模型接入
模型接入是指将外部的大语言模型(如ChatGPT等)或推理语言模型等相关模型,通过特定的配置和连接方式集成到系统中,使其能够在该系统内被调用和使用。通过模型接入,使自身系统能够进行功能扩展、提升在处理任务上的性能表现以及节省模型开发时间和成本等。
大模型接入
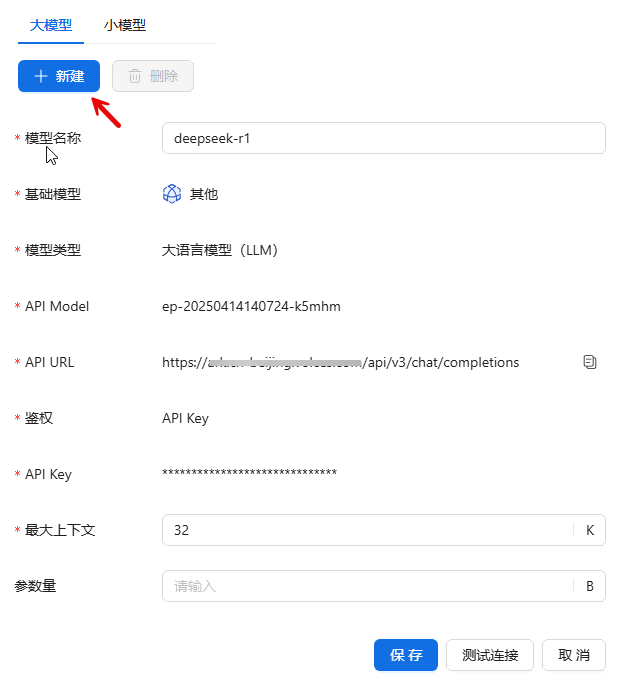
进入模型管理页面,点击后台管理>模型管理>大模型>新建,填写相关配置信息,点击测试连接;如果测试连接成功,点击保存。
_61.png) 参数说明:
参数说明:
›模型类型
-
- 大语言模型(LLM):以海量文本数据训练,具备出色语言处理能力,可用于文本创作、语言翻译等文本处理任务。
- 推理语言模型(RLM):在语言模型基础上强化逻辑推理,适用于数学问题解答、逻辑验证等需深度推理的场景。
- 视觉理解(VU):专注视觉内容分析,能识别物体、场景、行为等,用于图像识别、视频监控分析等场景。
›API Model:用于指定接入模型所对应的特定应用程序接口模型标识,帮助系统准确识别和调用对应的模型服务。
›API URL:模型提供服务的应用程序接口的网络地址,通过该地址系统可以与模型进行数据交互。
-
- AISHU大模型填写格式:http://ip:端口/版本号/chat/completions
- 例如:http://192.xxx.xxx.11:18302/v1/chat/completions
- AISHU大模型填写格式:http://ip:端口/版本号/chat/completions
›鉴权:验证用户或系统是否有权访问模型,保障模型服务安全,防止非法调用。
-
- API Key即应用程序接口密钥,它是服务器用来识别和验证调用API的客户端身份的一种方式。相对简单易用,由于其以明文传输,存在一定的安全风险。
- Dual Key“双密钥”,是一种比单一API Key更安全的鉴权机制。它通常涉及两个不同的密钥,分别用于不同的鉴权阶段或具有不同的权限等场景。安全性更高,其配置和使用相对复杂。
›最大上下文:模型一次能处理的文本长度上限,影响对长文本的理解和处理能力。
›参数量:模型内部可调整参数的数量,体现模型复杂度,参数量大通常能力更强。
大模型其他操作
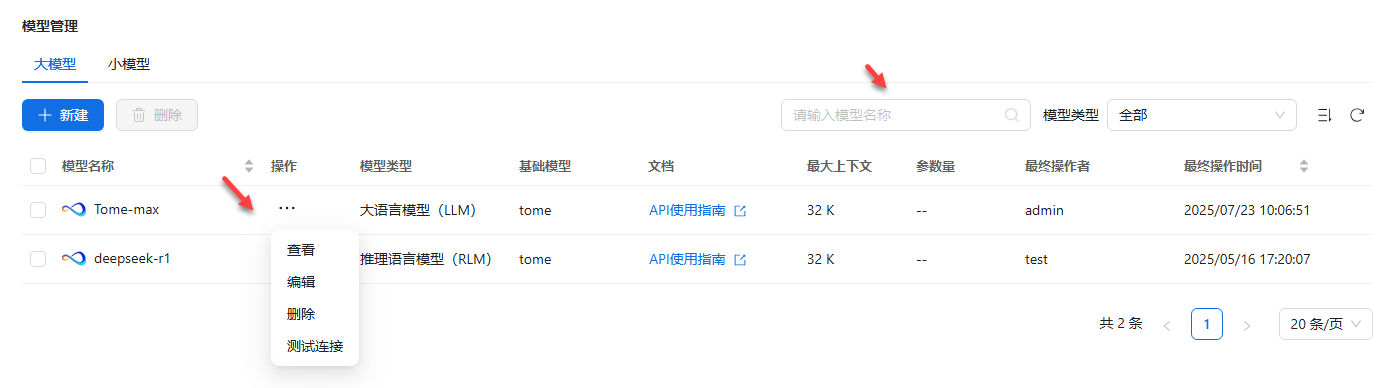
进入模型管理主页,点击大模型![]() 可以进行模型查看、编辑、删除、测试连接等操作;还可以通过模型类型进行筛选,通过模型名称进行搜索。用户还可通过API使用指南,进行API调用或使用SDK进行开发。
可以进行模型查看、编辑、删除、测试连接等操作;还可以通过模型类型进行筛选,通过模型名称进行搜索。用户还可通过API使用指南,进行API调用或使用SDK进行开发。
小模型接入
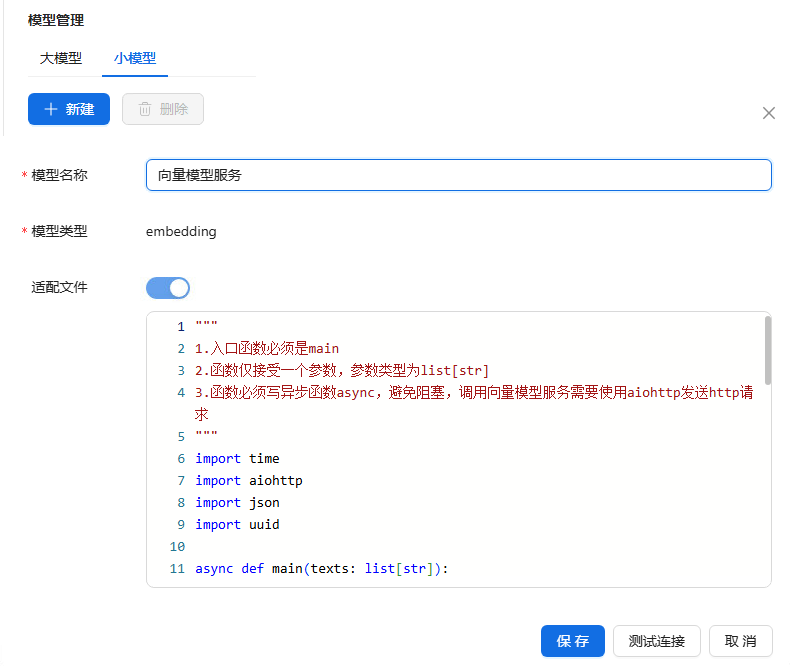
进入模型管理页面,点击小模型>新建,填写相关配置信息(以下以选择适配文件的场景来做说明)。点击测试连接;如果测试连接成功,点击保存。
参数说明:
›模型类型
-
-
内置Embedding小模型:提供文本、图片等数据转换为向量表示的能力。
- 内置Reranker小模型:提供对搜索的结果按与问题的相关度重排序的能力。
-
›适配文件:
-
- 注释说明:阐明函数定义规范,包括入口函数名、参数类型及异步要求,为开发者提供使用指引。
- 库导入:引入时间、异步 HTTP 请求、JSON 处理及唯一标识符生成库,为后续功能实现提供基础支持。
- 主函数定义:定义异步主函数,明确接受文本列表参数,作为程序执行的入口点。
- 请求配置:设定服务地址、请求头及请求体,为与 embedding 服务通信做好准备。
- 请求发送与响应处理:利用异步客户端发送请求,检查状态码,成功时解析响应为 JSON 格式。
- 响应体构建:将 embedding 结果封装为标准 openai 风格响应体,涵盖对象、数据、模型等多方面信息。
- 结果返回:把构建好的响应体返回,以便调用者获取并使用 embedding 处理结果。

说明:爱数小模型的常规配置请参考大模型接入配置说明,关于爱数小模型接入的API URL填写格式为:http://ip:端口/版本号/模型类型,示例如下:
- http://192.xxx.xxx.11:18302/v1/embeddings
- http://192.xxx.xxx.11:18302/v1/rerank
小模型其他操作
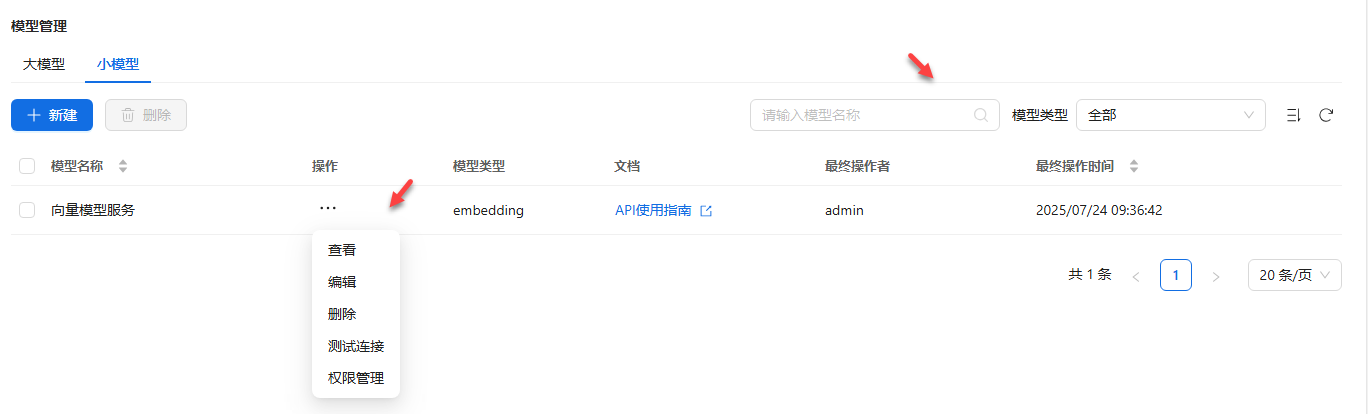
进入模型管理主页,点击小模型![]() 可以进行模型查看、编辑、删除、测试连接等操作;还可以通过模型类型进行筛选,通过模型名称进行搜索。用户还可通过API使用指南,进行API调用。
可以进行模型查看、编辑、删除、测试连接等操作;还可以通过模型类型进行筛选,通过模型名称进行搜索。用户还可通过API使用指南,进行API调用。
- 权限管理
进入模型管理主页,点击小模型![]() ,可以进行模型权限管理操作。填写好配置内容后,点击确定。
,可以进行模型权限管理操作。填写好配置内容后,点击确定。
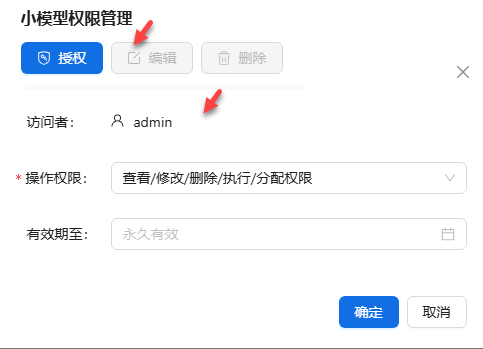
模型授权成功后,自动返回权限管理主页,可查看此模型的权限配置详情。
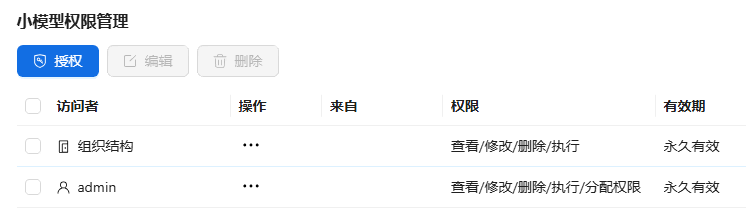
模型监控
随着大模型(如语言模型)和小模型(如embedding、rerank、OCR、speech等服务)的广泛应用,模型服务的稳定性和性能成为业务成功的关键。模型监控功能旨在实时跟踪模型服务的运行状态,确保高可用性,并通过流量分析优化资源分配和用户体验。
- 可用性:
服务是否在线运行(健康检查结果(HTTP状态码、连接成功率)、响应时间)
故障率(错误响应比例)
服务恢复时间(MTTR) - 性能:
响应时间(端到端延迟,包括推理时间和网络延迟)
吞吐量(每秒处理的请求数)
资源利用率(CPU、GPU、内存使用率) - 流量:
请求量(总请求数、每分钟请求数)
峰值流量(高负载时间段的请求分布)
用户分布(按地域、设备类型或应用类型划分)
告警规则设计
可用性规则:
- 服务响应时间>1秒视为异常,进行告警。
- 连续5分钟无响应视为服务不可用。
- 错误率>5%触发告警。
- GPU资源利用率>80%触发优化建议。
流量规则:
- 流量激增(>历史均值2倍)触发告警。
- 并发量超过预设阈值触发资源扩容,扩展副本数。
- 并发量超过预设阈值80%,触发告警
性能规则:
- 向量生成速度低于阈值,触发告警
- 大模型首字延时低于阈值,触发告警
- 大模型TPS低于阈值,触发告警(每个模型阈值不同,默认不设置阈值)
- 字符识别率低于阈值,触发告警
- 语音识别率低于阈值,触发告警
- 语音实时性低于阈值,触发告警
- 图像处理速度低于 阈值,触发告警
(注:以上为模型监控的总体规划)目前实现情况如下:
模型监控查看
通过后台管理:点击管理后台>模型管理>大模型,选择预查看模型监控的大模型,点击![]() 模型监控即可。如下图所示:
模型监控即可。如下图所示:
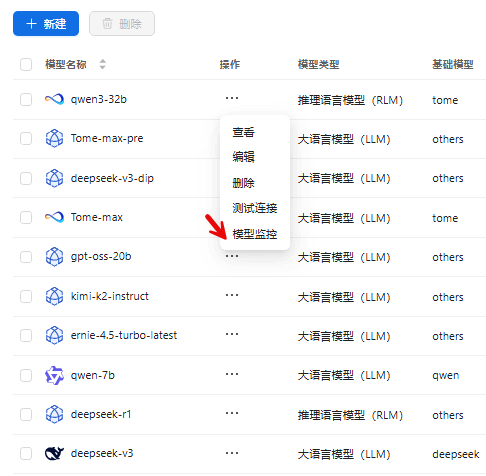
此模型监控结果如下图所示:

输出速度与Tokens吞吐量的区别说明:
- 输出速度:大模型的生成答案的速度
- Tokens吞吐量:用户问大模型的问题+大模型的输出答案二者之和的速度