














本快速入门旨在让用户快速了解AnyRobot基本使用流程,并以具体使用场景Linux 可观测性为例进行阐述,如何应用AnyRobot进行Linux系统问题排障。本文主要内容如下:
1.AnyRobot 基本使用流程/可观测性基本实现步骤/可观测性实施基本步骤/模板创建及使用
- 相关创建:字段模型、索引库、日志分组、数据字典、解析规则、指标模型、告警规则、仪表盘、全景图
- 对象导入:将所创建的相关对象,导入AnyRobot系统
- 数据采集:根据所需要观测的场景进行相关数据采集
- 观测模型使用:应用仪表盘、全景图进行排障
![]() 说明:如果直接应用已有相关模板,例如:指标模型,全景图,仪表盘等,可以省略相关创建过程。
说明:如果直接应用已有相关模板,例如:指标模型,全景图,仪表盘等,可以省略相关创建过程。
Linux可观测性通过实时监控和可视化图表展示Linux系统的关键指标和性能数据,帮助管理员和开发人员全面了解系统的运行状况,快速定位问题和瓶颈,优化性能并提高系统的可靠性和可扩展性。它提供直观的界面,集中显示CPU、内存、磁盘、网络等指标的实时情况。通过这些功能,管理员可以迅速识别系统中的异常和瓶颈,优化资源利用和性能表现,及时采取措施以确保系统的稳定运行。
_61.png) 说明:在此不再赘述相关创建的详细过程,具体说明请见此用户指导各创建章节。此示例中,相关创建已完毕。
说明:在此不再赘述相关创建的详细过程,具体说明请见此用户指导各创建章节。此示例中,相关创建已完毕。
- 导入字段模型:进入AnyRobot数据管理>数据存储>字段模型页面,点击【导入】按钮,导入对应的system_metric_dee字段模型,具体可参考下图:
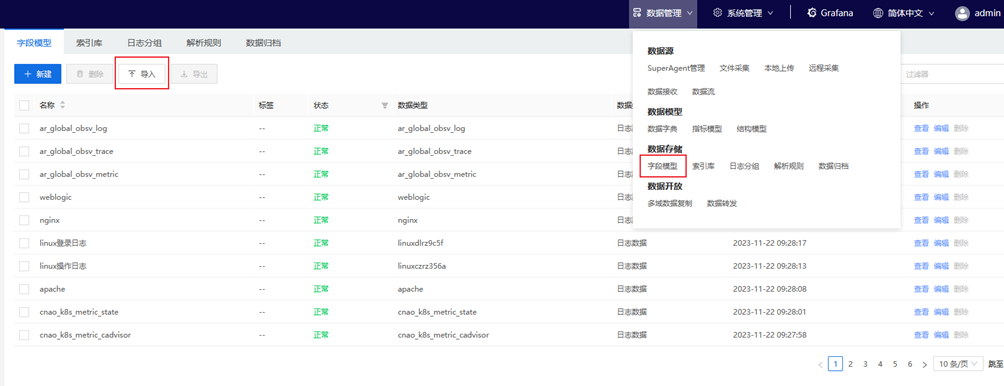
- 创建索引库:进入AnyRobot数据管理>数据存储>索引库页面,点击【新建】按钮,按照以下配置新建system_metric_dee索引库,如下所示:

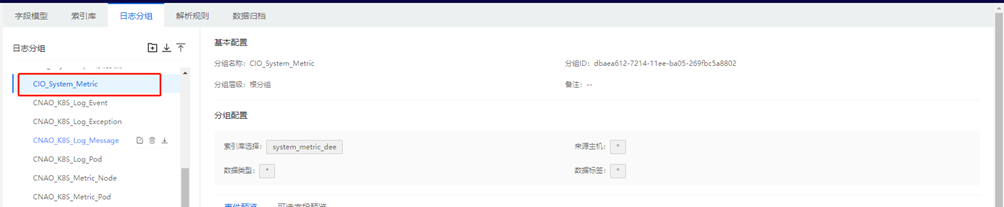
- 导入日志分组:进入AnyRobot数据管理>日志分组管理页面,点击【导入】按钮,导入对应的日志分组,具体可参考下图:
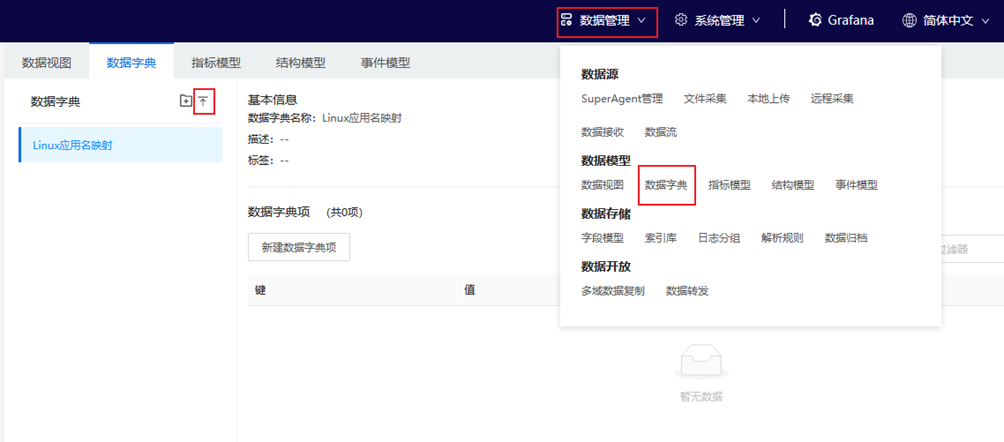
- 导入数据字典:进入AnyRobot 数据管理>数据源>数据字典页面,点击【导入】按钮,导入对应“Linux应用名映射”数据字典,如下图所示:
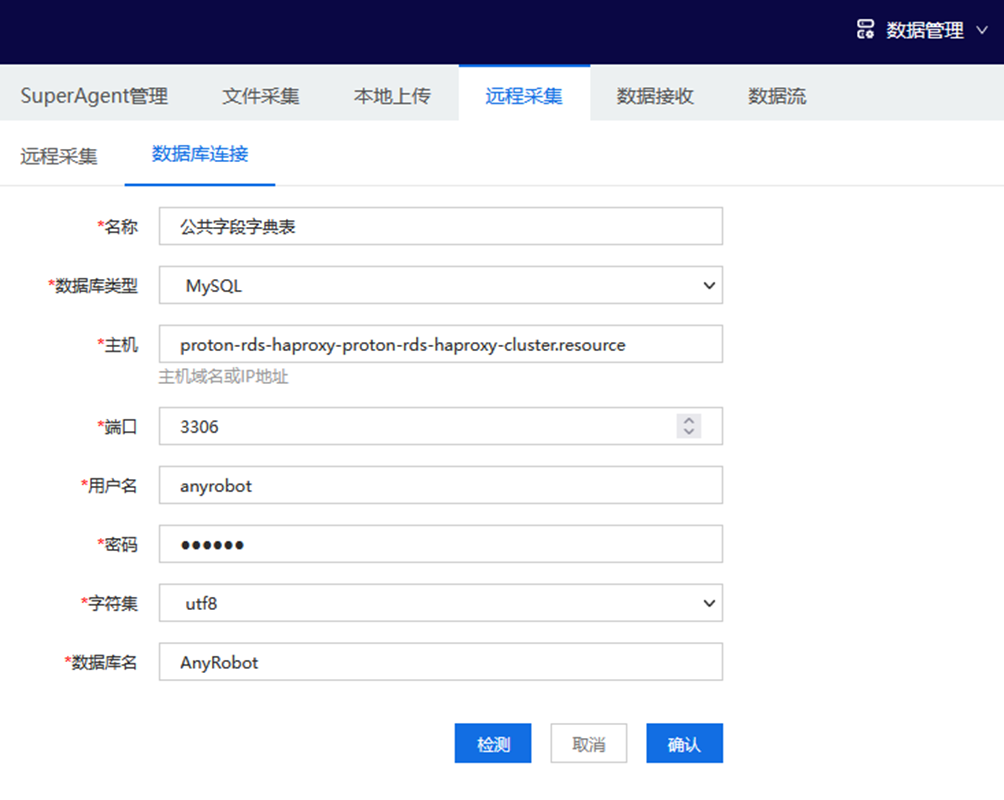
- 创建数据库连接:进入AnyRobot 数据管理>远程采集>数据库连接页面,点击【新建】按钮,按照以下配置新建“公共字段字典表”数据库连接,如下图所示:
 说明:AnyRobot的数据库相关配置信息,请联系系统管理员获取。
说明:AnyRobot的数据库相关配置信息,请联系系统管理员获取。 - 导入解析规则:进入AnyRobot 数据管理>数据存储>解析规则页面,点击【导入】按钮,导入对应的解析规则,在导入后找到并点击启用,如下图所示:
- 导入指标模型:进入AnyRobot数据管理>指标模型页面,点击【导入】按钮,导入对应的指标模型,具体可参考下图所示:

- 导入告警规则:进入AnyRobot告警 > 告警配置页面,点击【导入】按钮,导入对应的告警规则,具体可参考下图所示:
- 导入仪表盘:进入AnyRobot系统管理>对象管理>仪表盘页面,点击【导入】按钮,导入对应的仪表盘,具体可参考下图所示:
- 数据采集:具体数据采集方案和策略,依可观测性方案不同而不同,此数据采集不具通用性,在此不再赘述。如果想获取Linux可观测性的详细数据采集相关信息,请查看:AnyRobot Family Linux 可观测性实施指导
Linux可观测性仪表盘根据不同的分析纬度,共包含为四个仪表盘,如下表。本文结合相关用户场景举例说明在用户环境中当系统出现问题时,运维人员如何使用Linux可观测性仪表盘对相关问题进行分析和快速的定位。
|
仪表盘名称 |
概述 |
|
00-Linux概览 |
该仪表盘用于展示监控的Linux实例个数、被监控的Linux实例中部分重要指标的极值情况(如CPU命中率,内存利用率,系统负载等)、以及相关指标极值的增长变化趋势(如主机数趋势、CPU最大利率趋势等)。 可通过该仪表盘确认被监控的Linux实例中是否存在异常情况,从而判断是否需要结合其他仪表盘做进一步的分析 |
|
01-Linux 运行&负载&网络&磁盘 |
该仪表盘用于对Linux操作系统中相关资源的负载情况进行实时监控。其中包括CPU的负载情况,网络读取速率、网络丢包以及磁盘负载情况等。 可通过该仪表盘可以实时追踪系统资源的使用情况,提供性能指标和趋势分析,帮助管理员及时发现和定位性能瓶颈、资源不足、异常行为和故障情况,以保障系统的稳定运行、以提高系统的可靠性、可扩展性和用户满意度。 |
|
02-Linux 内存&CPU&存储空间 |
该仪表盘用于对Linux的CPU、内存、磁盘、文件资源等使用情况请求实时监控。 监控Linux资源的作用是实时监测和管理系统的CPU、内存、磁盘、网络等关键指标,以优化性能、提高可靠性、快速排查问题、进行容量规划和安全监控,帮助管理员全面了解系统的运行状态,确保系统稳定运行并做出基于数据的决策。 |
|
03-Linux进程资源剖析 |
该仪表盘用于Linux中进程相关的信息,包括当前的进程总数、运行中的进程数、以及进程内存使用量TOP10、CPU进程使用量top10等。通过实时监测和分析进程的资源使用情况可以帮助管理员全面了解系统中进程的行为和资源消耗模式,优化系统的性能瓶颈、快速定位故障根源、规划资源扩展、检测安全漏洞和异常行为、合理分配和调度资源,确保系统稳定运行,提高效率和可靠性。 |
|
04-Linux应用存储空间分析 |
该仪表盘用于展示和监控Linux系统中应用存储空间使用情况,包括Linux应用所在挂载点的存储容量、使用量、使用率,以及存储空间的总量和剩余量。通过实时监测和分析应用存储空间的实时占用情况和趋势,帮助管理员识别存储空间使用的异常情况,及时调整存储资源,确保系统存储的合理分配和高效使用,避免因存储空间不足导致的系统性能问题。 |
- 场景示例:用户请求数量增加导致应用软件性能下降原因分析
问题背景:项目部署之后,随着业务量的增加,服务的处理性能在不断下降,此时系统管理员在对请求链路分析时发现,随着用户数量的增加,请求数激增,在请求MongoDB服务时,耗时较高。使用【MongoDB-性能剖析】仪表盘查看MongoDB服务指标时发现,此时MongoDB服务的QPS和TPS不断下降,处理的操作数在不断下降,且操作延迟在不断增加。如下图所示。此时系统管理员需要对MongoDB服务进行性能分析,定位性能瓶颈,提出相关的性能优化方案。
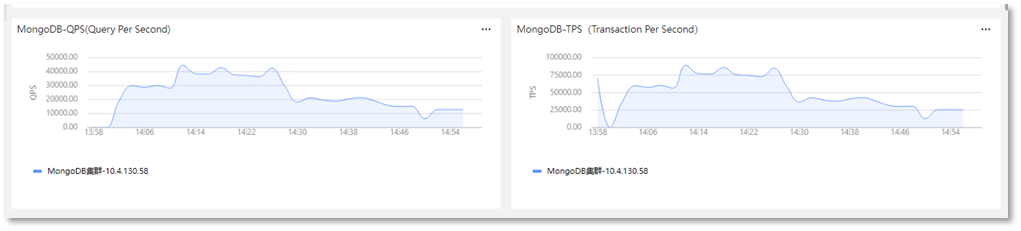
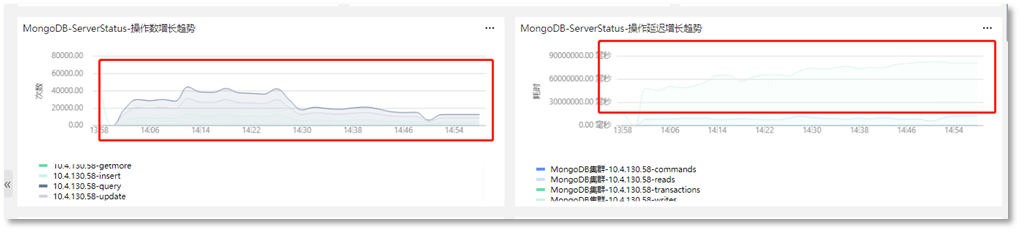
-
- 基于Linux可观测性仪表盘对MongoDB服务器资源进行分析
第一步:进入【01-Linux概览】仪表盘,根据主机IP进行筛选出MongoDB所在服务器,查看服务器系统指标是否出现正常,如下所示:
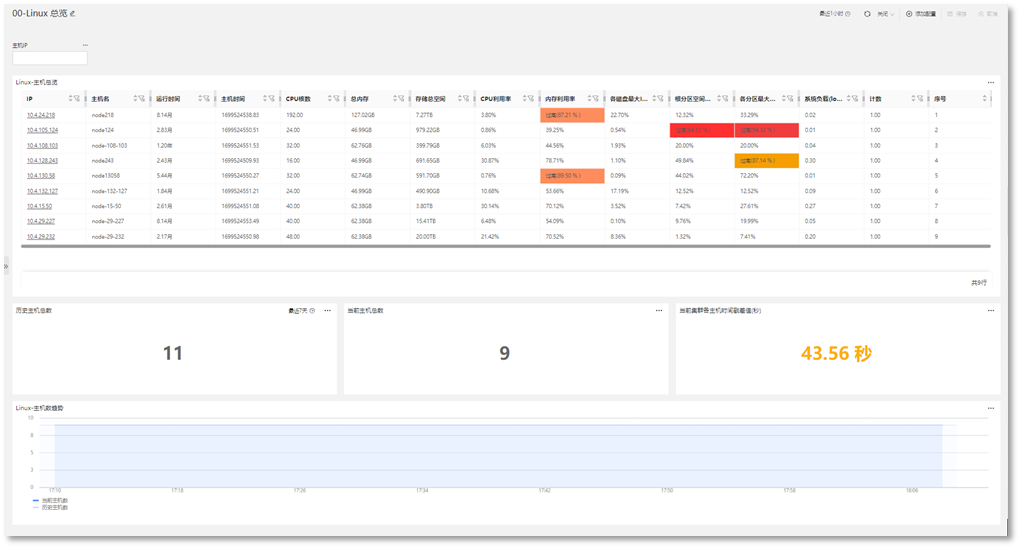
此时发现MongoDB服务器运行正常, CPU利用率正常,但在发生问题的时间段内,内存使用率和系统的五分钟负载较高,且磁盘IO到达97%。表示磁盘正在受到相当大的负载。此时需要对磁盘资源使用情况做进一步分析。
第二步:根据【01-性能剖析】仪表盘对磁盘相关的指标进行分析,如下所示:
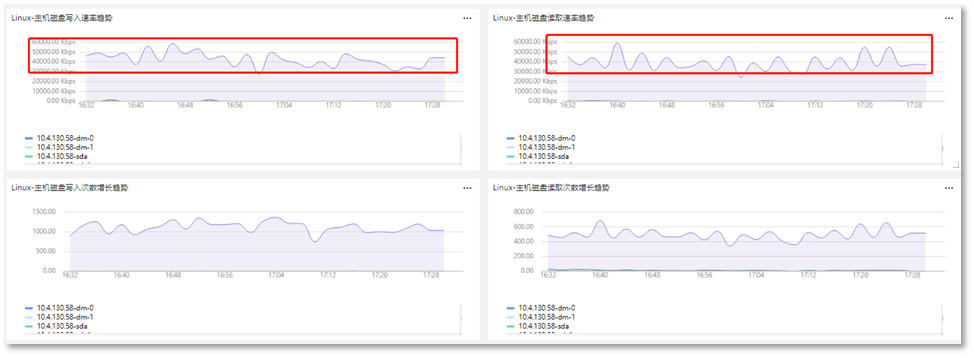
此时发现在当前服务器当中,磁盘的写入速率、写入次数速率均比较高,磁盘的写入速率已达到当前磁盘的写入速率瓶颈,此时可以推断出当用户的请求数量增加之后,会导致MongoDB出现大量的写磁盘操作,写入的速率过高,导致磁盘出现写入瓶颈,从而影响应用的整体性能。此时需要对MongoDB的相关指标进行分析,定位导致MongoDB出现大量写磁盘操作的原因。然后结合实际情况对MongoDB服务进行优化。
-
- 基于MongoDB性能剖析仪表盘分析MongoDB内存是否出现瓶颈,导致数据库服务性能下降
第一步:查看指标图,是否当前服务指标是否出现异常值,如下所示:
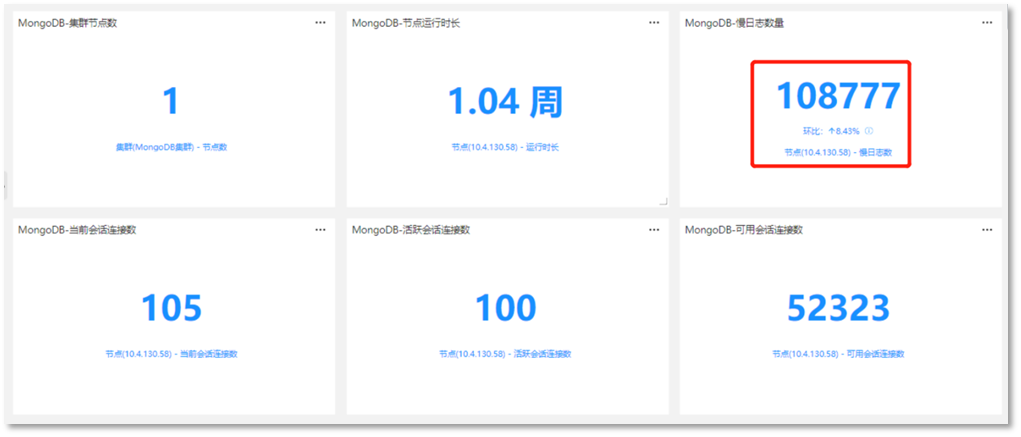
此时,发现当前服务中出现大量的慢操作日志,说明存在大量的耗时操作,导致数据库服务性能下降,需要进行进一步分析。
第二步:查看【MongoDB-SlowLog-慢日志列表】,对出现的慢日志进行分析,分析出现慢操作的原因,如下所示:
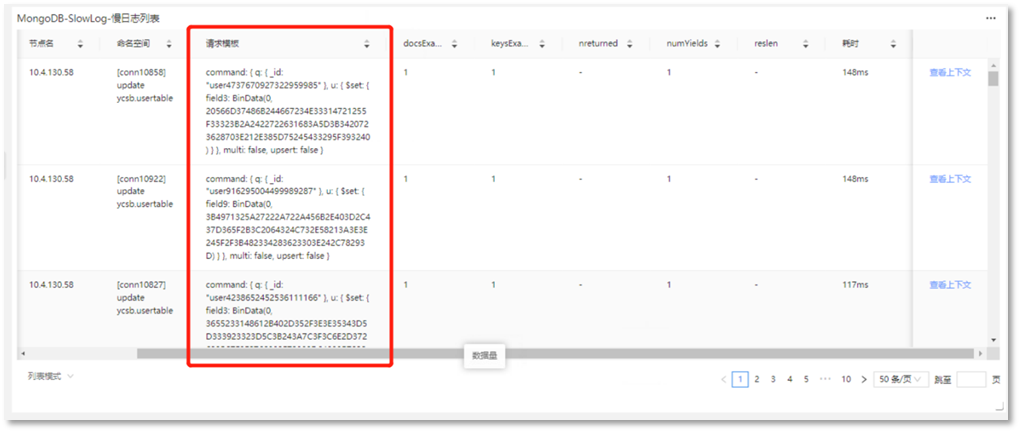
发现在慢日志列表当中,出现的慢日志都是和command相关的操作,在MongoDB中,执行command命令也可能会出现慢查询,导致慢日志的产生。导致MongoDB command命令变慢的原因包括锁争用,磁盘I/O延迟,网络延迟,数据库大小等,结合磁盘资源使用情况判断,因磁盘IO过高导致command命令变慢,此时,需要进一步分析磁盘IO过高的原因。
第三步:根据【MongoDB-Memory-常驻内存使用情况趋势】、【MongoDB-Memory-虚拟内存使用情况趋势】查看内存的使用情况。
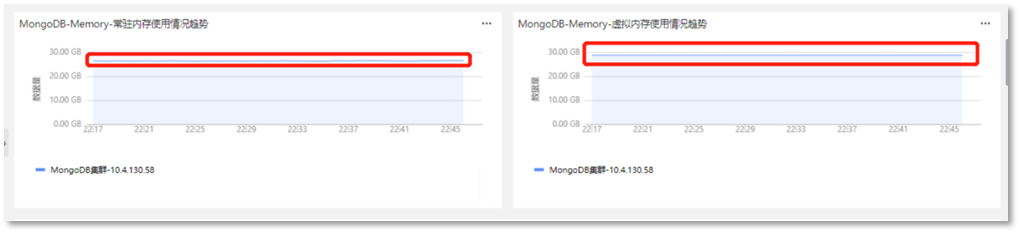
发现当前服务的常用内存使用量已达到为MongoDB分配的常驻内存总量,且虚拟内存使用较高,说明分配的内存可能已存在瓶颈,需要进行进一步分析。
第四步:根据【MongoDB-Memory-内存缺页次数趋势】查看当前服务是否出现内存缺页的情况,如下所示:
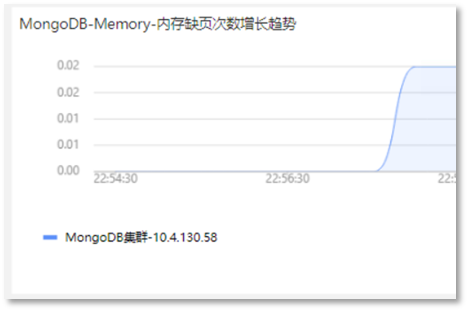
此时发现MongoDB中,内存的缺页次数在不断增加,说明在频繁的进行磁盘相关的操作。
第五步:查看缓存的使用情况,查看脏页率是否太高,导致进行磁盘的写入频繁,如下所示:
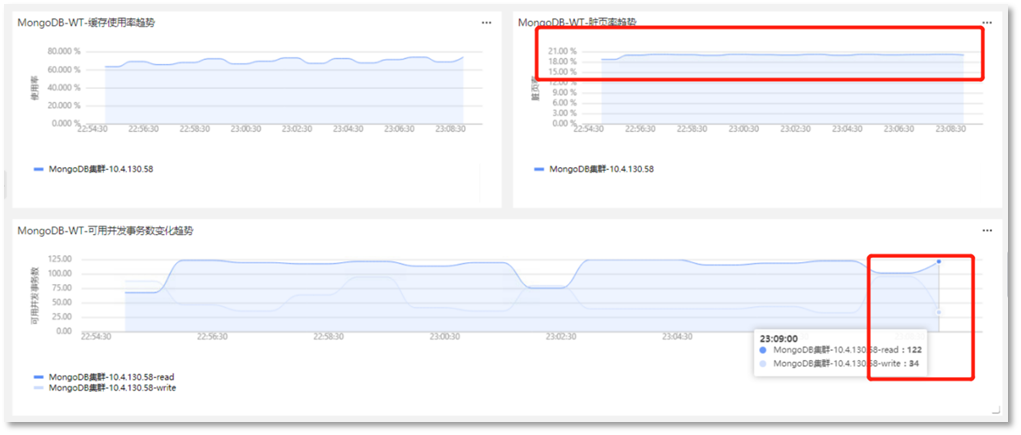
此时,发现当前服务中,脏页率接近20%,且MongoDB可并发事务数中可写事务数在不断下降,说明此时MongoDB内存空间不足,需要不断的进行写磁盘操作,从而导致出现磁盘IO瓶颈。
结论:在应用运行过程中,由于为当前MongoDB服务分配的内存空间不足,当操作的数据量过大时,会导致MongoDB进行频繁的磁盘操作,出现磁盘相关的性能瓶颈,从而导致数据库性能下降。此时需要实际情况对资源进行优化。可从以几方面进行考虑:
-
-
-
- 内存优化:MongoDB对内存的使用非常重要。尽可能多地分配内存给MongoDB进程,可以提高性能和稳定性。可以通过调整MongoDB配置文件中的wiredTigerCacheSizeGB参数来控制内存的使用。
- 硬盘优化:MongoDB对硬盘的要求也比较高,建议使用高性能的SSD硬盘或NVMe硬盘,以提高IO性能。此外,还可以通过调整MongoDB配置文件中的wiredTigerCollectionBlockCompressor参数来控制数据压缩,以减少硬盘的使用。
- 集群优化:如果使用MongoDB的分片或副本集功能,需要对集群进行优化。可以通过增加分片节点、增加副本集成员、调整写入确认级别等方式来提高集群的可用性和性能。
-
-