Dataflow数据处理流概述
数据处理流是结合数据处理流和工作流的能力,完成数据处理自动化和业务规则协同的引擎。支持通过模版创建。它把分散任务整合为连贯流程,通过设定触发条件、流转逻辑,让任务在系统或人员间自动传递,实现业务自动化运作。
例如:在传统业务场景中,人工进行数据各种处理操作既费时又费力,且容易出错,有了自动化数据处理流,就可以对您的各种数据处理过程自动化运行,例如:数据查询、数据分析、数据存储、数据转换等等。同时,还可以运用模型以及智能体的能力,使数据处理流更加智能化,提高工作效率。
数据处理流相关概念
›触发动作:
触发动作是自动化数据处理流的起点,根据该触发动作的状态变化,来作为自动化流程是否执行的起始判断,例如上述案例中,在知识库上传一个新的文档就是流程的开始。
常见的触发动作有定时触发、事件触发、手动点击触发,下面将带您了解这几种触发动作的基本概念:
- 定时触发:触发动作为循环的时间周期或时间点,例如每x分钟、每x小时、每天或每周等固定周期。在实际工作中,有一些任务需要在特定的时间完成,主要适用于消息提醒类的场景,可以规定数据处理流运行的时间和频率。示例:文件更新后自动通知到相关人员、每周自动提醒项目负责人更新进展、定期将数据备份到指定的文件夹等。
- 事件触发:通过设置指定操作事件作为触发动作。一般适用于需要对文件和文件夹进行数据新建或变更操作的场景,也就是需要选择目标文件夹,并且在该文件夹下进行上传、复制、移动或删除的动作时,再执行下一步的操作。示例:新建文件夹时,自动将文件夹名称添加到编目模板。
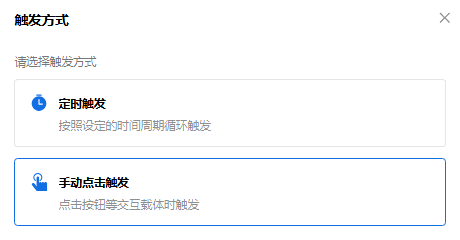
- 手动点击触发:手动触发是在设置完自动化任务后,需要您手动点击运行,才会触发下一步的执行动作。与事件触发不同,手动触发的对象是针对已经上传至某个文件夹下的文件或文件夹,再手动点击,去进行下一步需要执行的动作,主要用于数据同步的场景。示例:在文档中心里存放了一个创建时间过长的文件夹,可设置自动归档到另一个指定的文件夹。
›执行条件:
执行条件也叫逻辑动作,只有满足这个条件,才会往下执行设定的操作。通俗来讲就是数据处理流中的分支,分支的运行顺序是按照分支从左往右依次匹配,只有当前分支条件满足后,才执行该分支的流程。一个分支操作内的所有分支执行完毕后,再执行分支外的操作。上述案例中,“审核通过→文件上传”可以理解为该流程中的分支1,而如果审核不通过,则可以删除该文件,那么“审核不通过→删除文件”就是分支2。
›执行动作:
执行动作是指前面的触发动作发生,判断条件满足以后,自动让数据处理流执行指定的操作事件,例如上述案例中,满足审核通过的条件后,“文档在知识库上传发布”就是让数据处理流执行的操作。
创建数据处理流方式
- 从空白新建
- 从模版新建
从空白创建数据处理流步骤
›基本步骤如下:选择数据源→设置执行操作→设置触发器
- 第1步:点击Dataflow>管道>新建,进入数据处理流新建页面。
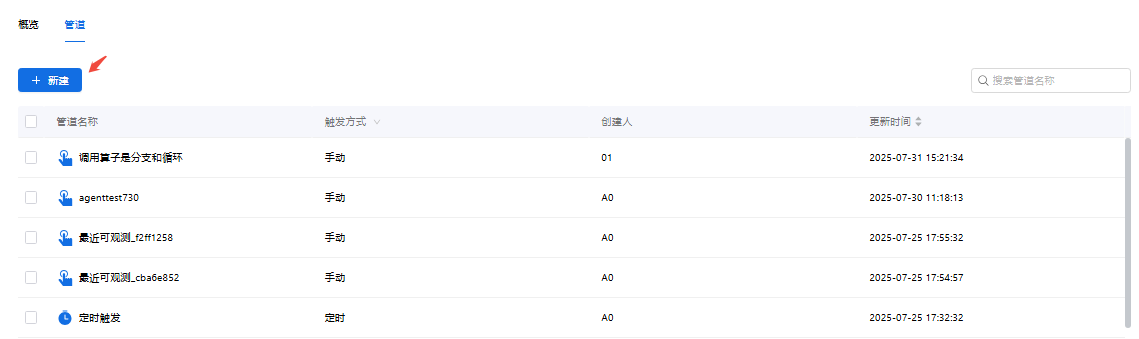
- 第2步:选择数据源,配置需要具体进行处理的数据,可选择非结构化数据、结构化数据、数据视图、填写表单触发和算子数据源。
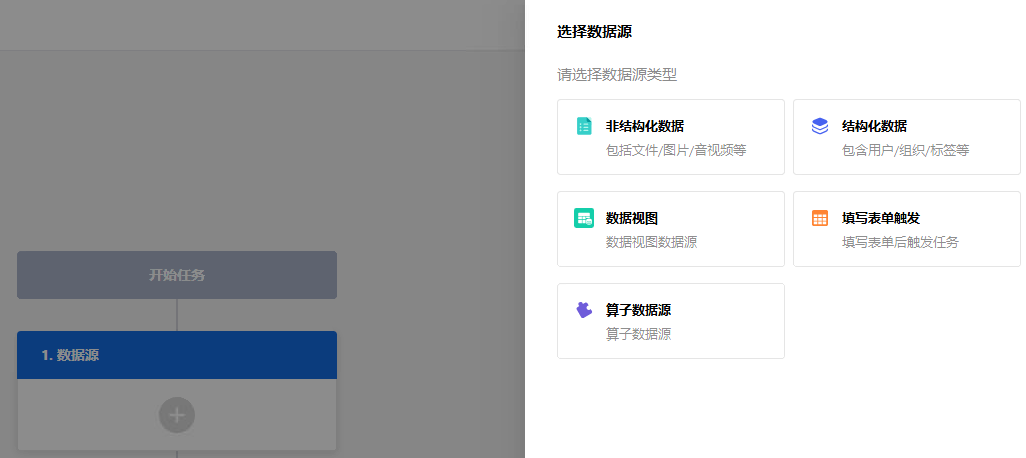
_61.png) 说明:
说明:
-
- 算子数据源:通过选择合适的算子,支持从 RESTful API 获取数据。
-
第3步:设置执行操作
执行操作是指当触发器事件发生后,用于处理数据或传递数据而执行实际的具体操作。同一个流程中,您可以设置一个或多个执行操作。
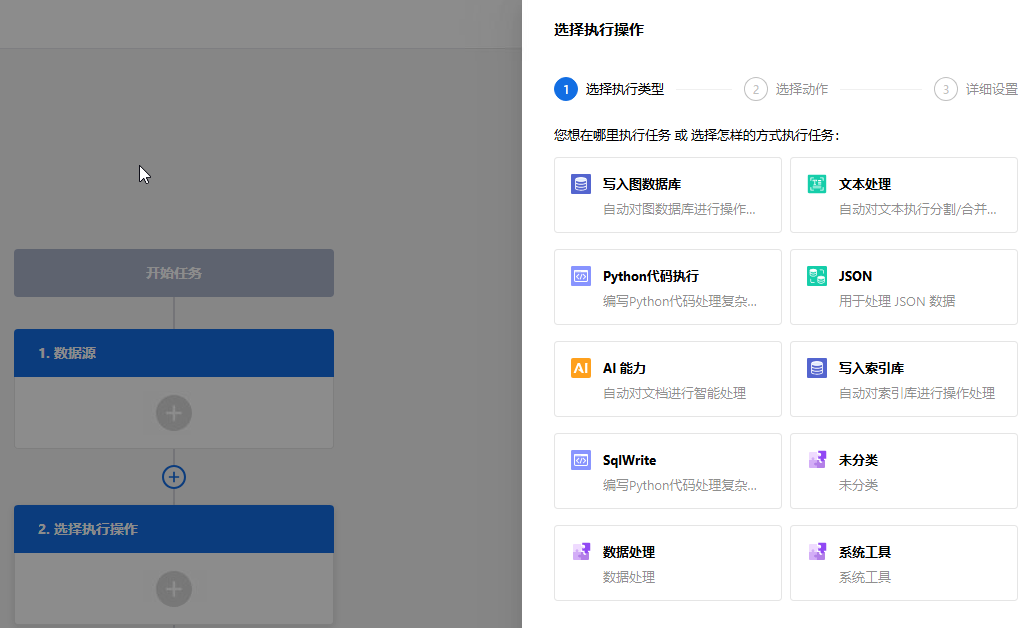
说明:写入图数据库、文本处理、Python代码执行、JSON、AI能力为系统内置执行操作;其他为外部导入。
- 第4步:设置触发器
触发器可以理解为“当某事件发生时,执行后续操作“中的某事件。在一个自动化工作流程中,触发器是自动化流程的开端,一个流程只能配置一个触发器,且不能删除。
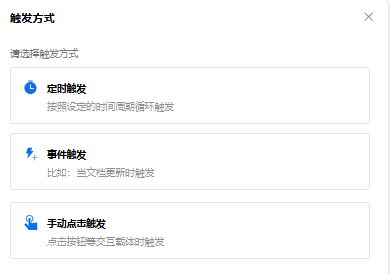
说明:当数据源为数据视图时,触发方式支持定时触发和手动触发。
从模版新建数据处理流步骤
›前提条件
- 构建相关业务知识网络
- 构建将运用到的算子
›基本步骤
- 选择业务知识网络→设置执行操作→设置触发器
›从模版创建场景示例
下文以构建数据处理流【创建用户时自动更新业务知识网络】为例,进行阐述。此数据处理流的主要目的是为了实现,当有用户新增时,自动提取用户的相关信息,进行业务知识网络更新。
- 第1步:点击Dataflow>管道>新建,进入管道新建页面,选择从模版新建
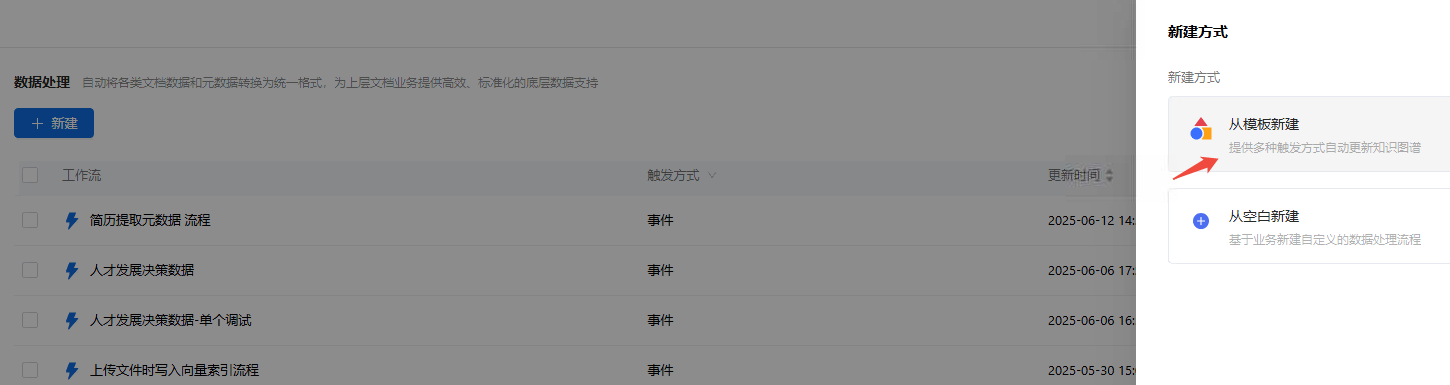
- 第4步:点击更新业务知识网络,选择【AS默认图谱_1】;选择的实体信息,图谱内所有实体信息会显示出来,根据需要进行选择;添加文档库-对文件储存的文件夹进行配置;

- 第5步:引入已经配置好的算子,点击确定;
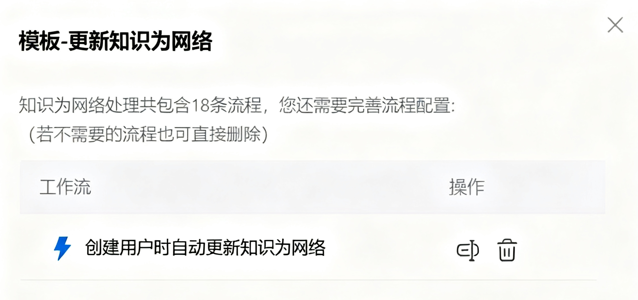
- 第6步:工作流创建成功;

- 第7步:验证-查看是否工作流新建好后,运行成功。新建用户:点击信息安全管理>用户>用户管理>新建用户;用户新建好后,回到数据处理流页面,点击运行统计。
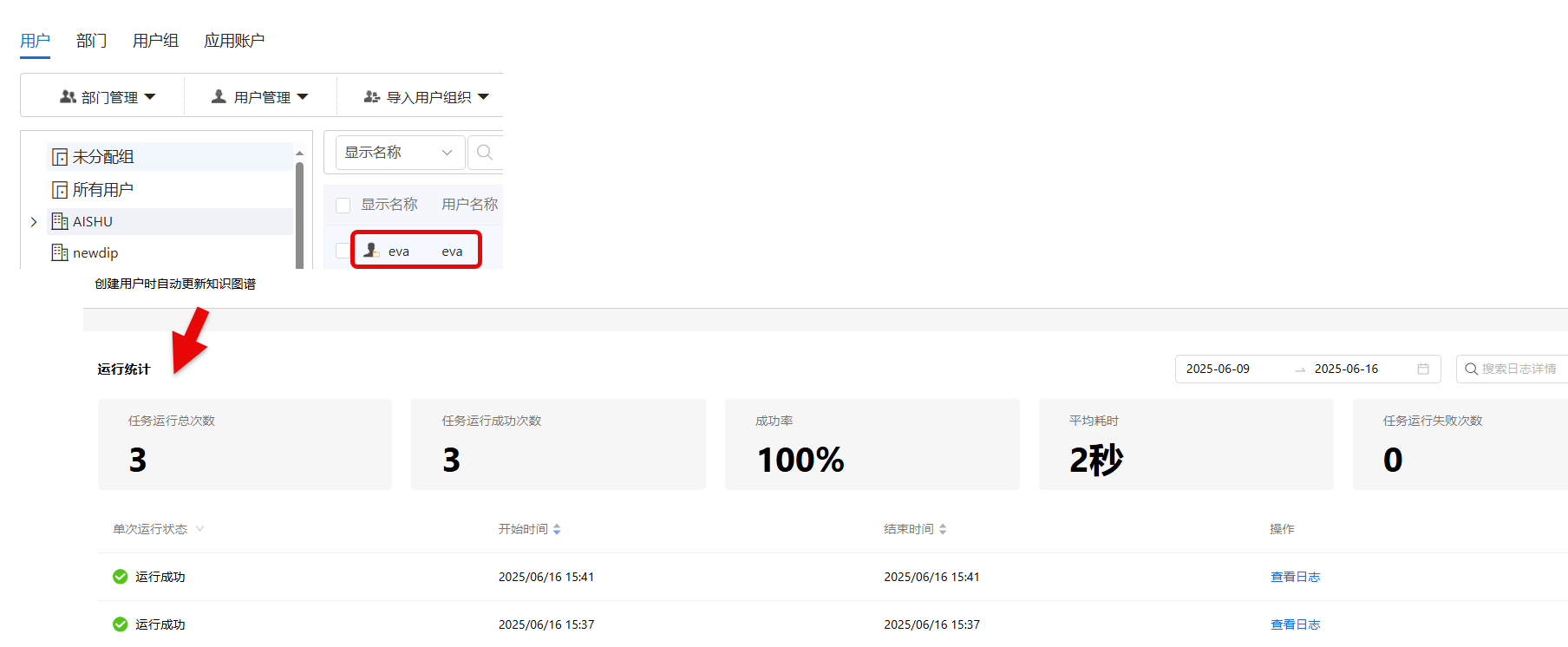
- 第8步:选择执行动作-通过此算子输出所有简历内容
- 第9步:工作流应用。此工作流创建好后,会自动运行,当有新增用户时,即更新业务知识网络;当用户在进行超级助手提问时,可以应用最新的相关信息进行问题回答。
›从空白新建场景示例
下文以数据源为数据视图为例,构建数据处理流【数据推送-新建表】,进行阐述。此数据处理流的主要目的是为了实现,根据数据源-数据视图,全量获取筛选数据,并存入新建表。
- 第1步:点击Dataflow>管道>新建,进入数据处理流新建页面,选择从空白新建
- 第2步:选择数据源,根据数据来源类型进行选择。此处选择需要进行新建表的数据来源-数据视图;
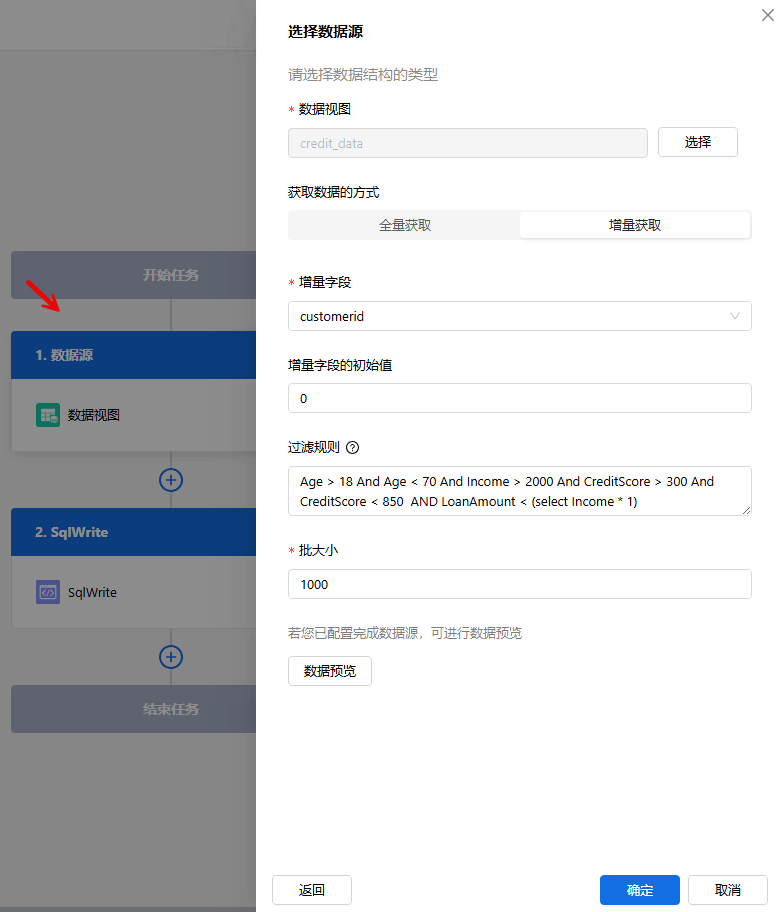
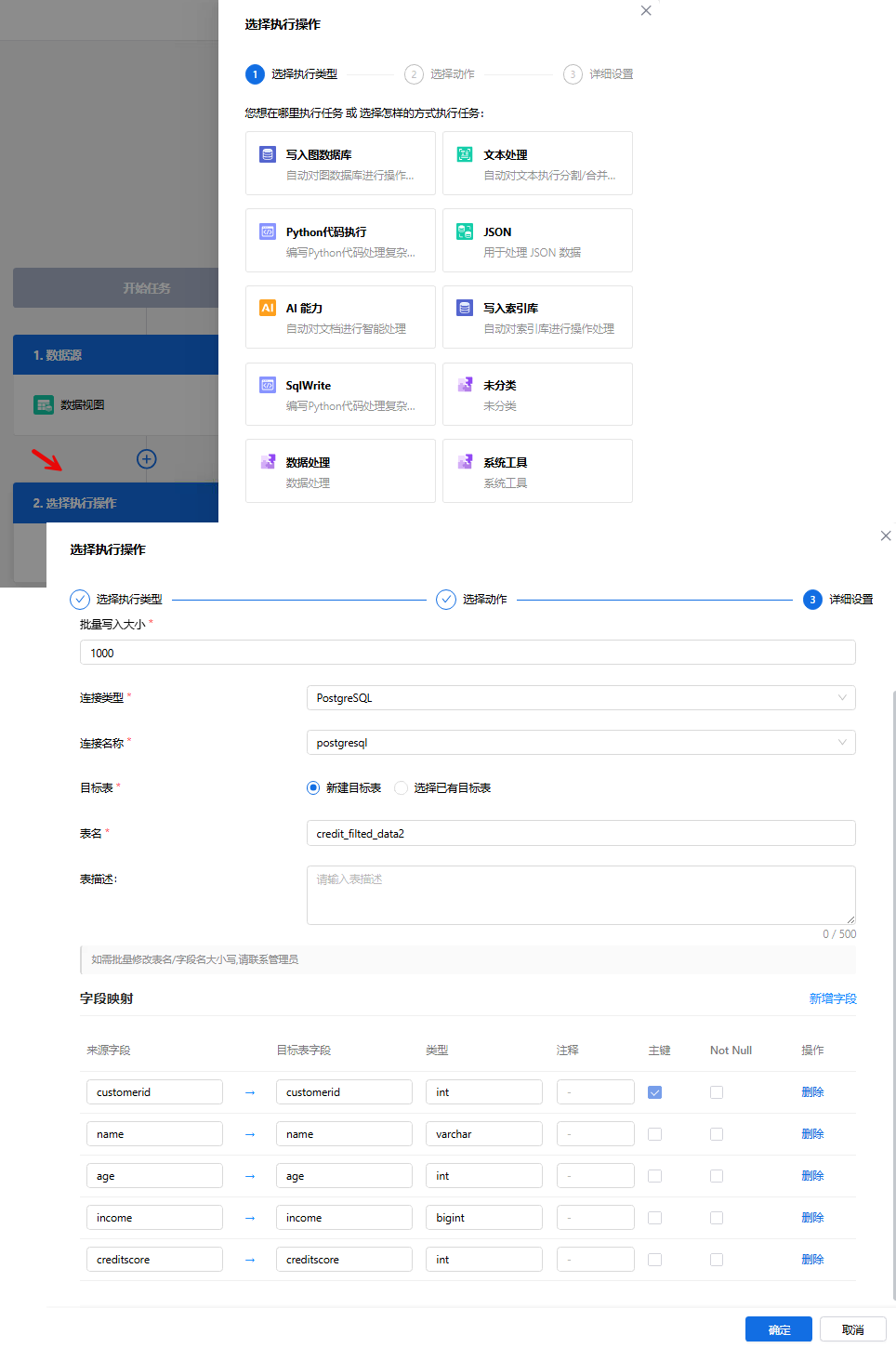
- 第3步:选择执行操作-即对相关数据源进行的相关操作。此处选择SqlWrite,对具体的数据连接信息、表格信息、字段映射信息等进行配置。
- 第4步:执行操作设置完成后,需要进行数据处理流触发条件的设置。此处选择手动点击触发。即当用户想要进行数据更新时,手动点击触发数据处理流。
重点+难点步骤详解
新建-从空白创建
选择数据源-数据视图
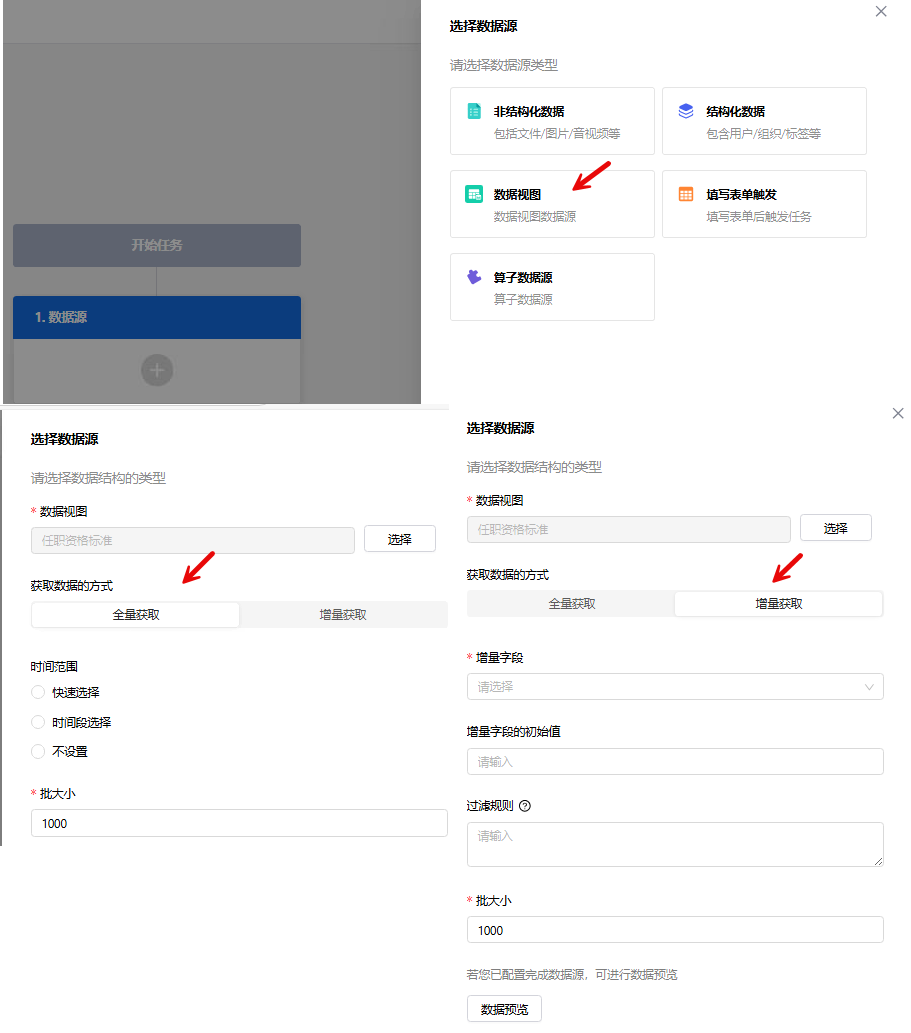
说明:
- 数据视图获取数据的两种方式:
- 全量获取:基于用户设置的时间范围,获取数据视图内全部数据
- 增量获取:基于用户设置的增量字段以及过滤规则来获取视图内的增量数据。其核心逻辑是:通过记录增量字段的最新值,在后续操作中仅获取大于该值的增量数据,并通过自定义SQL的条件进一步进行数据过滤。
- 增量字段的初始值:只有数据型字段可以被设置为增量字段,初始值可根据实际情况进行设置。如果设置为0,代表“初始状态”或“零值起点”,适用于需从零计数的场景(如版本控制、状态标记)。
- 当数据视图的查询语言为DSL时,获取数据的方式不显示,默认为全量
- 过滤规则:支持自定义筛选SQL语句WHERE条件。
- 示例: "分区" = to_char( (CURRENT_DATE - INTERVAL '1 day') ,'yyyymmdd' ) and "区域" = '275'
- 批大小:单次处理的最大数据量阈值。系统会按批次循环处理数据,直到所有数据被覆盖。输入范围为1000-10000。
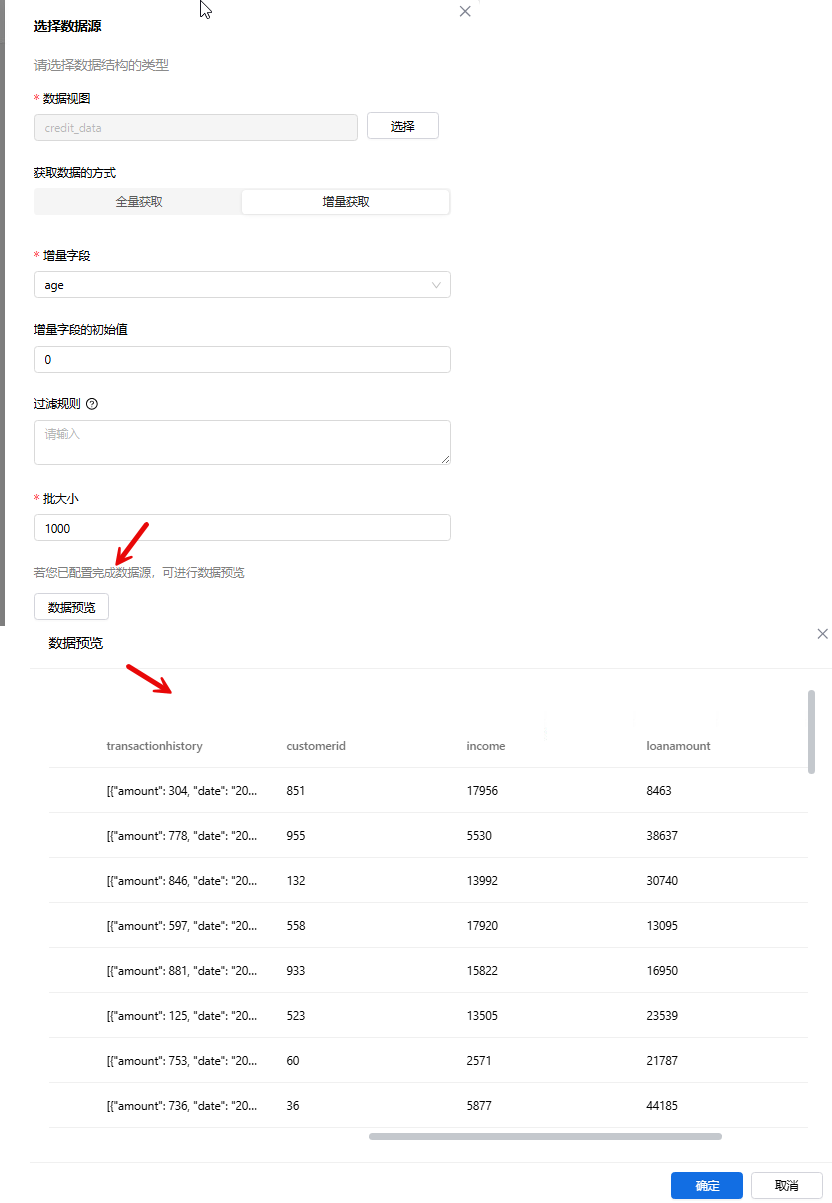
- 数据预览:数据源配置好后,可进行数据预览。如下图所示:
选择数据源-算子数据源
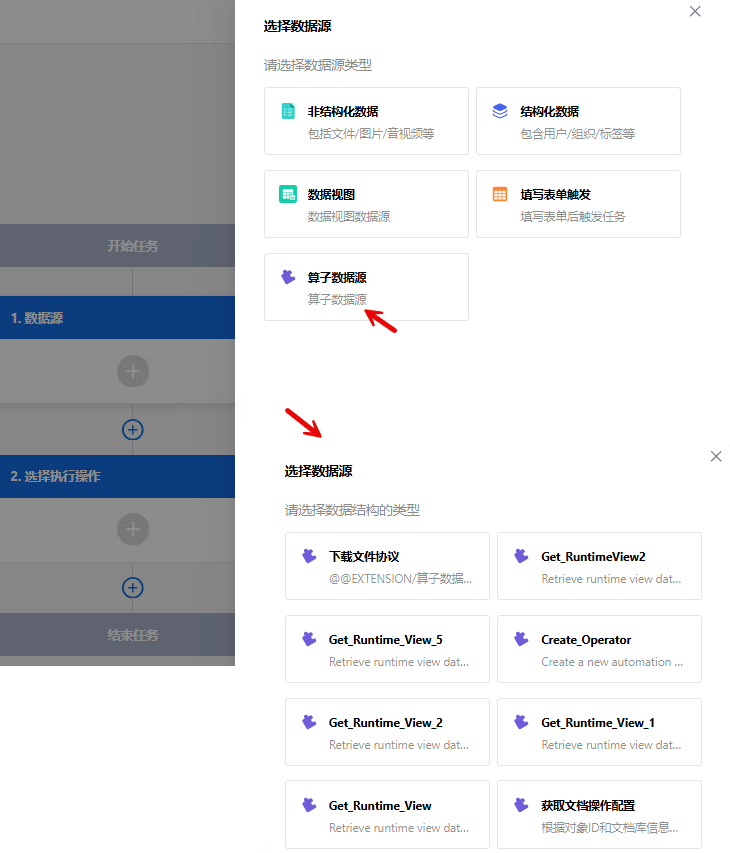
说明:
- 使用算子数据源首先需要在行动配置好相关算子,配置好的数据源算子会自动加载
- 算子数据源的算子增加数据源标识字段, 仅该标识的算子允许在数据源节点使用
- 数据源算子必须是同步算子
- 数据源节点仅允许使用全局变量,如 用户token
选择执行操作
.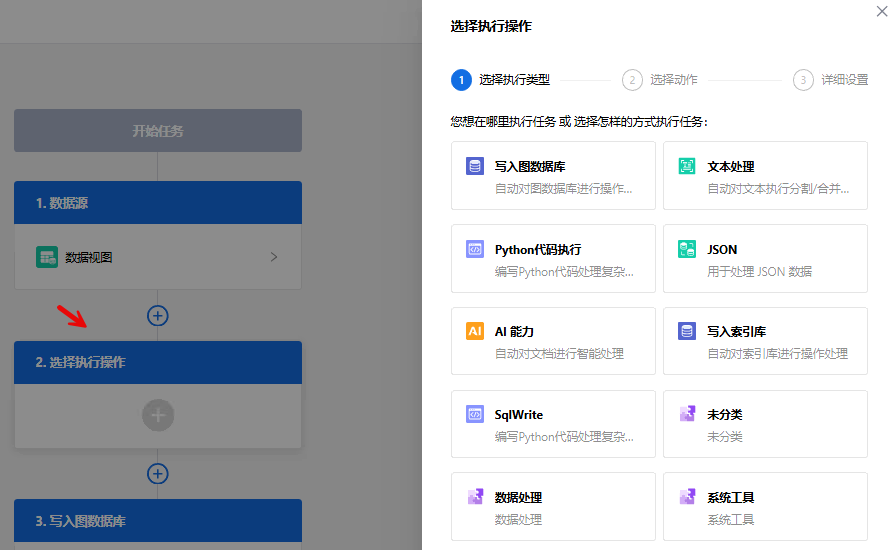
说明:
- 写入图数据库:可对内置实体包括文件、用户、组织进行写入知识网络操作;也可以对自定义实体写入指定的业务知识网络。
- 文本处理:可进行文本分割、文本合并以及提出文本内容的操作。
- Python代码执行:通过Python脚本执行复杂逻辑的自动化操作,例如:数据处理等
- JSON:用与处理JSON数据的自动化操作。
- AI能力: 通过运用大模型、智能体来进行自动化操作。
变量语法规范
部分文本框支持变量输入, 包括JSON、AI能力、写入索引库;以下说明为进行变量输入的语法规范。变量输入框示例如下图:
- 基本语法
变量使用双花括号 {{}} 包裹,例如:{{__1}} - 变量命名规则
1.变量包含全局变量和节点输出变量,全局变量命名规则为 __g_var, 例如 __g_authorization
2.节点输出变量名称为 __ID, 例如 __1 - 访问链语法
使用点号 . 访问对象属性或数组元素:
{{__1.outputs}}
{{__2.输出}} // 属性名支持中文
{{ __3.result }} // 忽略花括号内的首尾空格
- 特殊字符处理
对于包含特殊字符(如点号、空格)的属性名,使用引号包裹:
1.单引号 '
2.双引号 "
示例:
{{__0.fields.input.'a.b'}} // 包含点号
{{__0.fields.input.'a b'}} // 包含空格
- 数字处理
解析器会自动识别纯数字为数字类型:
{{__1.array.0}} // 数字0
{{__1.object.'0'}} // 字符串"0"
- 三花括号转义
使用三花括号 {{{}}} 表示原始文本内容:
{{{text}}} // 输出 "text"
{{{{text}}}} // 输出 "{text}"
{{{{{text}}}}} // 输出 "{{text}}"
- 未定义处理
{{undefined}} // 未定义变量返回 null
{{defined.undefined}} // 未定义属性返回 null - 文本拼接
花括号外的内容(包括空格)会保留:
{{var1}} {{var2}} {{var3}} // 保留前后空格
数据流导入导出
Dataflow导入
点击算子管理>导入,进入Dataflow导入页面。
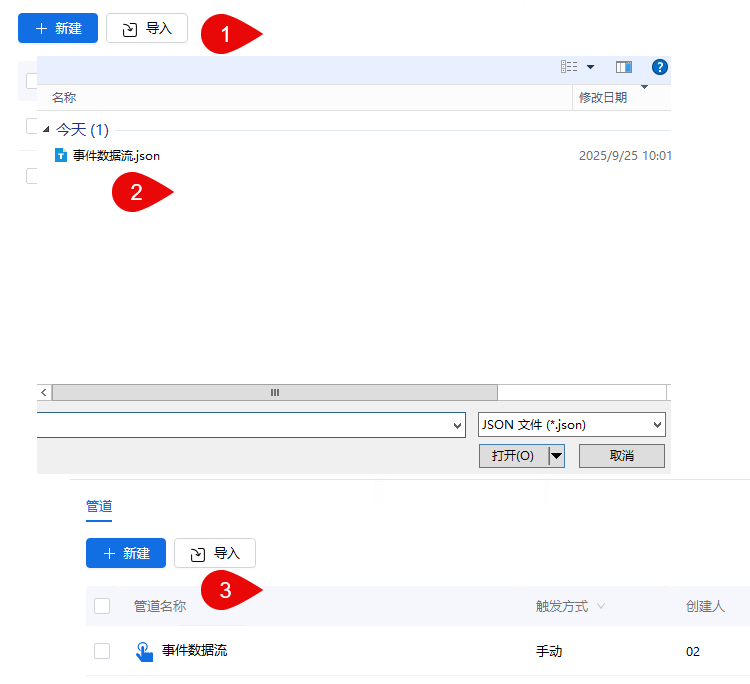
说明:
- 需导入本地文件
- 仅支持JSON格式
- 单次仅支持导入1个文件,大小不超过20M
- 需具备新建权限
- 若导入时包含算子,但此算子在系统内并不存在,则可导入成功,导入后的Dataflow配置中该算子节点为空
- 若导入的过程中,发现Dataflow名称与已有Dataflow同名,则自动重命名,名称后缀加(1)、(2)、(3)……以此类推
Dataflow导出
点击数据处理流,进入Dataflow管理页面,勾选预导出的Dataflow, 点击导出即可。如下图所示:
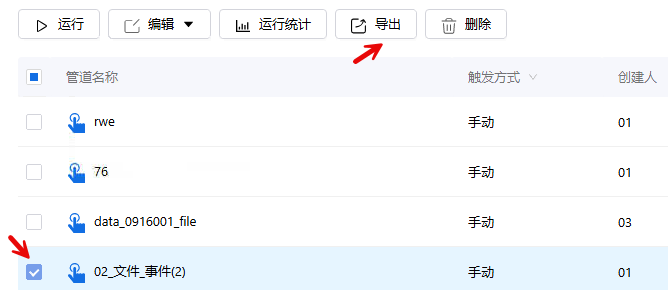
说明:
- Dataflow导出仅支持单选
- 用户需具备流程查看权限
- 导出为json/zip格式文件
- 若导出的Dataflow中包含算子,但用户无算子的导出权限,则导出的Dataflow中该算子节点为空