AnyRobot事件模型管理模块支持事件模型的创建、删除、修改、查看、导入、导出等统一管理功能,通过对接入数据源、检测规则触发条件或聚合规则的配置,为业务应用的展示查询、告警通知等场景提供统一格式的事件数据支持。相关操作说明如下:
• 手动创建事件模型
› 创建原子事件模型
› 创建聚合事件模型
进入数据管理>数据模型>事件模型配置页面,点击【+新建】,进入“新建事件模型”的配置流程,如下所示:
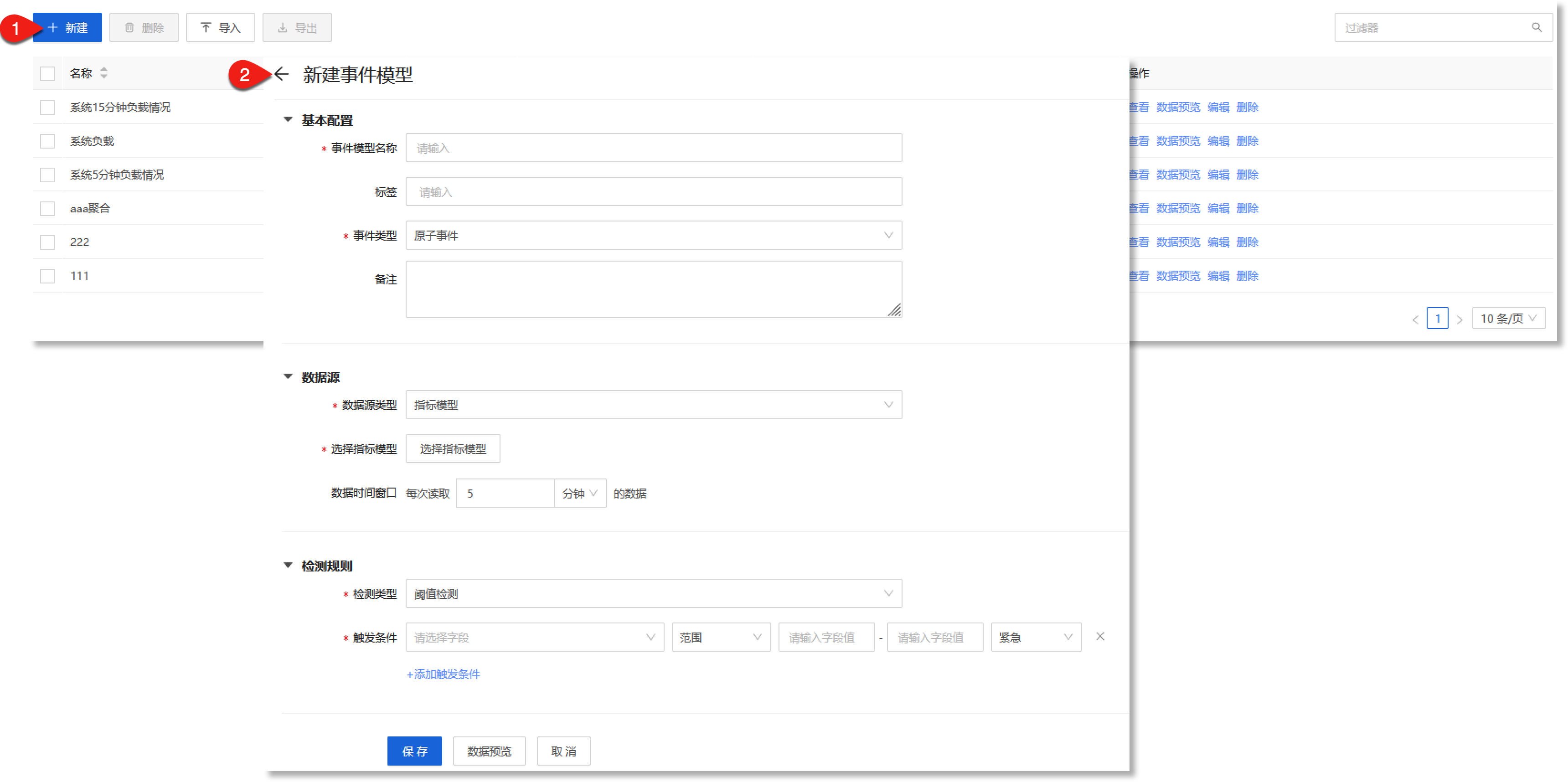
配置参数说明如下:
| 配置参数 | 参数说明 | 限制条件 |
| *事件模型名称 |
填写原子事件模型的名称,此名称具有全局唯一性。 |
• 事件模型名称不能重复,且不能为空; • ≤40个字符 |
| 标签 |
根据实际需求设置原子事件模型的标签信息,用于业务标识。可通过回车键添加多个标签。 |
• 最多支持创建5个标签
|
| *事件类型 |
配置原子事件模型的事件类型,配置为"原子事件",此项为必填项。原子事件模型是事件模型中的基本构成单位,主要应用于机器数据异常检测场景。 注意:聚合事件模型是对原子事件数据的进一步分析,通常应用于异常事件的健康度计算、根因定位和告警降噪等场景。相关配置操作说明,请参见 聚合事件模型。 |
- |
| 备注 |
根据实际需求填写原子事件模型的其他属性信息。 |
• ≤255个字符 |
当事件模型的“事件类型”配置为“原子事件”时,配置窗口如下所示:
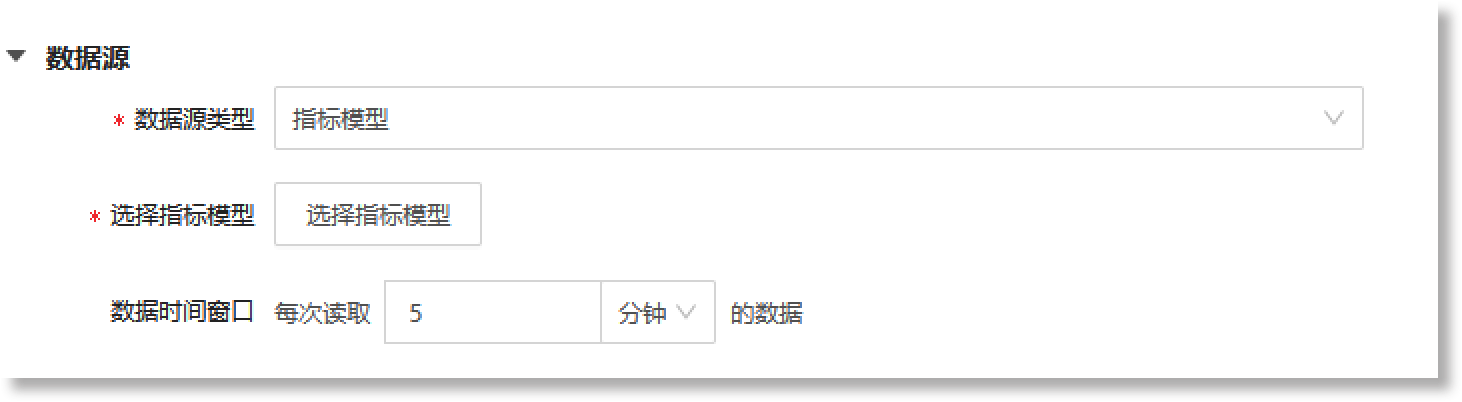
相关配置参数说明如下:
| 配置参数 | 参数说明 | 限制条件 |
| *数据源类型 |
设置原子事件模型的数据来源类型,支持“指标模型”、“数据视图”,默认为“指标模型”。 |
- |
| *数据来源 |
设置原子事件模型的数据来源,支持配置“指标模型”或“数据视图”。 • 当”*数据源类型“配置为“指标模型”时,点击【选择数据来源】选择所需指标模型作为数据来源,支持配置多个指标模型。抽屉列表中展示了系统已有的指标模型,点击“ • 当”*数据源类型“配置为“数据视图”时,点击【选择数据来源】勾选所需数据视图作为数据来源。抽屉列表中展示了系统已有的数据视图,点击“ |
- |
| 数据时间窗口 |
根据实际需求设置读取指标数据/数据视图的时间范围。 此项为选填项,具体配置时需要在文本配置框中填写具体数值,并选择其时间单位,可选时间单位:分钟、小时、天。 需注意,数据来源配置为“数据视图”时,建议数据时间窗口配置在1小时以内,否则会产生性能问题。 |
• 设置数据时间窗口时,需在文本框中输入正整数数字; • 当时间单位为“分钟”,最大输入数字为59;当时间单位为“小时”,最大输入数字为24;当时间单位为“天”,最大输入数字为1 |
AnyRobot原子事件模型支持阈值检测、状态检测两种检测类型。阈值检测用于实现指标数据的检测;状态检测用于实现日志数据多字段的联合检测。具体配置说明如下:
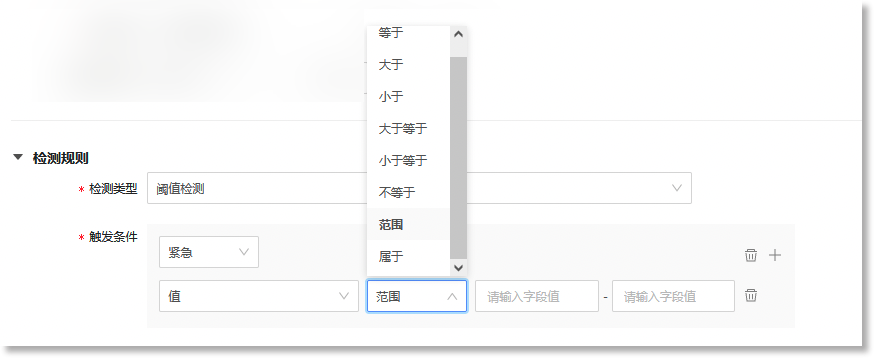
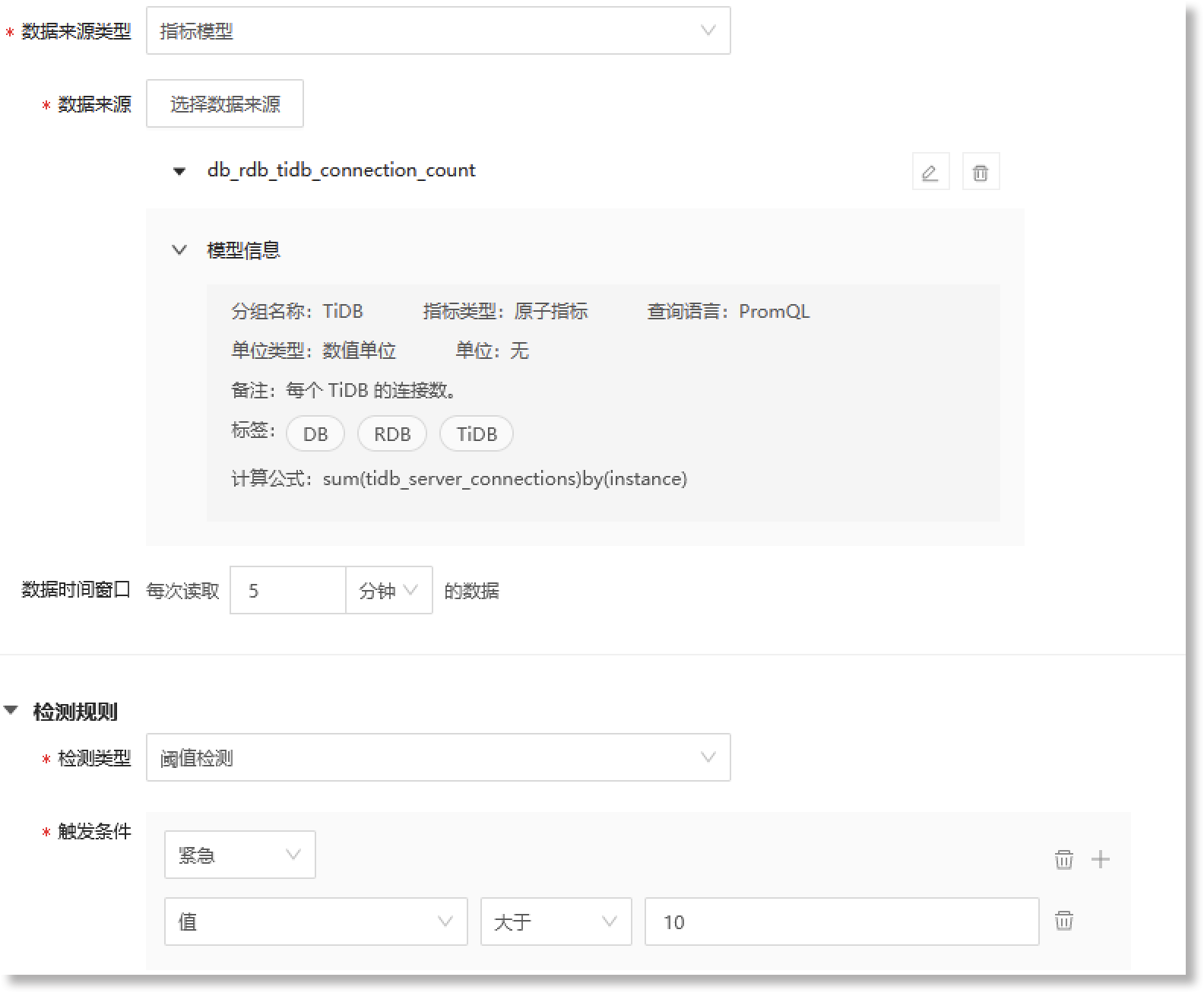
当事件模型的“*事件类型”为“原子事件”,且”*数据源类型“为“指标模型”时,事件模型的”*检测类型”支持配置为“阈值检测”。"检测规则"的配置窗口如下所示:
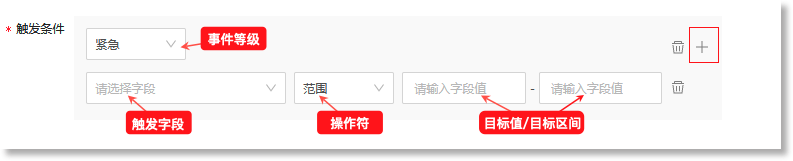
关于阈值检测“*触发条件”参数的配置说明如下:
| 配置参数 | 参数说明 |
|
*触发条件 (阈值检测) |
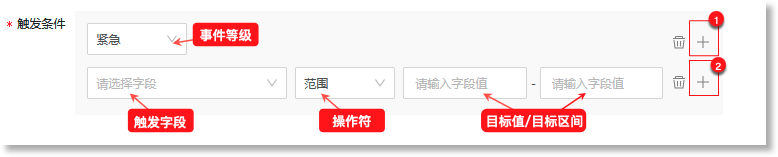
设置事件模型基于指标数据生成原子事件数据的触发条件。当来源指标数据命中此触发条件时,事件模型将生成格式统一的事件数据。阈值检测规则可配置的触发条件包括:触发字段、操作符、目标值/目标区间、事件等级,具体如下:
• 触发字段:数据源中触发事件的具体字段。数据来源为“指标模型”时,触发字段为来源指标数据中的“值”字段; • 操作符:定义触发字段与目标值之间的关系。可配置的操作符包括:等于、大于、小于、大于等于、小于等于、不等于、范围、属于; • 目标值/目标区间:命中检测规则时,触发字段值的目标数值或所在数值范围。若操作符为“范围”,则“触发值”需配置为一个值区间。若操作符为“属于”,则可以添加多个目标数值; • 事件等级:设置命中上述触发条件后此事件对应的事件等级。可配置的等级包括:紧急、主要、次要、警告、不明确、清除,具体如下:
支持配置多个触发条件。点击上图红框所示的“ 需注意,在添加多个触发条件时,最多支持配置6条触发条件,且不支持配置重复的事件等级。 完成触发条件的配置后,您可以在 数据预览 中查看事件模型对应的事件内容描述信息。如下图所示,事件模型数据源选择指标数据(每个TiDB连接数),当事件模型检测到连接数的值大于“10”时,则此事件被判定为“紧急”等级的异常事件。
|
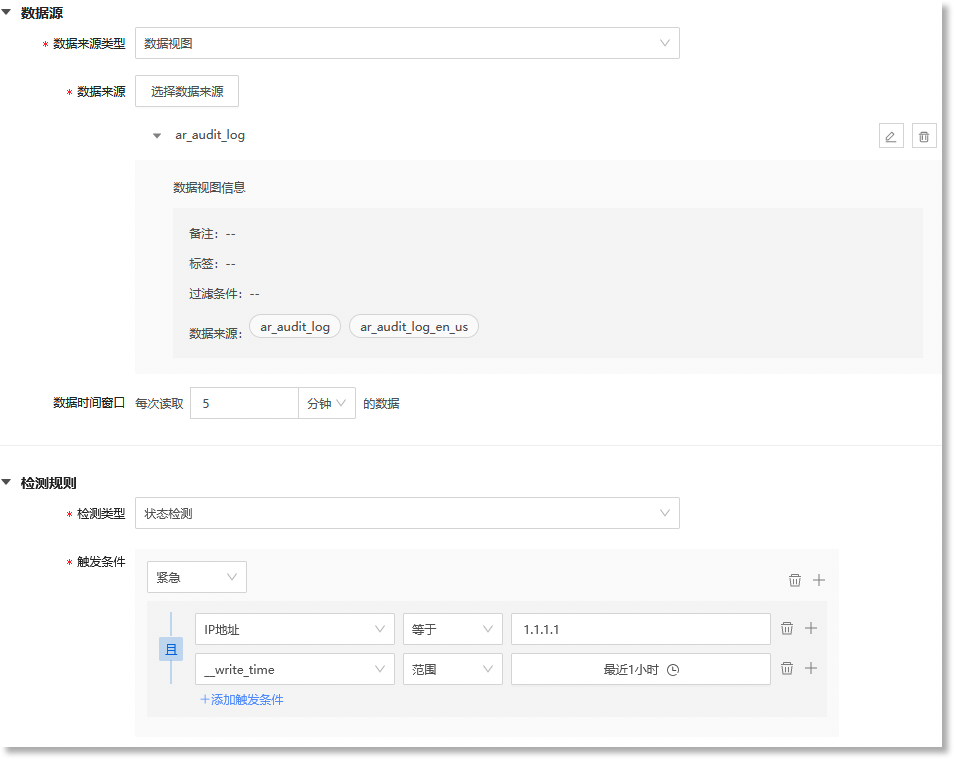
当事件模型的“*事件类型”为“原子事件”,且”*数据源类型“为“数据视图”时,事件模型的”*检测类型”支持配置为“状态检测”。"检测规则"的配置窗口如下所示:
关于状态检测“*触发条件”参数的配置说明如下:
| 配置参数 | 参数说明 |
|
*触发条件 (状态检测) |
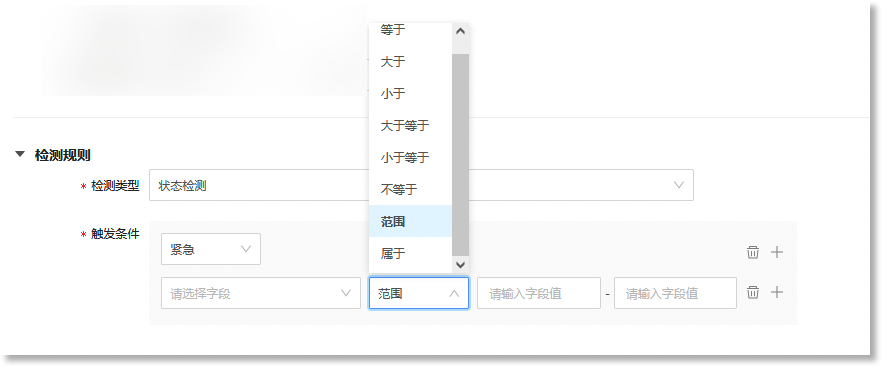
设置事件模型基于日志数据(数据视图)生成原子事件数据的触发条件。当来源日志数据命中此触发条件时,事件模型将生成格式统一的事件数据。可配置的触发条件包括:触发字段、操作符、触发值、等级,具体如下:
• 触发字段:数据源中触发事件的具体字段。数据来源为“数据视图”时,触发字段为来源数据视图中的指定字段; • 操作符:定义触发字段与目标值之间的关系。可配置的操作符包括:等于、大于、小于、大于等于、小于等于、不等于、范围、属于。不同类型的字段支持配置的操作符不同,例如:date类型的字段支持“范围”操作符;text、keyword类型的字段支持“等于、包含、不包含、属于”操作符;double类型的字段支持“等于、大于、小于、大于等于、小于等于、不等于、范围、属于”操作符。 • 目标值/目标区间:命中检测规则时,触发字段值的目标值或目标值区间。若操作符配置为“范围”,则“触发值”为一个值区间。若操作符配置为“属于”,支持添加多个“触发值”; • 事件等级:设置命中上述触发条件后此事件对应的事件等级。可配置的等级包括:紧急、主要、次要、警告、不明确、清除,具体如下:
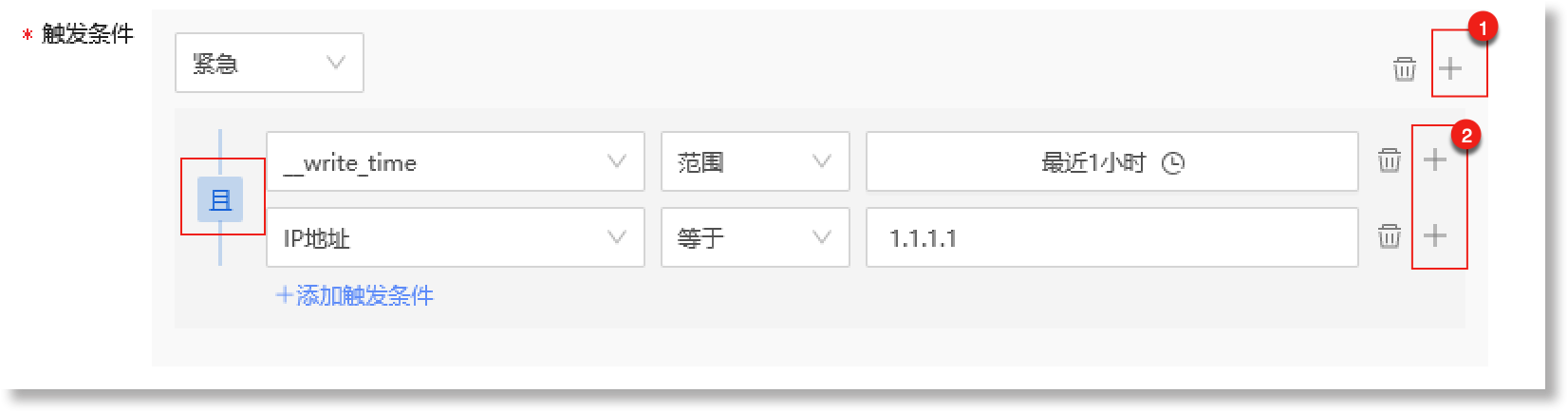
支持配置多个触发条件。点击下图①号红框中的“ 需注意,在添加多个触发条件时,最多支持配置6条触发条件,且不支持配置重复的事件等级。 支持多规则联合检测。点击下图②号红框中的“
提示:在多规则联合检测中,需要对多个检测结果进行“且”/“或”的逻辑运算后,才能得出最终的检测结果。如上图配置的针对多个字段的联合检测规则中,仅当所选数据视图中的“_write_time”字段值为“最近1小时”,且“IP地址”字段值为“1.1.1.1”时,事件模型才会将其判定为等级为“紧急”的异常事件。 完成触发条件的配置后,您可以在 数据预览 中查看事件模型对应的事件内容描述信息。如下图所示,事件模型数据源选择数据视图(ar_audit_log),当事件模型检测到数据视图中的“IP地址”字段值等于“1.1.1.1”且“__write_time”字段值在“最近1小时”的范围内时,则此事件被判定为“紧急”等级的异常事件。
|
进入数据管理>数据模型>事件模型配置页面,点击【+新建】,进入“新建事件模型”的配置流程,如下所示:
配置参数说明如下:
| 配置参数 | 参数说明 | 限制条件 |
| *事件模型名称 |
填写聚合事件模型的名称,此名称具有全局唯一性。 |
• 事件模型名称不能重复,且不能为空; • ≤40个字符 |
| 标签 |
根据实际需求设置聚合事件模型的标签信息,用于业务标识。可通过回车键添加多个标签。 |
• 最多支持创建5个标签
|
| *事件类型 |
配置聚合事件模型的事件类型,配置为"聚合事件",此项为必填项。聚合事件模型建立在原子事件模型之上的,更高层次的事件表示。聚合事件模型是对原子事件数据的进一步分析,用于表达更复杂、更全面的事件关系,通常应用于异常事件的健康度计算、根因定位和告警降噪等场景。 注意:原子事件模型是事件模型的基本构成单位,主要应用于机器数据异常检测场景。相关配置操作说明,请参见 原子事件模型。 |
- |
| 备注 |
根据实际需求填写聚合事件模型的其他属性信息。 |
• ≤255个字符 |
当事件模型的"事件类型"为“聚合事件”时,配置窗口如下所示:
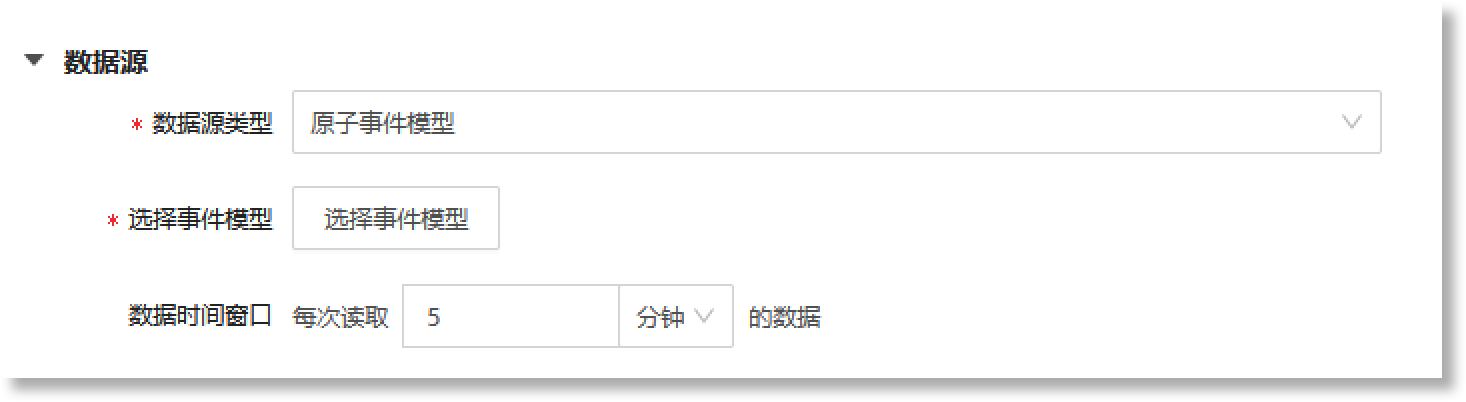
相关配置参数说明如下:
| 配置参数 | 参数说明 | 限制条件 |
| *数据源类型 |
设置聚合事件模型的数据来源类型,默认为“原子事件模型”。 提示:聚合事件模型是基于原子事件数据更高层级的事件表示。因此,聚合事件模型当前仅支持配置“原子事件模型”类型的来源数据。 |
- |
| *选择事件模型 |
设置聚合事件模型的来源原子事件数据,支持配置多个原子事件。 点击【选择事件模型】按钮,在页面右侧的配置抽屉中选择所需事件模型。抽屉列表中展示了系统当前已创建的所有事件模型,您可以添加筛选条件快速筛选出所需的原子事件模型,也可以点击列表中事件模型前的“ 注意:若找不到所需事件模型,也可点击抽屉最下方的跳转链接,创建符合需求的事件模型。 |
- |
| 数据时间窗口 |
根据实际数据需求,设置读取原子事件数据的时间范围。 点击文本配置框,在文本框中填写具体数值,并选择时间单位,可选单位:分钟、小时、天。 |
• 设置数据时间窗口时,需在文本框中输入正整数数字; • 当时间单位为“分钟”,最大输入数字为1440;当时间单位为“小时”,最大输入数字为24;当时间单位为“天”,最大输入数字为1 |
针对“聚合事件”类型的事件模型,您可以选择配置"健康度计算"、"分组聚合"两种类型的聚合规则,适用场景如下:
› "聚合规则"配置为"健康度计算"时,聚合事件模型将基于内置聚合算法评估异常事件的严重等级、健康分数。以便在基于此类数据的应用中,帮助您从全局视角了解监控对象的健康状态,优先处理最严重的异常事件。具体应用可参考 全景图 > 创建全景图 章节。
› "聚合规则"配置为"分组聚合"时,聚合事件模型将对检测后的异常事件中的若干字段进行分组处理,归类生成异常事件消息。此类消息在后续的数据应用中将会嵌入到告警通知中,方便您在告警邮件中直接查看异常通知。
具体配置说明如下:
当"*聚合类型"配置为"健康度计算"时,"聚合规则"的配置界面如下所示:
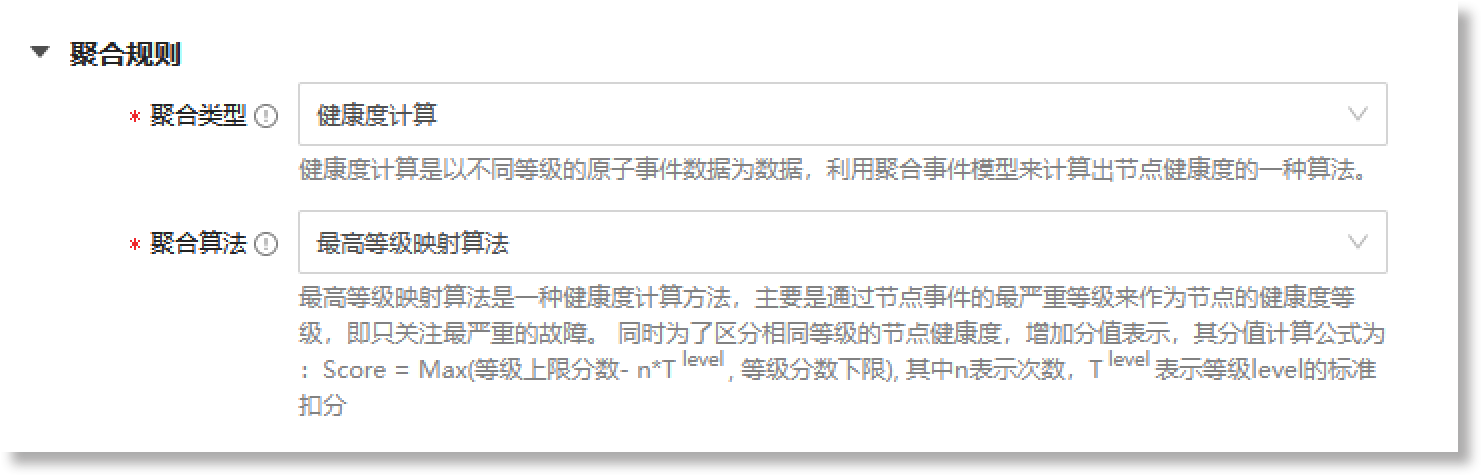
聚合事件模型的聚合规则默认采用"最高等级映射算法"。此算法是一种计算节点健康度的方法:基于不同等级的原子事件数据,将节点事件中最严重等级作为节点的健康度等级。同时,此算法也提供了用于计算健康度具体分值的计算公式(参见上图"聚合算法"提示信息),分值越低表示严重程度越高,基于此分值可以帮助区分处于同一健康度等级事件的严重性,优先处理最严重的异常事件。
当"*聚合类型"配置为"分组聚合"时,"聚合规则"的配置界面如下所示:
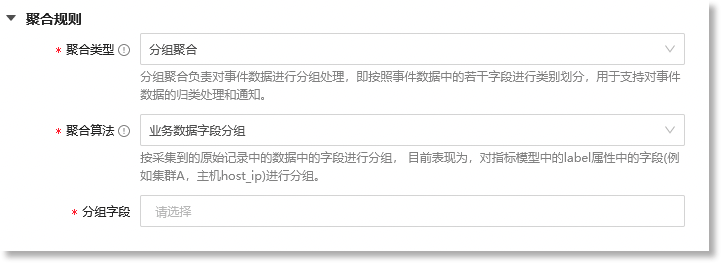
| 配置参数 | 参数说明 |
限制条件
|
| *聚合算法 |
选择分组聚合的数据来源,可选项:"业务数据字段分组"、"事件数据字段分组",具体如下: • 业务数据字段分组:按照原子事件数据中的业务字段进行分组。当前可以理解为,按照指标数据label属性(业务维度)中的字段进行分组,例如cluster,host_ip等字段; • 事件数据字段分组:按照原子事件数据本身的固定属性字段进行分组。当前可以理解为,按照事件数据中的title,type,level,event_model_id,event_model_name字段进行分组。 |
- |
| *分组字段 |
配置具体的分组字段,具体如下: • 当聚合算法选择"业务数据字段分组"时,可以选择的分组字段为原子事件数据中的业务字段,即指标数据label属性中的字段,例如cluster,host_ip等字段; • 当聚合算法选择"事件数据字段分组"时,可以选择的分组字段为原子事件数据本身的固定属性字段,即事件数据中的title,type,level,event_model_id,event_model_name字段。 |
- |
完成分组聚合后,分组后每个组别内事件数据的事件等级将由该组内严重性等级最高的事件等级决定,即严重等级最高的事件等级将作为该组的事件等级。
• 批量导入创建事件模型
进入事件模型配置页面,点击列表上方的【导入】按钮,在弹出的窗口中选中包含事件模型配置信息的文件,点击【打开】后即可批量导入并创建事件模型。
_61.png) 注意:
注意:
1. 仅支持导入json格式的文件;
2. 支持导入多个事件模型:批量导入原子事件模型时,若原子事件模型绑定的指标模型不存在,则导入操作失败;批量导入聚合事件模型时,若聚合事件绑定的原子事件不存在,则导入操作失败。您需完成模型绑定的数据来源的创建后,再进行导入操作。
3. 若AnyRobot中存有重名的事件模型对象,则导入动作将会停止,导入操作失败;
4. 批量导入失败后,您可在审计日志中查看对应的“失败”记录。
在事件模型列表中勾选某一事件模型后,点击列表上方的【导出】按钮,可将已创建的事件模型以“.json”格式导出,供其他场景快速应用,如下所示:

提示:支持导出多个事件模型。
事件模型成功创建后,您可以在AnyRobot数据应用模块直接引用事件数据资源,进一步对模型定义的事件数据进行多维度可视化分析,实现对异常事件的监控及异常告警。详情请参见 事件模型应用 章节。
► 查看/编辑/删除事件模型
进入数据管理>数据模型>事件模型配置页面,在事件模型列表中选中需查看/修改/删除的指定模型后,点击列表操作列对应的“查看/编辑/删除”按钮后,系统可分别执行对应操作。
说明:
1. 支持删除已被系统其他模块引用的事件模型,删除后,引用该模型的其他分析模块将会报错提示;
2. 事件模型被删除后,您可在审计日志中查看相应的“删除”日志。
您可以在创建、修改事件模型的过程中,点击配置页面下方的【数据预览】按钮,预览此事件模型的详情信息。您也可以在完成事件模型的配置操作后,在事件模型管理列表中点击“操作”列的“数据预览”进行查看。基于下图所示的[事件内容]信息,您可以结合实际需求及时调整事件模型的配置参数。
