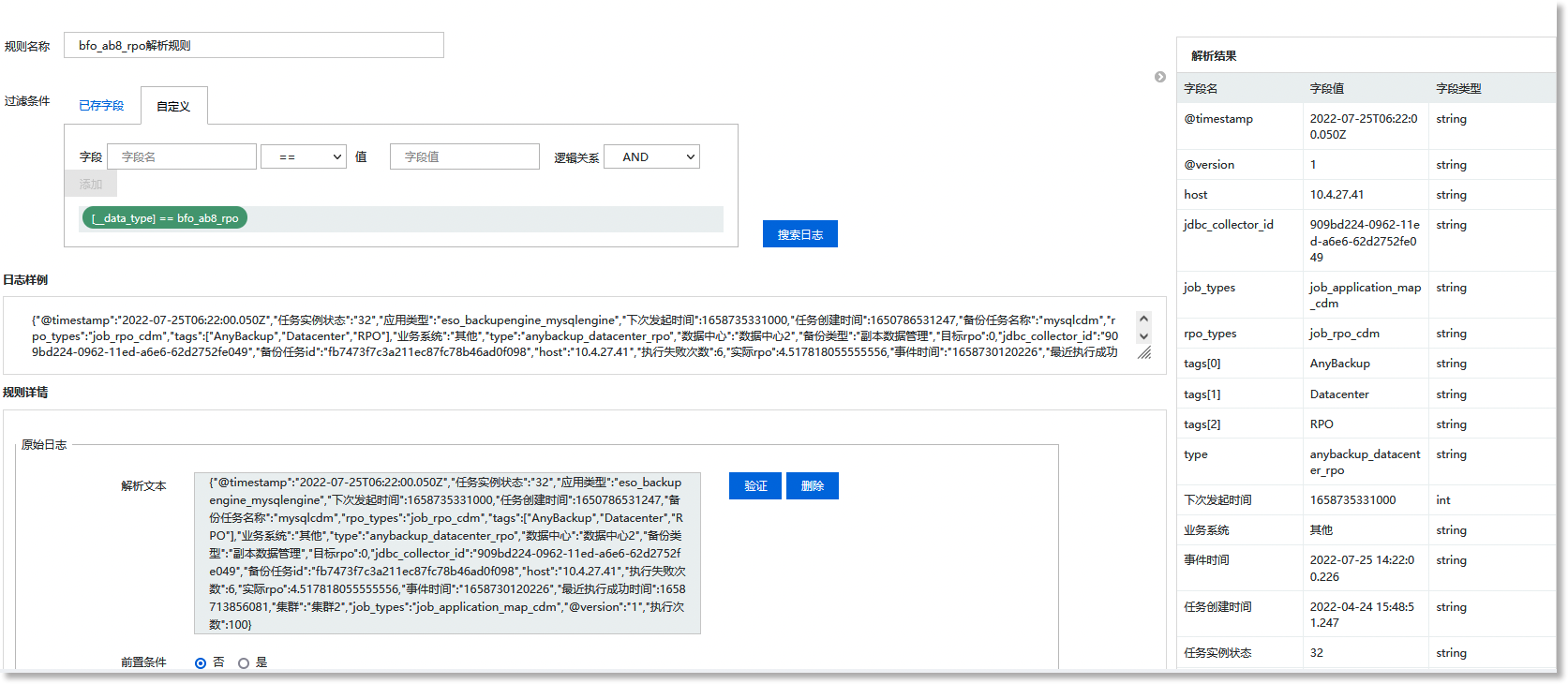
注意:完成解析规则的配置后,基于原始日志的解析结果将展示在页面右侧,如上图所示。
2)远程查询数据库,获取数据库数据
点击【添加数据库数据】按钮,在展开的表单中配置远程查询参数,以使用数据字典获取数据库中的指定数据集,并缓存至本地。如下所示:
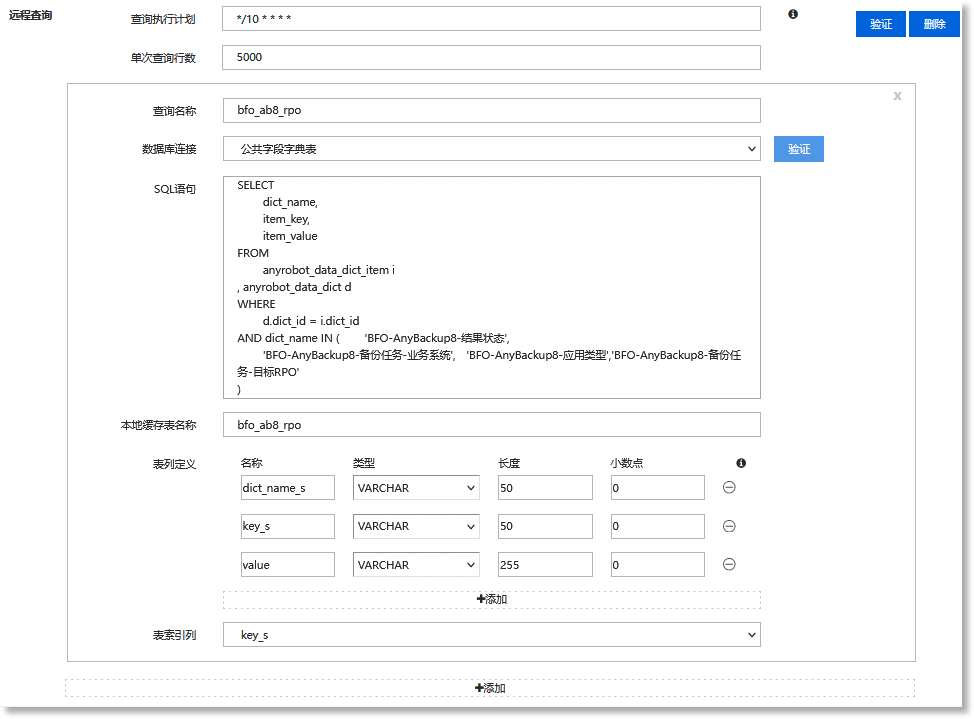
| 元素名称 | 元素说明 |
| 查询执行计划 |
根据实际业务需求设置远程查询的执行周期,将鼠标移至“ |
| 单次查询行数 |
根据实际业务需求设置单次查询行数,建议大于数据字典的实际记录数,否则查询结果中将出现异常信息。 例如:数据字典表最大允许有 1000 条记录,则行数可以设置为 5000 |
| 查询名称 |
自定义远程查询名称。 注意:远程查询名称不允许与其他参数重名 |
| 数据库连接 |
在下拉框中选择已创建的数据库,并进行连接验证。 |
| SQL 语句 |
自定义远程查询的 SQL 语句,用于获取数据库中的表数据。 注意:SQL语句基本格式要求:“select<需要返回的字段> from<需要查询的表名> where <查询条件>”。如上图所示,WHERE语句中的dict_name IN后,应填写要使用的数据字典名称。 |
| 本地缓存表名称 |
自定义本地缓存表的名称,即“bfo_ab8_rpo”,用于存放此查询操作从数据库获取到的数据集。 注意:本地缓存表名称不允许与其他参数重名 |
|
表列定义 |
定义本地缓存表中的列名称、类型和长度等信息。 注意:本地缓存表中的列必须与 SQL 查询返回结果的列在顺序上保持一致,名称可以自定义,具体如下: •名称:表列名称必须根据 SQL 返回结果中的列顺序进行依次定义,即依次定义 dict_name_s 、key_s、value 三列的列名称; •类型:字段数据类型必须与数据字典表中的类型保持一致,即 VARCHAR; •长度:字段长度并不能为 0 ,若填写 0 会导致系统异常 |
|
表索引列 |
定义本地缓存表中的索引列,即“key_s”。 |
完成配置后,系统将基于配置的 SQL 语句从数据库中查询并获取数据,获取到的数据集将存放于本地缓存表(即名为“bfo_ab8_rpov”的缓存表)中。
进入关联日志配置区域,配置所需的目标字段,定义查询条件获取所需数据集作为目标字段的字段值。如下所示:
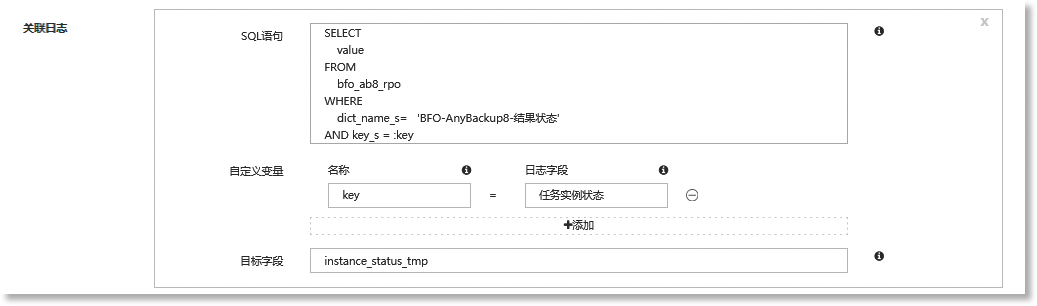
|
元素名称
|
元素说明
|
|
SQL 语句 |
用于查询并提取本地缓存数据表中的缓存数据,并将其添加到当前的日志数据中。 注意:当 SQL 语句中需添加自定义变量时,需在自定义变量前加上冒号":"。以上图为例," key_s "作为自定义变量,对应的 SQL 语句为" WHERE key_s=:key "。 |
|
自定义变量 |
定义SQL语句中自定义变量对应的日志中已解析字段。完成配置后,解析规则将使用此处配置的日志字段(“任务实例状态”)的值替换SQL语句中的自定义变量(“key”),例如:在上图所示的关联日志配置中,选取日志中已解析出的日志字段【任务实例状态】代替自定义变量,日志字段对应的字段值将作为查询条件,用于查询需新增/替换(具体修改方法以步骤4)为准)到日志数据中的数据。 注意: • 支持将多个日志字段进行拼接,拼接字段中间的连接符可根据实际情况修改,若无连接符则无需填写; • 数据字典的“键”或者“维度键”应与解析后的日志字段的值对应,而字典对应的“值”或者“维度属性”应配置为需要替换的可读性较高的或者其他满足业务需求的数据; •日志字段若为多级字段,需参照"[a][b][c]"的格式进行填写,如:[china][shanghai][pudong]。 |
|
目标字段 |
目标字段为添加到日志数据中的新字段,目标字段的值为通过上述 SQL 语句在本地缓存表中查询到的数据集。 注意:目标字段名称不允许与其他参数重名。 |
完成配置后,系统将基于已配置的 SQL 语句从本地缓存表中查询并获取缓存数据,获取到的数据集即为自定义目标字段的值。
点击【修改字段】按钮,在修改方法的表单中配置修改关联日志的前置条件(仅当前置条件为“是”时,方可修改当前日志)、配置修改方法、定义需修改的字段名称及字段值。下图以替换解析后已提取的日志字段的值为例进行说明:
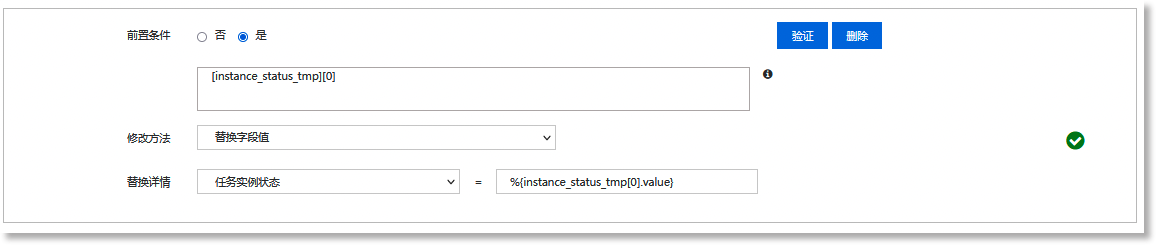
|
元素名称
|
元素说明
|
|
前置条件 |
前置条件位于每一层解析之前,为该层解析提供限制规则,用于解决同类日志数据中某些字段可能不存在的场景,此类场景中若进行全局解析可能会造成解析不准确的问题。 注意:执行前置条件验证前,需保证前置条件中的条件对象字段已完成解析提取。 |
|
修改方法 |
选择修改方法。例如:上图配置中采用“替换字段值”的方法,【任务实例状态】为需要替换掉的字段,“=”后文本框中的内容为需要替换成的字段值。替换后,已解析的日志数据中的【任务实例状态】字段的值将被替换为“instance_status_tmp[0].value”,即步骤3)提取的数据集中第一个元素对应的值。 注意: • "%{}"格式中需要填写要引用的具体字段名称,详细说明请参见 修改字段。 • 支持将多个日志字段进行拼接,拼接字段中间的连接符可根据实际情况修改,若无连接符则无需填写; • 数据字典的“键”或者“维度键”应与解析后的日志字段的值对应,而字典对应的“值”或者“维度属性”应配置为需要替换的可读性较高的或者其他满足业务需求的数据; • 日志字段若为多级字段,需参照"[a][b][c]"的格式进行填写,如:[china][shanghai][pudong]。 |
注意:执行前置条件验证前,需保证前置条件中的条件对象字段已完成解析提取。
配置完成且前置条件验证通过后,系统将根据已配置的修改方法将【任务实例状态】字段的值替换为【instance_status_tmp】字段值对应的数据集中第一个元素对应的值,如下所示。
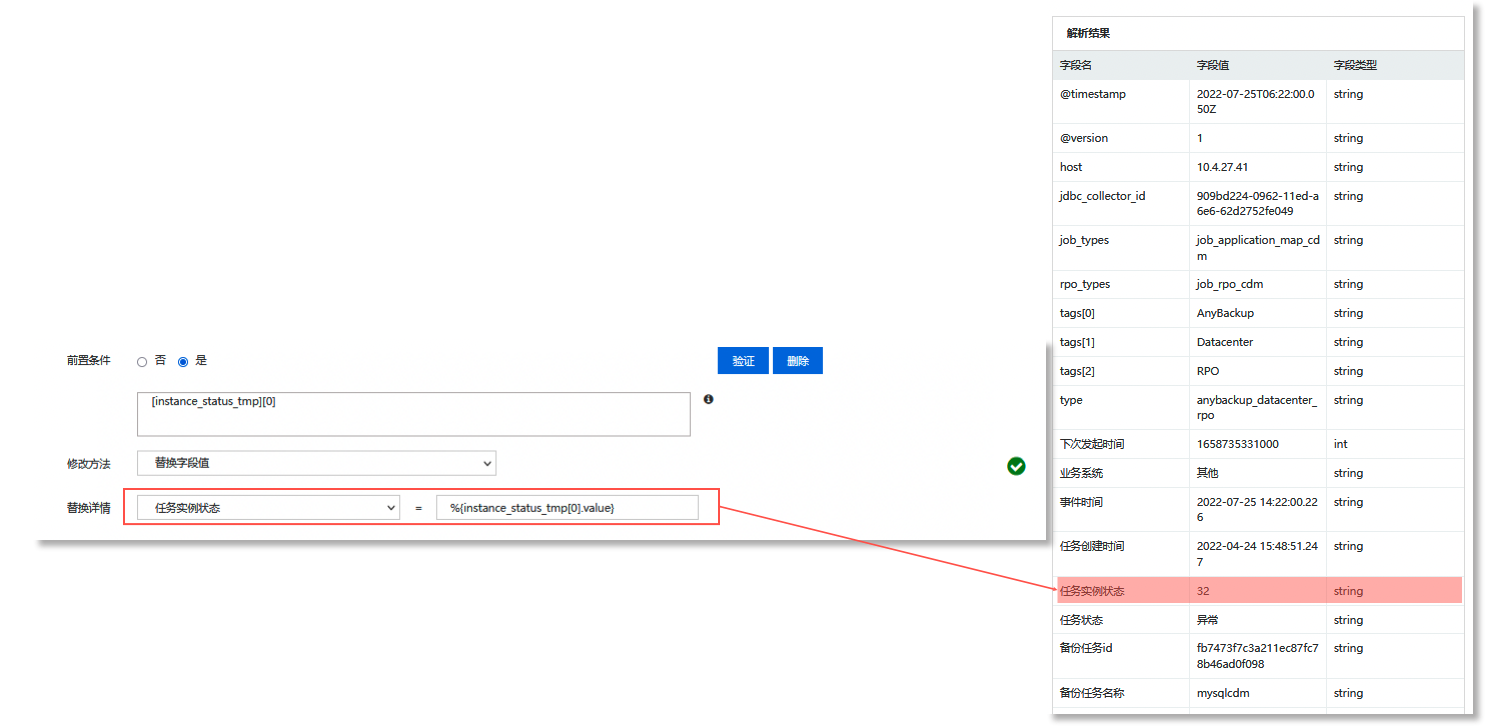
说明:上文与数据库连接、远程查询、关联日志、修改字段、前置条件相关的配置参数已在相关章节详述,此处不再赘述,详情请参考《 AnyRobot Family 产品使用指导》数据库连接、添加数据库数据、修改字段、前置条件 章节。
当前,AnyRobot维度字典主要应用在指标模型模块,利用指标模型PromQL查询语言中的dict_labels、dict_values算子,来扩充指标序列(应用场景一),或者将此维度字典转化为便于后续计算的指标(应用场景二)。具体如下:
应用场景一:下文以计算主机(host)CPU平均利用率的指标模型为例,介绍如何使用dict_labels算子,将维度字典中的app_id字段作为指标维度(label)添加到指标数据中,实现指标序列的扩充。
1)创建指标模型,用于计算指标-主机(host)CPU平均利用率
进入数据管理 > 数据模型 > 指标模型,创建指标模型,计算公式配置示例如下所示。公式中的host_avg_cpu为时间序列向量,代表了主机的 CPU 平均利用率这一指标。完成配置后,点击数据预览,预览基于此计算公式的指标数据。如下所示:
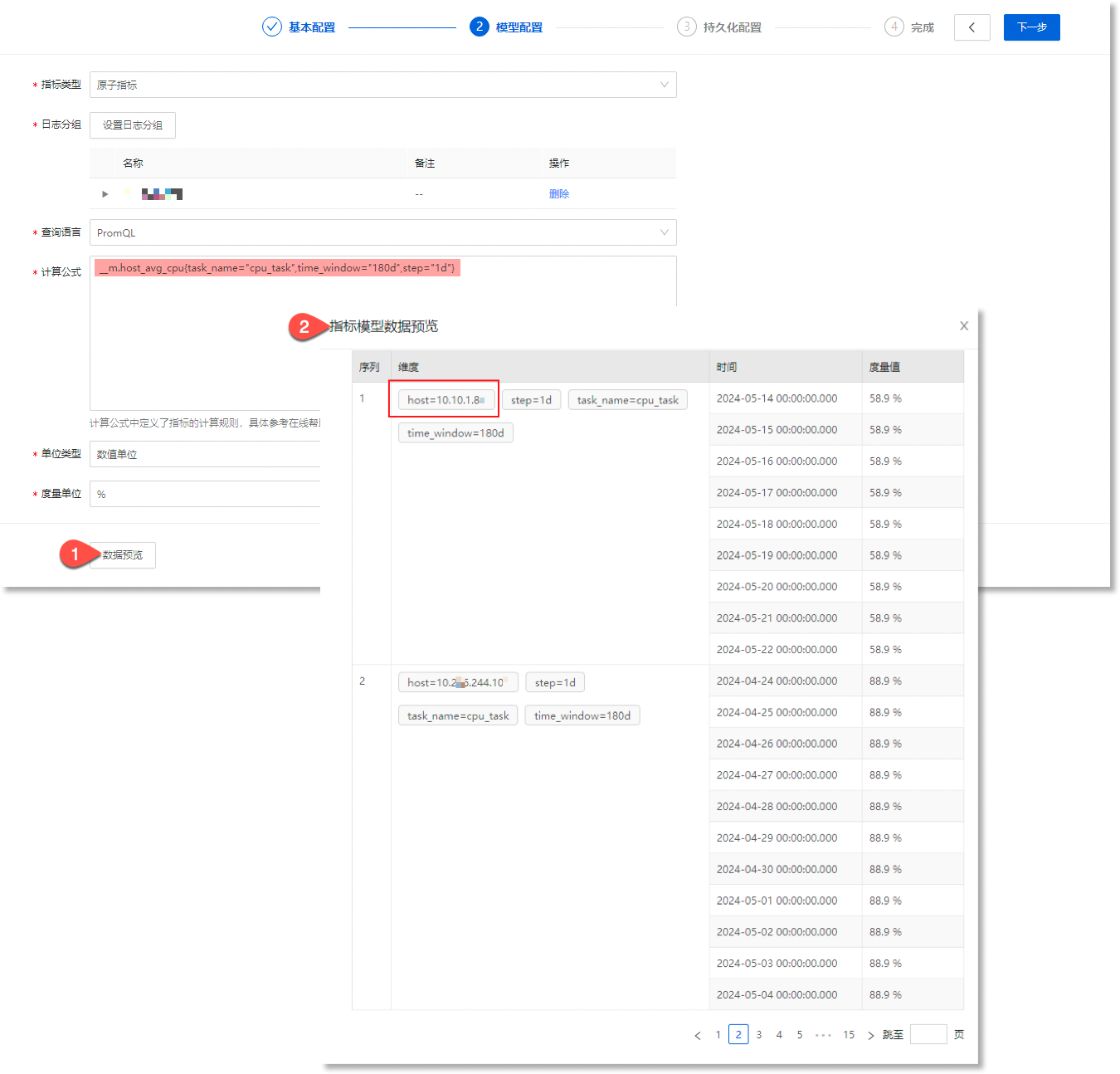
2)以上图指标数据中的“host=10.10.18”维度为例,创建所需维度字典
进入数据管理 > 数据模型 > 数据字典,新建/导入所需维度字典。“host”作为维度键名称,app_id作为维度属性名称,添加对应的维度键及维度属性。关于维度字典的数据字典及数据字典项的配置参数示例如下所示:
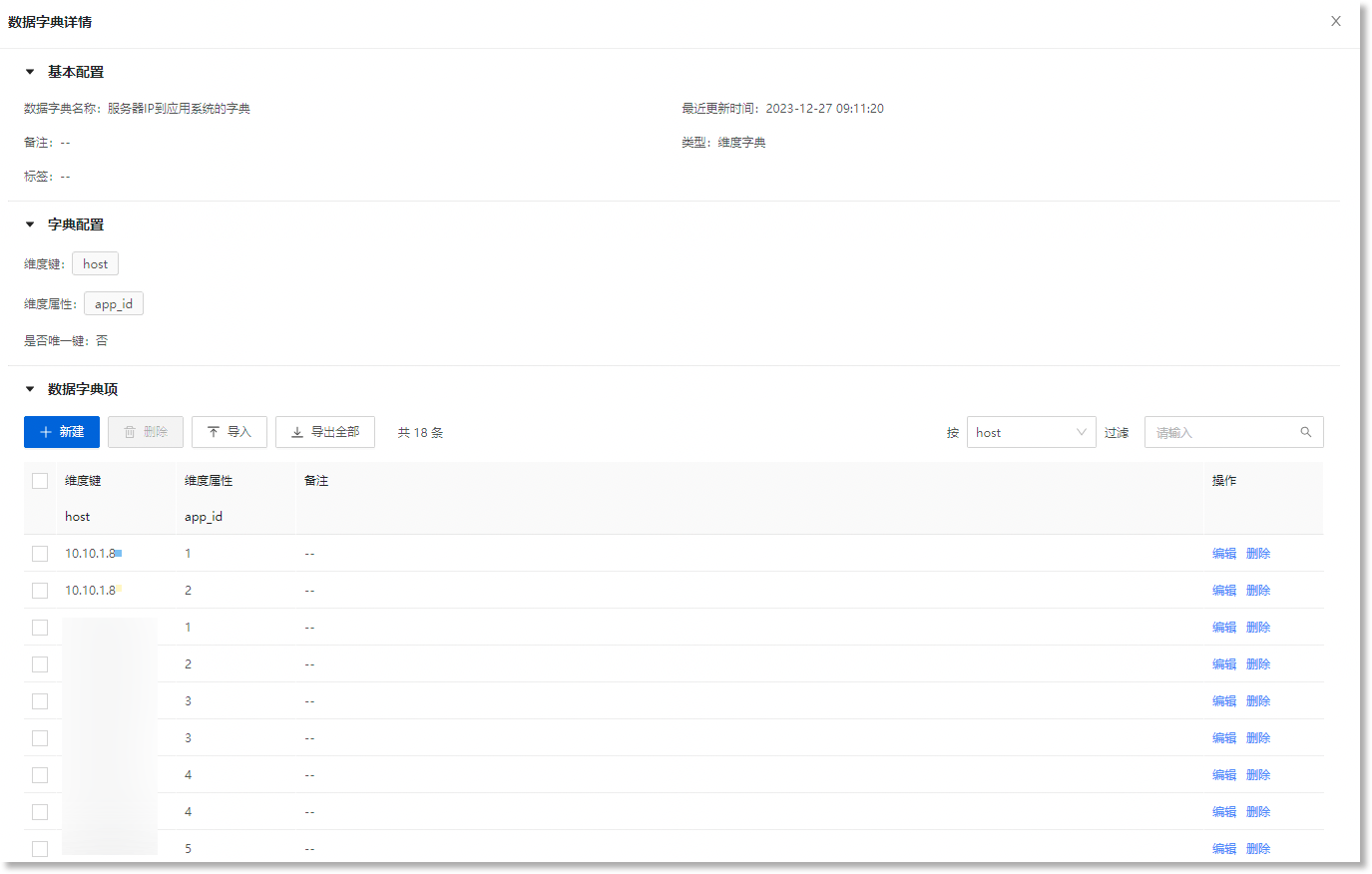
维度字典示例参数:
| 配置参数 | 参数说明 |
| *数据字典名称 | 服务器IP到应用系统的字典 |
| *维度键名称 | host |
| *维度属性名称 | app_id |
| *是否唯一键 |
否 说明:此示例以1个维度键对应多个维度属性场景为例,即1个host对应多个app_id,允许维度键重复。因此,此处配置为“否”。 |
维度字典项示例参数:
| 配置参数 | 参数说明 |
| 维度键 | 10.10.1.8 |
| 维度属性1 | 1 |
| 维度属性2 | 2 |
3)使用dict_labels算子修改指标模型计算公式,利用上方配置的维度字典将app_id作为指标label添加到指标数据中,扩充指标序列
进入数据管理 > 数据模型 > 指标模型,基于dict_labels算子,修改指标模型计算公式,如下所示:
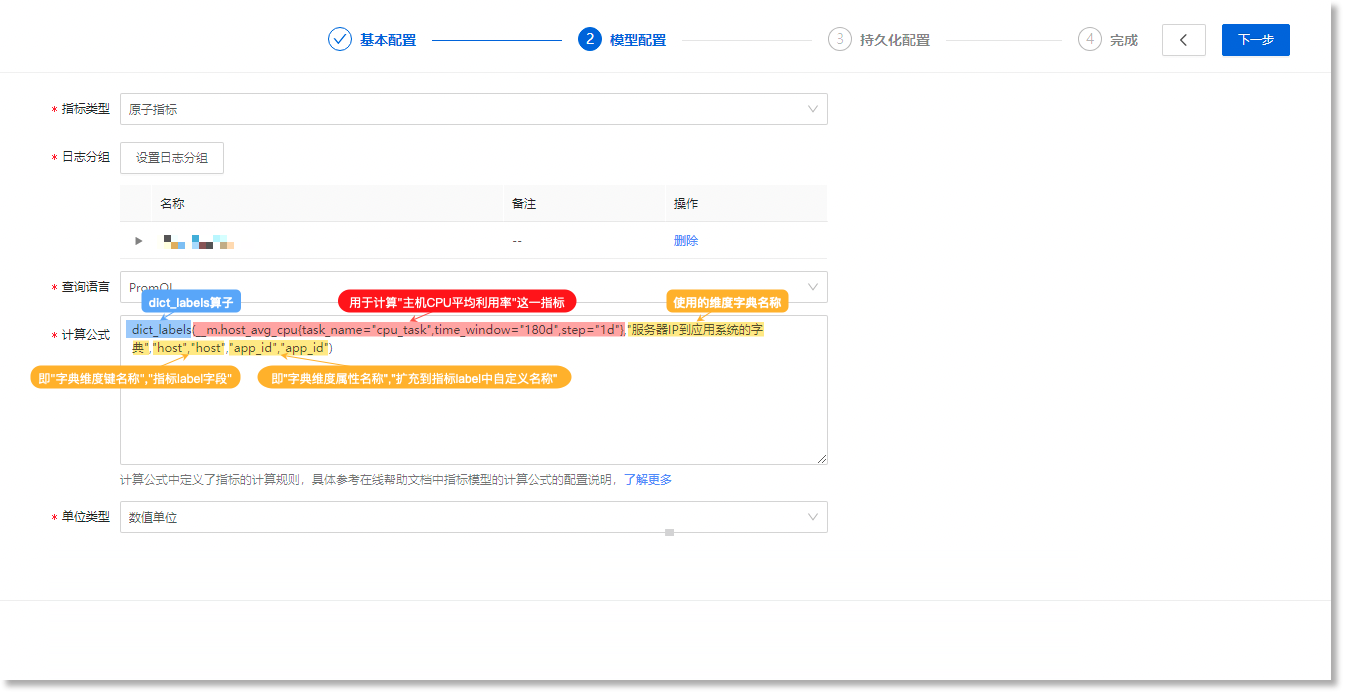
计算公式结构说明如下:
-
dict_labels:使用dict_labels算子;__m.host_avg_cpu{task_name}="cpu_task",time_window="180d",step="1d'}:host_avg_cpu为时间序列向量,此部分PromQL语句用于需计算主机CPU平均利用率这一指标;服务器IP到应用该系统的字典:使用的维度字典名称;"host", "host":为一组参数,配置结构应遵循“dict_key_1 string”, “vector_label_1 string”。其中,dict_key是字典的维度键名称,vector_label是指标label。具体来讲,”字典维度键字段(即host)“与”指标label字段(即第2个host)”这一组参数将作为关联条件(即host=10.10.1.8),用于筛选所需维度属性字段的关联条件。"app_id", "app_id":为一组参数,配置结构应遵循"dict_value_1 string", "vector_label_3 string"。其中,dict_value是字典的维度属性名称(即app_id),vector_label(即第2个app_id)是扩充到指标label中的自定义名称。具体来讲,由于使用的维度字典中不是“唯一键”,“host=10.10.1.8”对应的”字典维度属性(app_id)”有两个值(即“app_id=1”、“app_id=2”),因此应用此公式后,将扩展为2个指标序列,分。别以自定义维度名称(即app_id)添加到指标label中。
注意:关于dict_labels的语法结构的详细配置说明,请具体参考 AnyRobot Family 数据虚拟化开发者指南 的2.3.4.24 dict_labels 章节。
完成配置后,点击数据预览,查看指标序列扩充后的效果。如下所示:
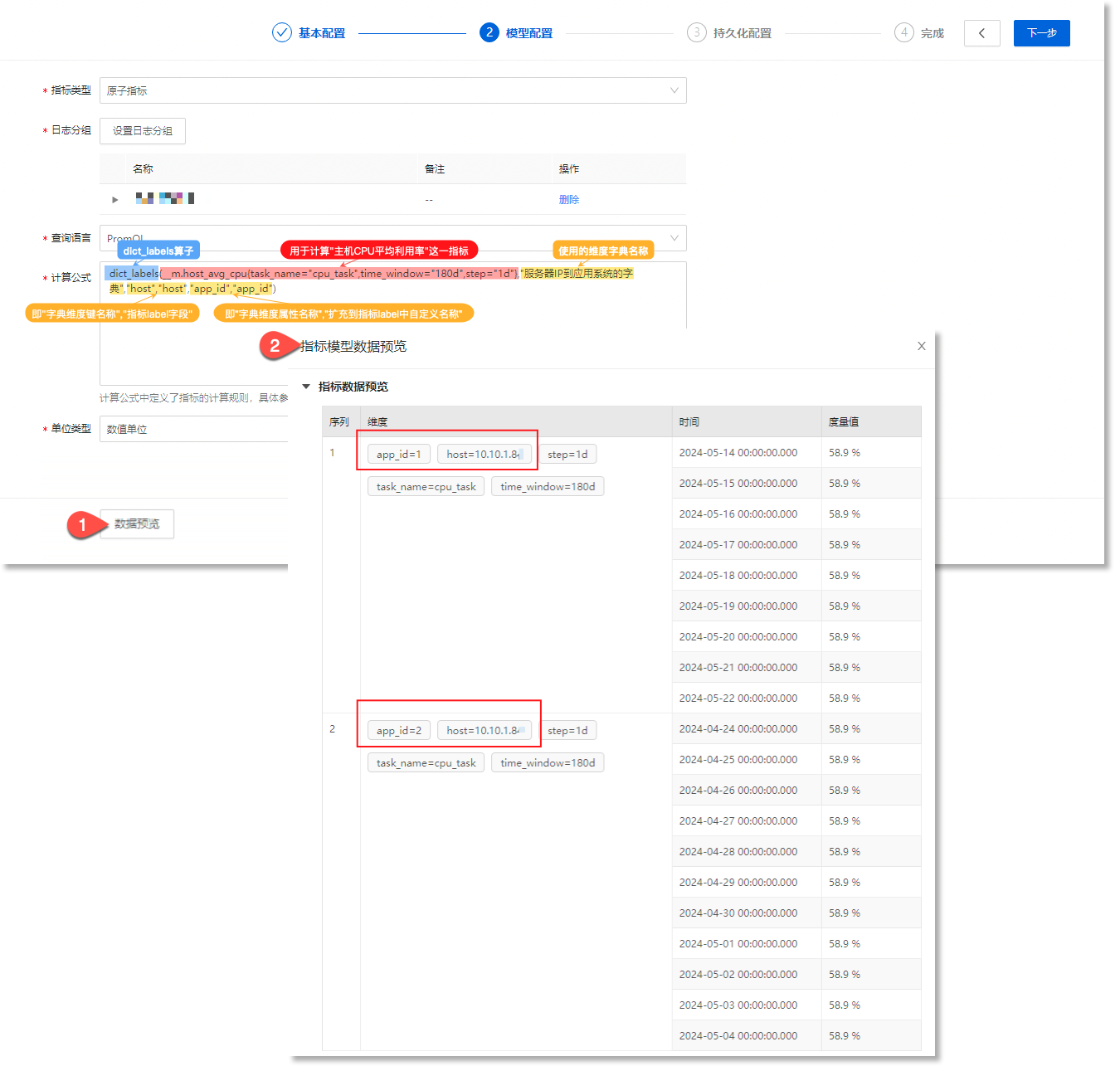
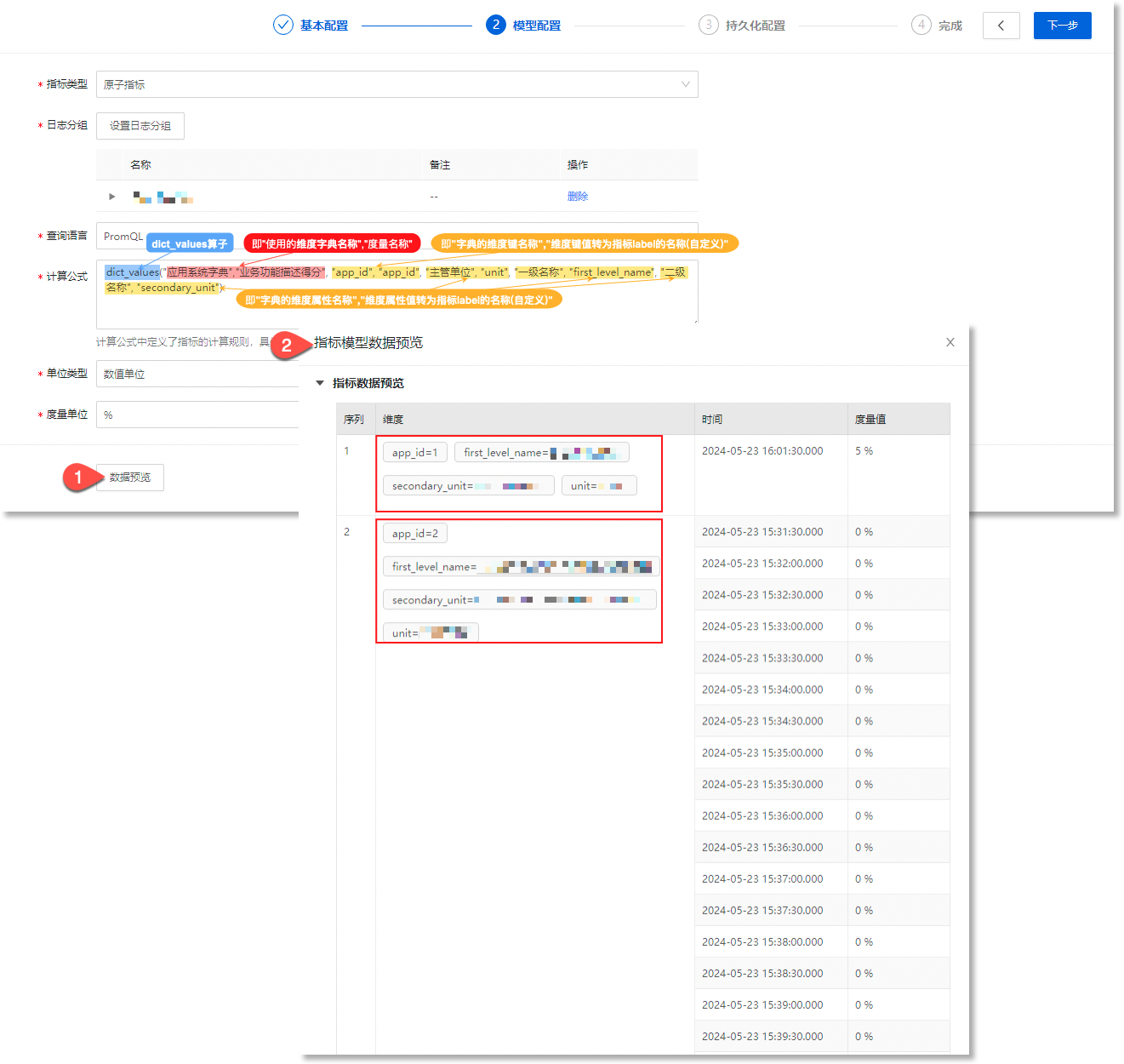
应用场景二:下文以“应用系统字典”为例,介绍如何基于dict_values算子,将维度字典转化为可进行指标计算的指标(序列)。适用于针对非数值类的静态数据进行指标计算的场景。
1)创建所需维度字典
进入数据管理 > 数据模型 > 数据字典,新建/导入所需维度字典。下图所示的维度字典中,“业务功能描述”这一维度属性值为手动添加的非数值型静态数据,“业务功能描述得分”这一维度属性值是基于业务场景添加的对应数值,便于后续作为指标进行计算。
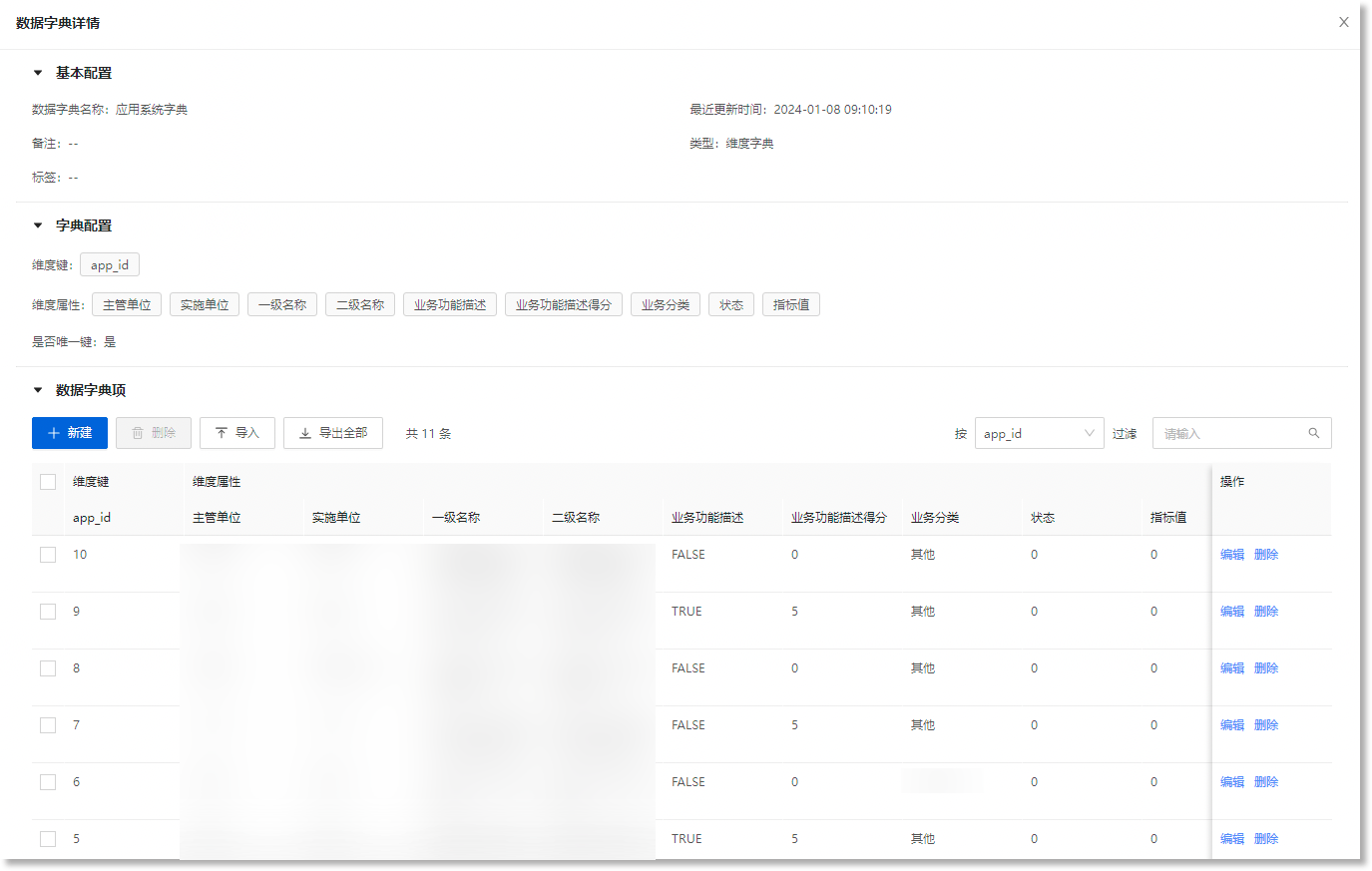
关于维度字典的数据字典示例参数如下所示,数据字典项可根据实际需求添加。
| 配置参数 | 参数说明 |
| *数据字典名称 | 业务功能描述得分 |
| *维度键名称 |
app_id |
| *维度属性名称 |
主管单位 |
|
一级名称 |
|
|
二级名称 |
|
| *是否唯一键 |
是 |
2)配置所需指标模型,基于dict_values算子,将上方配置的维度字典转化为指标。
进入数据管理 > 数据模型 > 指标模型,基于dict_labels算子修改指标模型计算公式。执行下方示例的计算公式后,指标模型将「应用系统字典」中的"业务功能描述得分"维度属性作为其度量字段,将字典中的app_id、主管单位、一级名称、二级名称维度属性值作为指标label添加到指标数据中。
由于「应用系统字典」配置为“唯一键”,因此,字典中的维度键都将转化为新的指标序列。
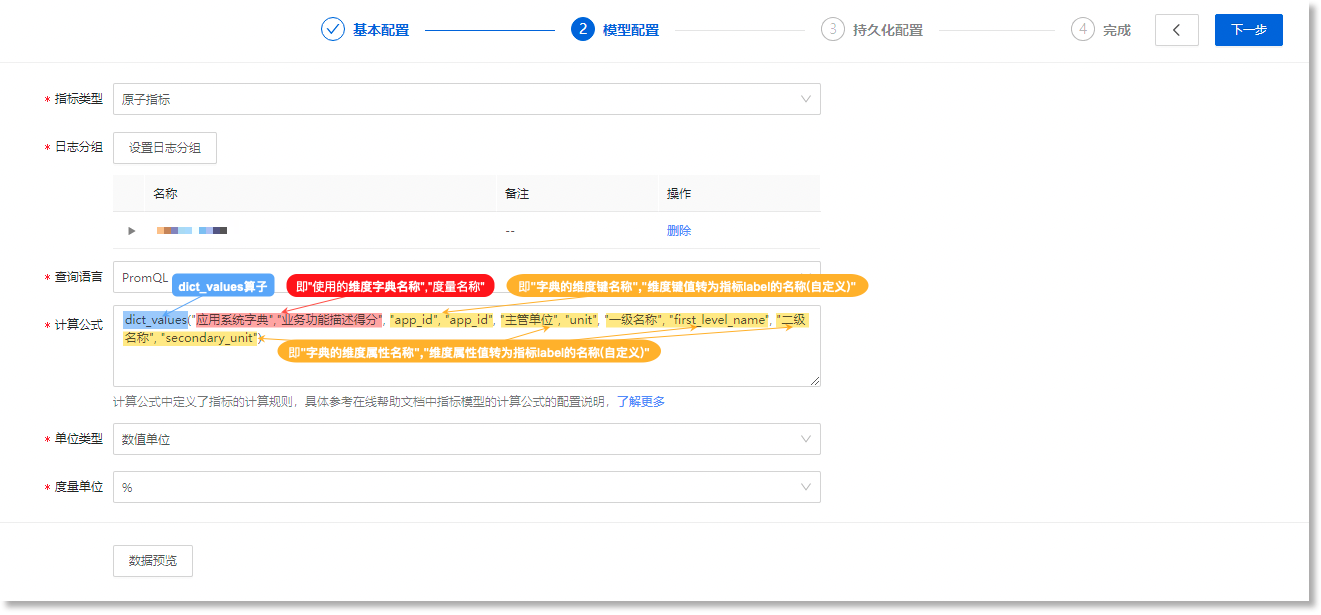
示例的计算公式结构说明如下:
-
-
dict_values:使用dict_values算子; -
"
应用系统字典","业务功能描述得分":即"使用的维度字典名称","度量字段"。 -
提示:度量字段应选择字段值为数值类型的字段,否则指标模型计算公式将报错。
"app_id","app_id":为一组参数,配置结构应遵循“dict_key_1 string”,“vector_label_1 string”。其中,dict_key是字典的维度键名称,vector_label是字典维度键值转为指标label的自定义名称。具体来讲,”字典的维度键名称(即app_id)“将作为自定义指标label(即第2个app_id)的值,添加到指标数据中;
-
提示:将维度字典转化为指标时,维度字典中所有的维度键都将转化为指标label。若配置时,未在计算公式中对所有维度键进行配置,dict_values算子也会将剩余未配置的维度键转化为指标label,并随机生成对应的label名称。
-
"主管单位","unit"、"一级名称","first_level_name"、"二级名称","secondary_unit":这三组参数的配置结构都应遵循"dict_value_1 string","vector_label_3 string"。其中,dict_value是字典中的维度属性名称(即主管单位、一级名称、二级名称),vector_label是这些维度属性的值转为指标label对应的自定义名称(即unit、first_level_name、secondary_unit)。
提示:配置时,支持用户按需填写需要转化为指标label的维度属性名称;需注意,自定义指标label名称时,名称仅可以包含大小写英文、数字、下划线(_),且不能以数字开头。
注意:关于dict_values的语法结构的详细配置说明,请具体参考 AnyRobot Family 数据虚拟化开发者指南 的2.3.4.25 dict_values 章节。
完成配置后,点击数据预览,查看基于此维度字典生成的指标数据。如下所示: