一、Proton ECeph部署问题
1.1、proton-ceph-config-manager启动失败,报数据库连接错误
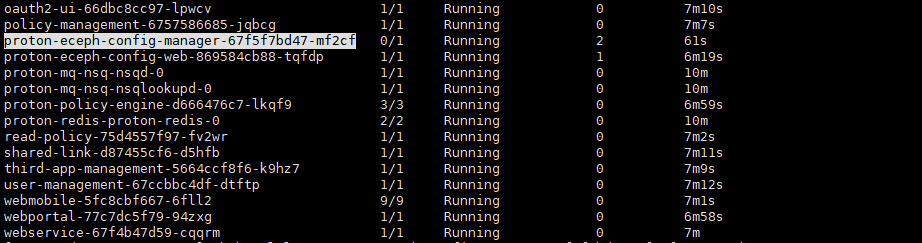
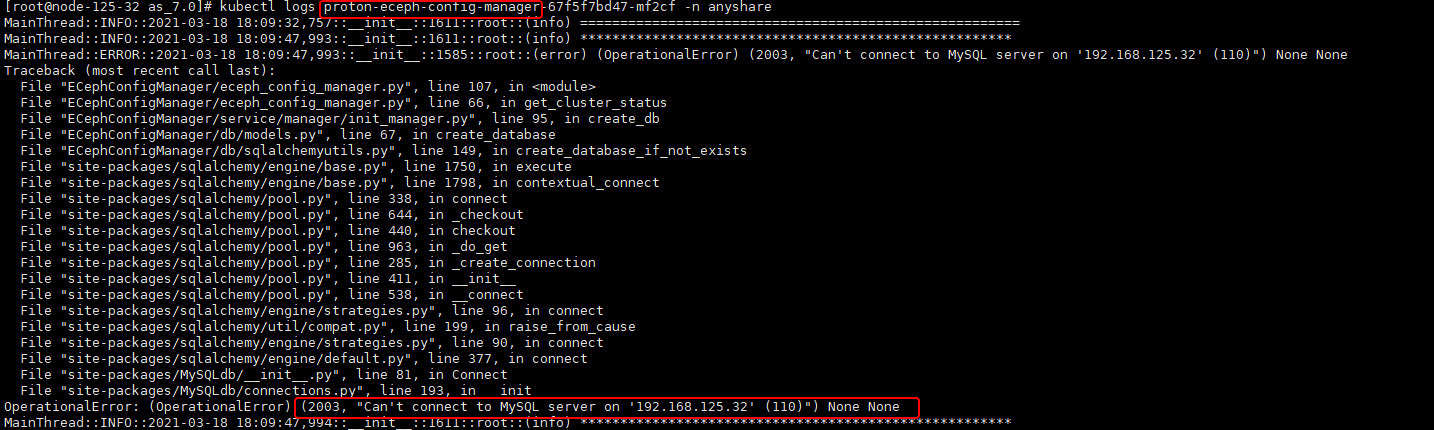
解决:检测数据库服务及其连通性是否正常。
二、ProtonECeph集群初始化失败
2.1、集群初始化时报错:connection failed,please check if minotaur daemo is operational(eceph-config-manager连接不上数据库)

管理程序分为前端页面(pod:proton-eceph-config-web)和后台服务(pod:proton-eceph-config-manager)。上述问题说明后端服务有问题。因此要检查proton-eceph-config-manager是否正常。
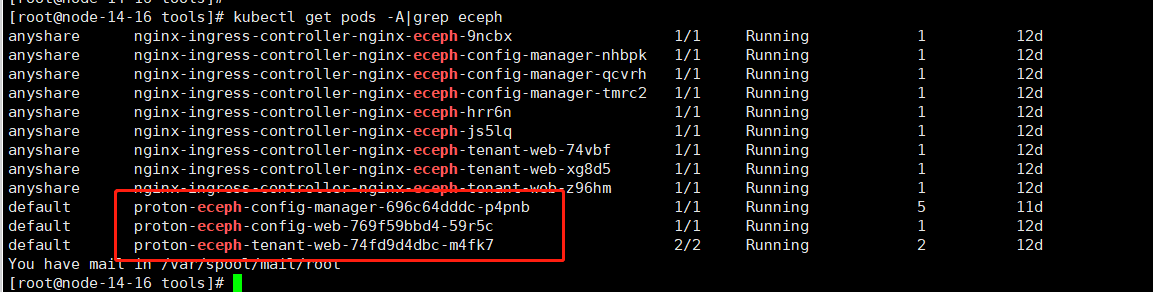
如果状态不是running,使用kubectl describe pods/proton-eceph-config-manager-xxxx-xxx查看失败原因:
- 如果是init的容器启动失败
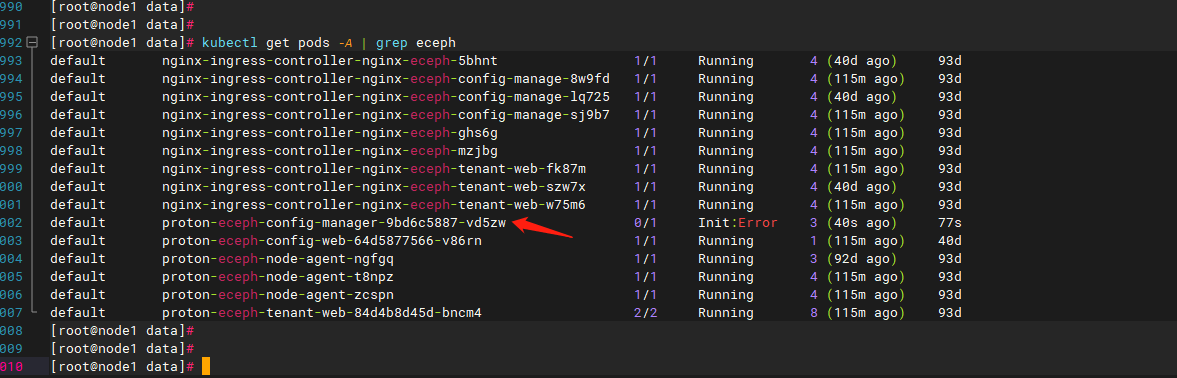
查看init容器日志:kubectl logs proton-eceph-config-manager-xxxx-xxx -c proton-eceph-config-manager-init
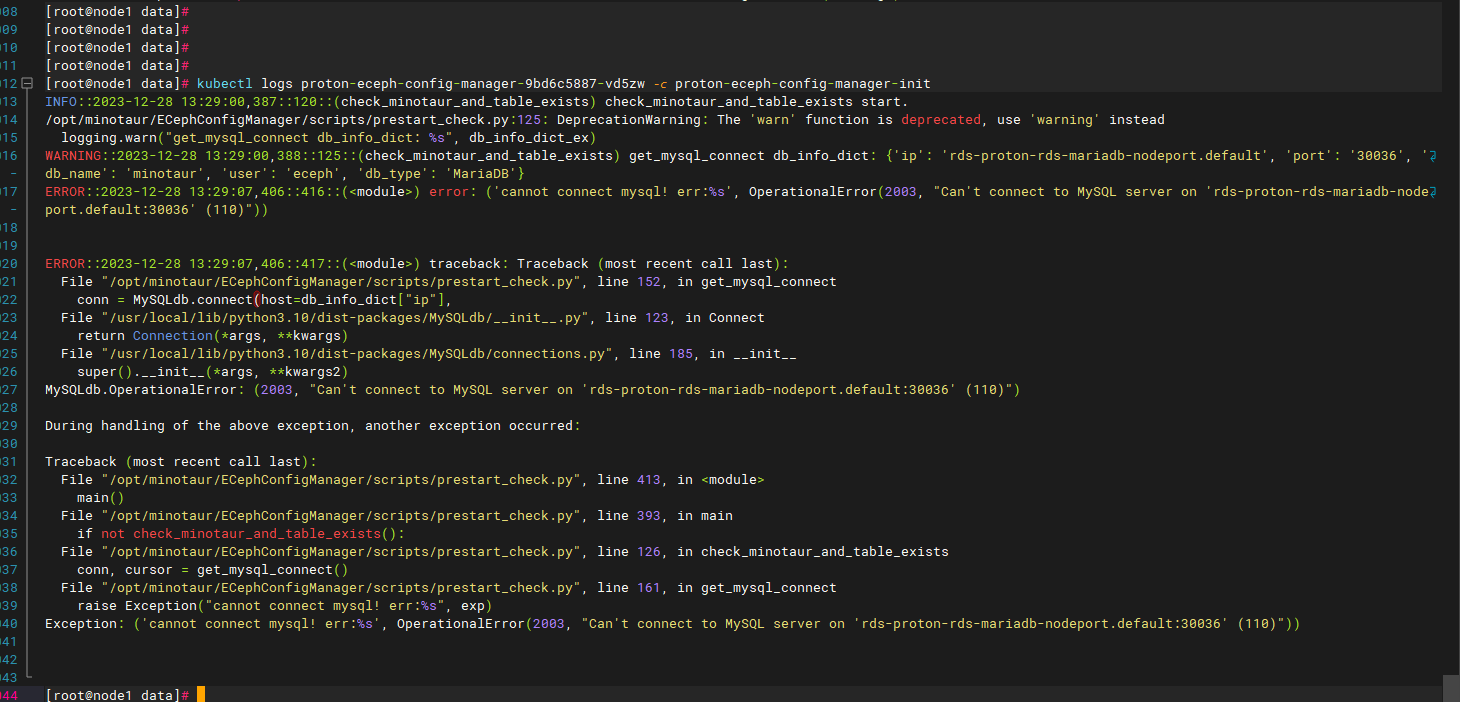
解决:检测数据库服务及其连通性是否正常。 - 如果是服务启动失败,则使用kubectl logs proton-eceph-config-manager-xxxx-xxx查看后端服务启动日志。
2.2、集群初始化时报错:Process Execute cmd Error(keyring配置失败)
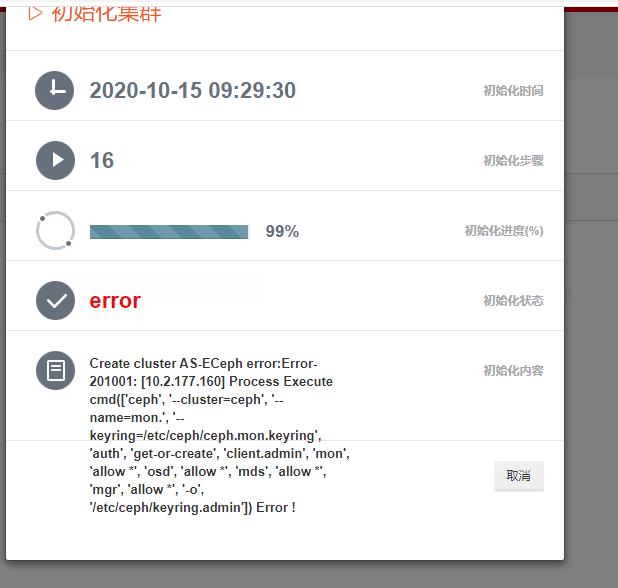
集群初始化过程中,集群中多个节点需要相互通信(使用内部IP),如果通信失败,则会报错。以上错误则是通信失败导致。
- 查看ceph管理程序配置的内部IP:cat /opt/minotaur/config/minotaur.conf,找到internal_ip字段
- 运行 ip a查看internal_ip对应的IP是否配置上
- 如果internal_ip配置了,检查防火墙,确保集群中其他节点IP和内部IP在本节点防火墙列表中。如下:
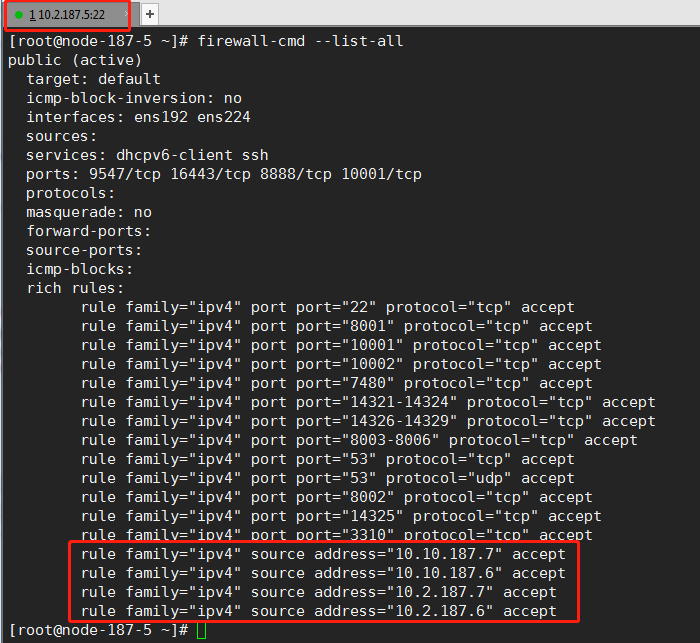
- 添加防火墙的命令:
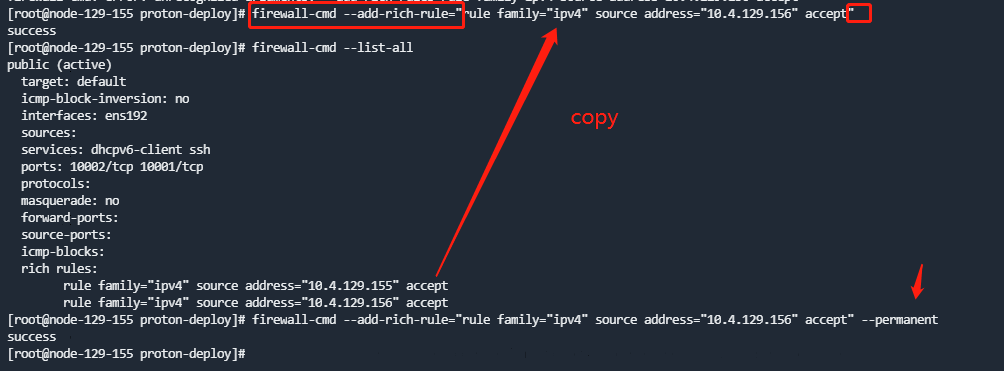
firewall-cmd --add-rich-rule="rule family="ipv4" source address=${ip} accept";
firewall-cmd --permanent --add-rich-rule="rule family="ipv4" source address=${ip} accept"
可以直接复制已有的命令,改一下IP,用--add-rich-rule参数。不加--permanent表示临时的/马上生效的,--permanent表示永久的。
- 修改防火墙之后,WEB页面可能会无法登陆,此时参考【3.1】处理方法。
2.3、集群初始化时报错:[节点ip] 磁盘不存在
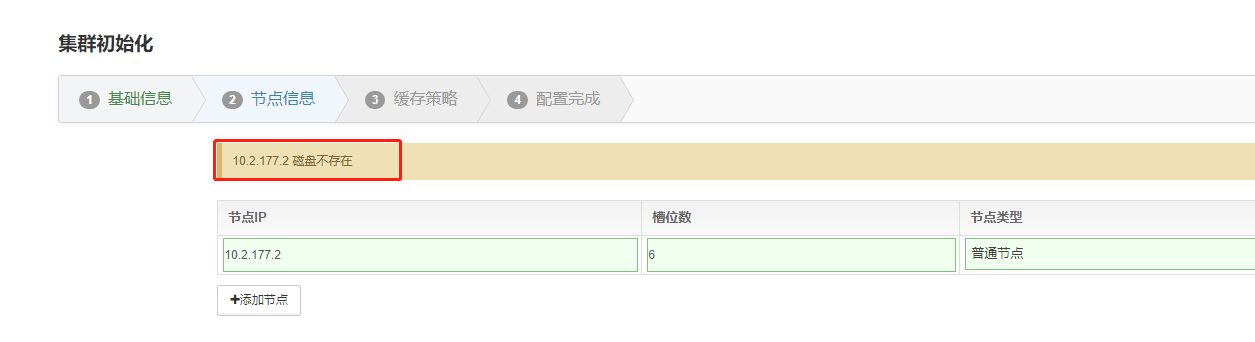
如果是多节点集群,可以运行kubectl logs proton-eceph-config-manager-xxxx-xxx查看后端服务启动日志,看具体是哪个节点检查不到磁盘。也可以每个节点都检查下是不是管理程序都不能识别到磁盘。检查步骤如下:
-
运行lsblk,确认系统可以识别到磁盘(eceph会自动将系统盘以外的盘作为数据盘,格式化后用来存储上传的文件)
-
如果是虚拟机环境,确保设置了UUID:
- 关闭虚拟机-->编辑虚拟机配置-->选项-高级
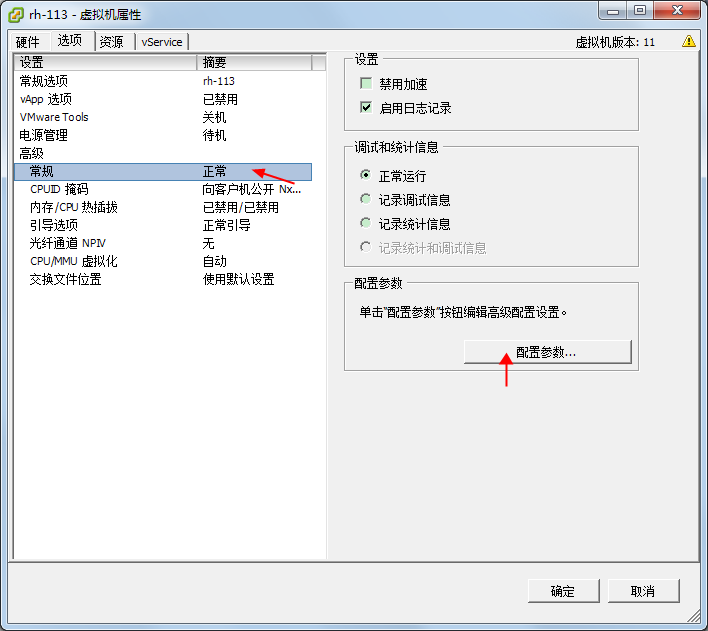
- 增加一行disk.enableUUID,值为true

- 关闭虚拟机-->编辑虚拟机配置-->选项-高级
-
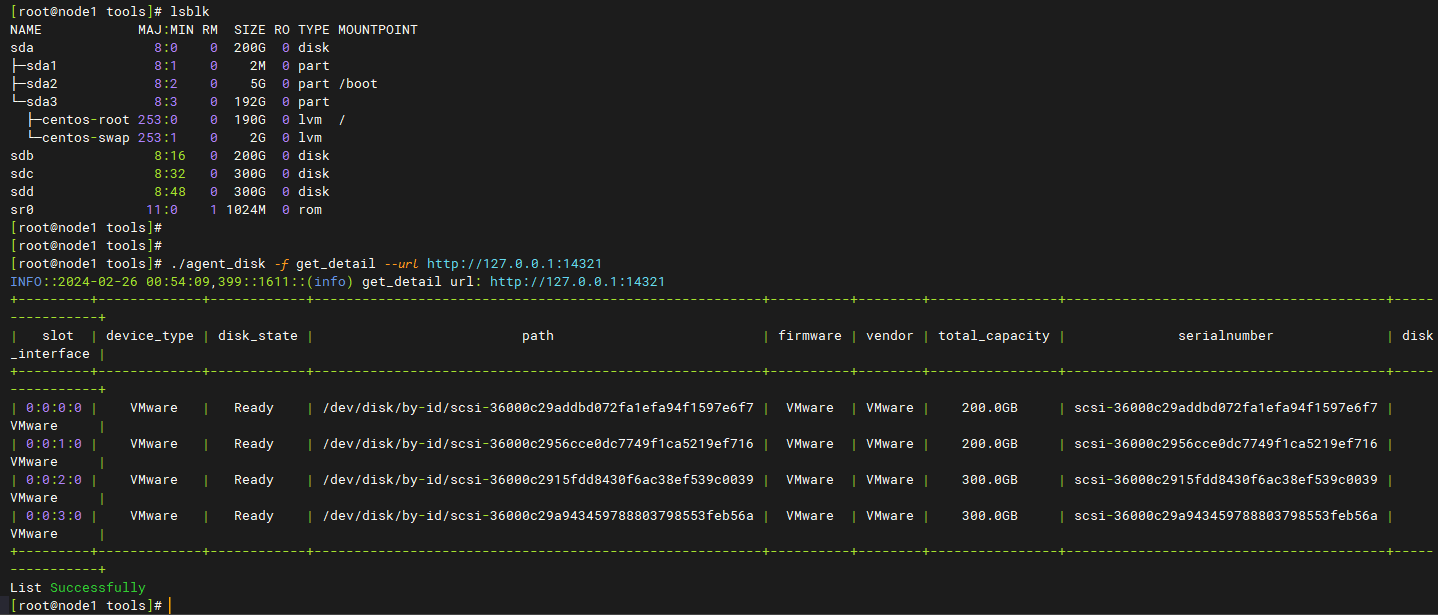
如果系统可以看到盘,再检查agent节点上的eceph管理程序是否可以识别到磁盘
cd /opt/minotaur/tools/ python agent_disk.py -f get_detail --url http://127.0.0.1:14321 (或者./agent_disk -f get_detail --url http://127.0.0.1:14321 )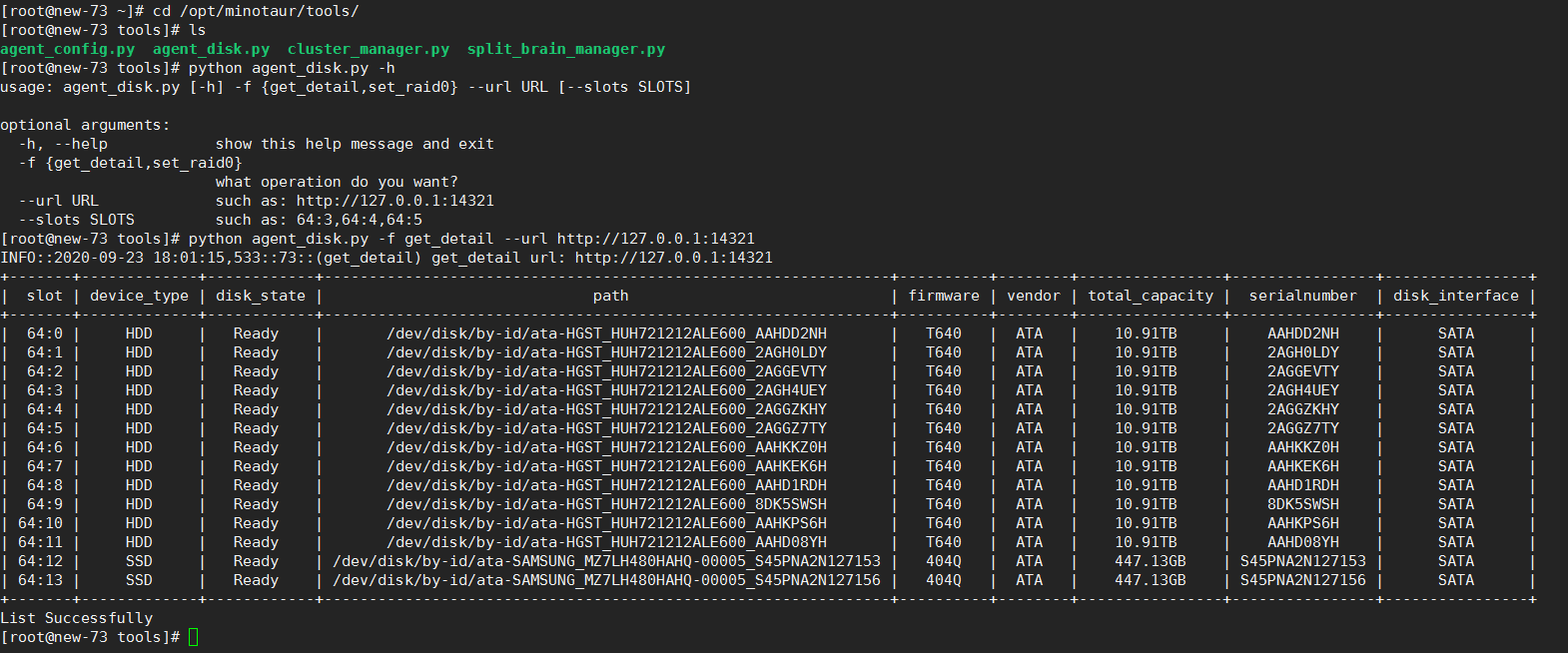
-
系统可以识别磁盘,但是管理程序不能,需要检查raid卡:
- vmware虚拟机需要设置开启uuid
- 物理机支持的Raid卡(lspci|grep LSI查看):
- LSI 2208/3108,要求每块磁盘做raid0,或者使用管理工具:
python agent_disk.py -f set_raid0 --slots 32:0,32:1,32:2 --url http://127.0.0.1:14321 - 3108查看机框closure id和磁盘id: MegaCli64 -pdlist -aALL
- 设置raid0失败,可以先disable一下JBOD设置raid0失败,如果确认系统盘是已经做了raid的,可以先disable一下JBOD模式:MegaCli64 -AdpSetProp EnableJBOD -0 -aALL。慎用!!!若系统盘是JBOD模式,该命令会导致系统盘无法访问。需要进入raid卡改回JBOD模式。此时需要去raid卡界面手动配置raid0。
- LSI 2308/3008,要求磁盘为直通模式
- LSI 3408/3508,raid0或直通都可以(选择一种,不要混用),但是建议直通(即设置Jbod)。MegaRaid有比较多的系列,可以先看下管理程序是否识别该系列:
- 查看/opt/minotaur/log/agent.log,搜索14321,服务启动时,会显示识别到的raid卡信息。
- 其它系列的,可以先尝试使用MegaCli或者storcli获取磁盘信息(命令可参考:磁盘管理命令分析),管理程序使用这两个工具管理磁盘,若这两个工具可以使用,理论上管理程序可以支持:
- MegaCli64查看物理盘信息,物理盘列表:
MegaCli64 -pdinfo -physdrv[E:S] -aALL
MegaCli64 -pdlist -aALL - storcli64 查看磁盘信息:storcli64 /c0 show
说明:工具所在目录为/opt/MegaRAID
- MegaCli64查看物理盘信息,物理盘列表:
- LSI 2208/3108,要求每块磁盘做raid0,或者使用管理工具:
-
如果是管理程序不能支持的raid卡,请咨询爱数技术支持。
2.4、集群初始化时报错:[节点ip] some osd not start
- 查看agent日志(/opt/minotaur/log/agent.log),搜索Some Osd Not Started,查看是哪块磁盘报错:
说明:如果是ECeph 7.10.0及之后的版本,查看proton-eceph-node的pod的容器日志

这里看到是osd0启动失败,搜索osd0,找到对应的磁盘:

用命令ls -l列出该磁盘,查看该磁盘是否被其他服务/目录占用,若有,先暂停相关服务或移除相关目录。或者有其他分区,请删除分区后(fdisk 命令)再重新初始化。


磁盘容量太小也报该错误,osd目录下会放置一个5G的journal文件,因此磁盘需要大于5G(即使不怎么存数据,也建议设置10G+) - 若agent日志报错如下:

查看/usr/lib/systemd/system 目录下ceph-osd@.service文件是否存在,不存在的话osd 无法正常启动; - 若在node-agent服务已经运行之后,进行了添加磁盘的操作,ECeph 7.15.0及之前的版本需要重启node-agent服务。
重启命令:kubectl get po -A|grep node-agent |awk '{print$2}' | xargs -i kubectl delete po/{}
agent日志报错如下:
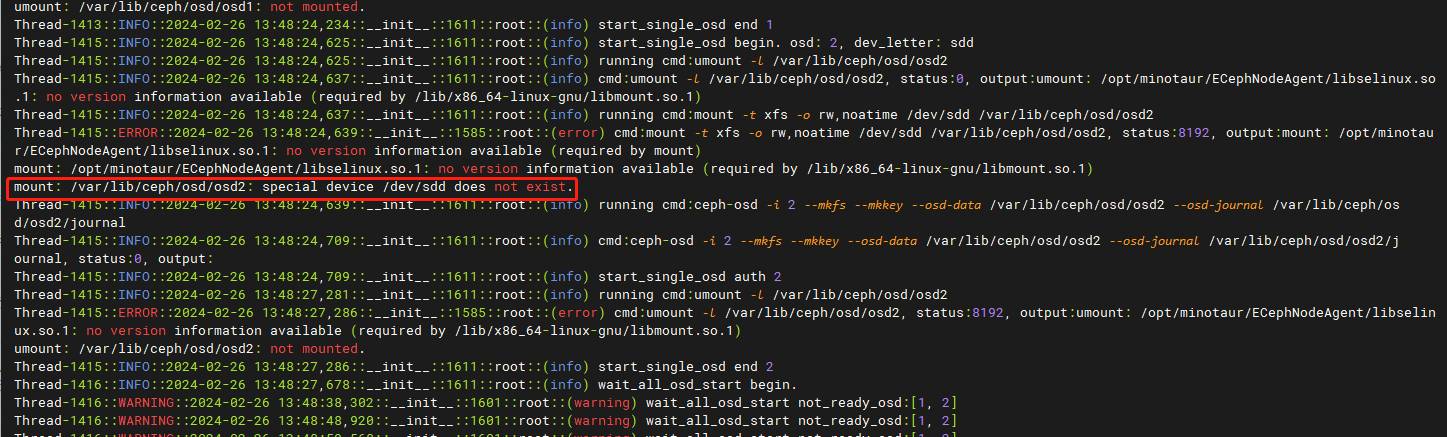
使用lsblk命令和agent_disk脚本获取磁盘正常
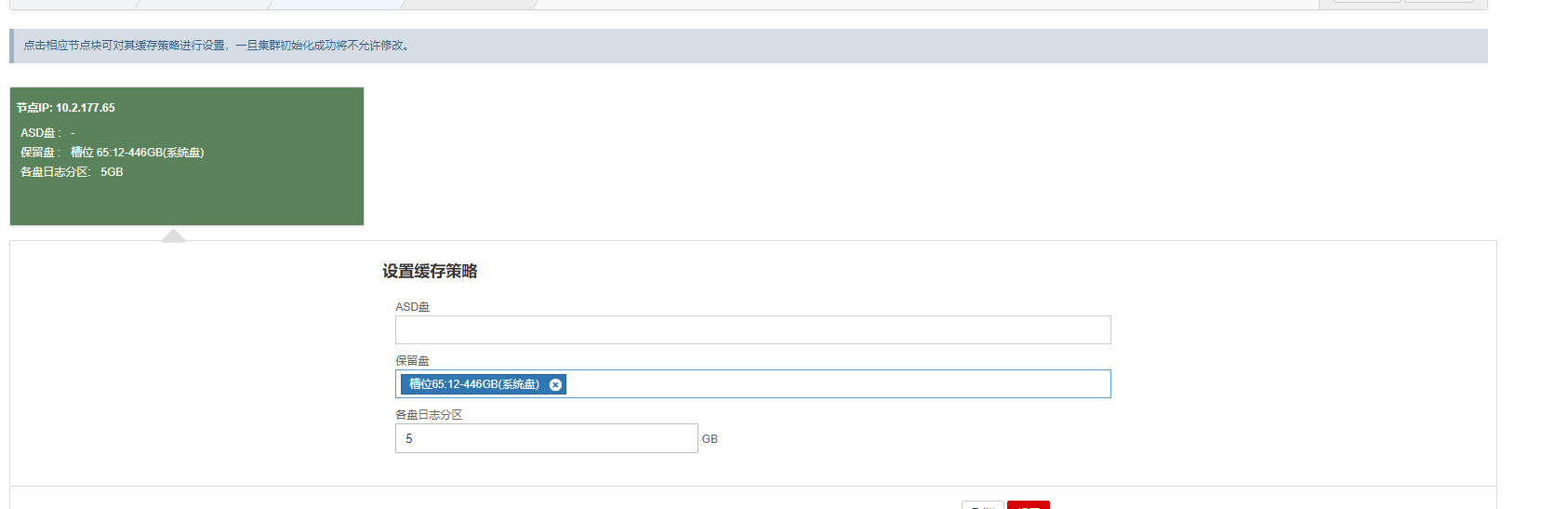
- 已经安装了AnyShare(/sysvol 目录) 的磁盘,在集群初始化的时候需要作为保留盘,不能作为普通的磁盘进行初始化。
点击如下界面保留盘一栏,选择所有SSD
2.5、集群初始化时报错:The Number of Osd of Host Exceeded Max Osd Number
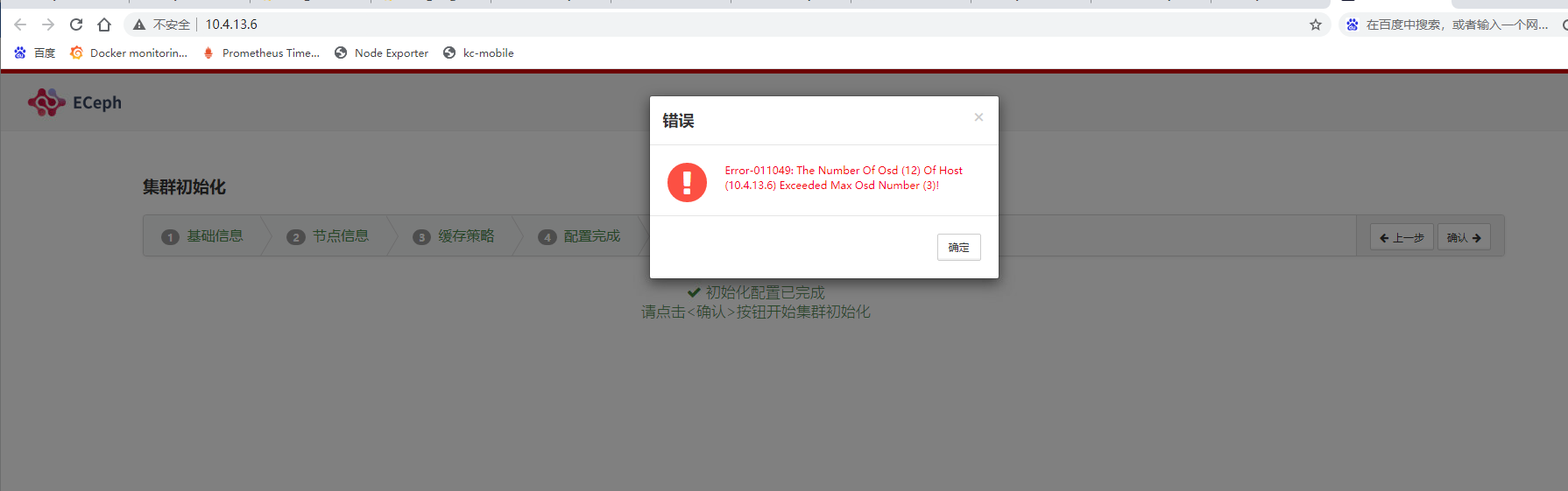
ECeph检测到的磁盘数必须大于手动填写的槽位数。比如有12个盘,但填3,会报上述错误。这里一定要填写最大可用的磁盘数目。比如,有12个槽位,但当前只插了6块盘,填6虽然不会报错,但为了后续扩容方便,需要填写12。
2.6、集群初始化时报错:No Data Disk Found In Cluster
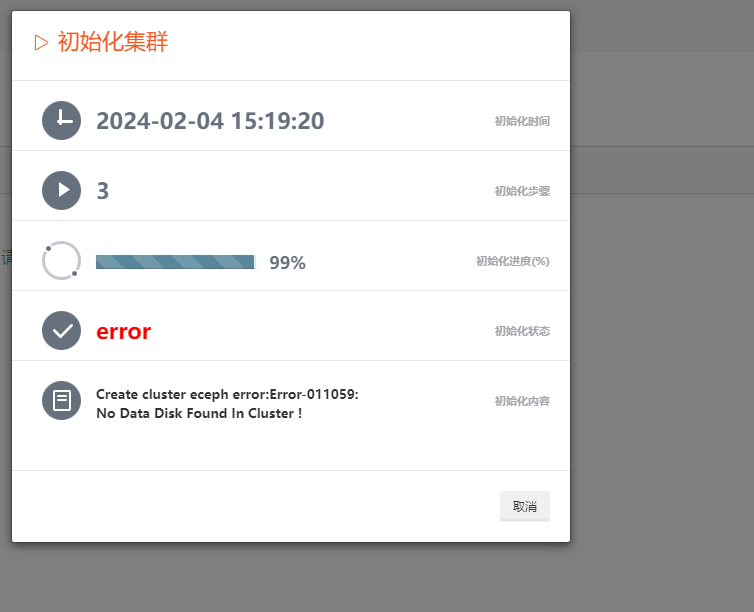
进入/opt/minotaur/tools目录
执行脚本: ./agent_disk -f get_detail --url http://127.0.0.1:14321 (或者./agent_disk -f get_detail --url http://127.0.0.1:14321 )
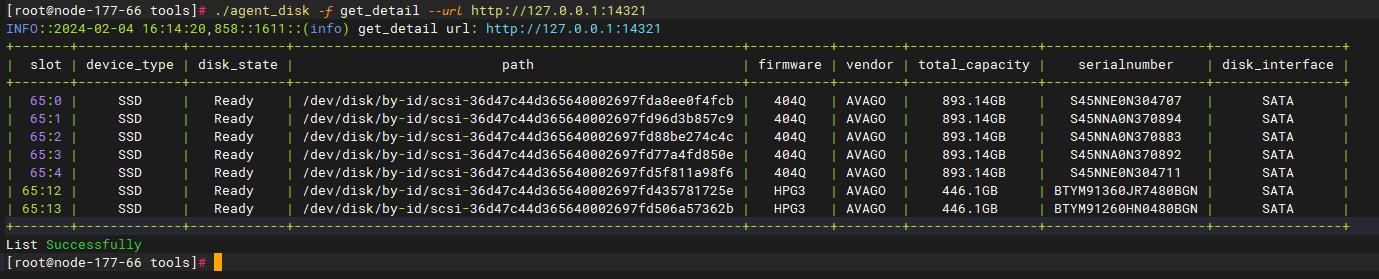
该环境上所有磁盘都为SSD盘,初始化时全都被设置成了保留盘
仅将系统盘设置成保留盘即可
三、ProtonECeph WEB界面问题
3.1、 管理程序8003端口无法访问,怎么排查?
WEB界面微服务proton-eceph-config-web对外端口默认为8001,利用ingress配置对外8003端口。如果出现8003端口无法访问,可以排查是否为iptables规则有丢失, 运行:
iptables -t nat -xvnL |grep 8001
iptables -t nat -xvnL |grep 8003
正常情况下,两者都会返回,若无,则执行命令:
iptables -F && iptables -t nat -F && systemctl restart docker
如果ingress配置没有问题,请参考2.1节进行容器日志排查
四、ProtonECeph对象存储问题
在ProtonECeph WEB界面添加对象存储之后,集群中各Ceph节点会启动RGW服务(radosgw),该服务作为ceph rados的客户端服务,对外提供S3接口(http端口7480)。WEB界面对租户、bucket等进行操作也基于该接口。为了对外提供https服务,会利用Nginx配置反向代理,对外提供http(端口10001)、https(端口10002)两种访问方式。
4.1、对象存储读写失败或者WEB界面创建租户失败,怎么排查?
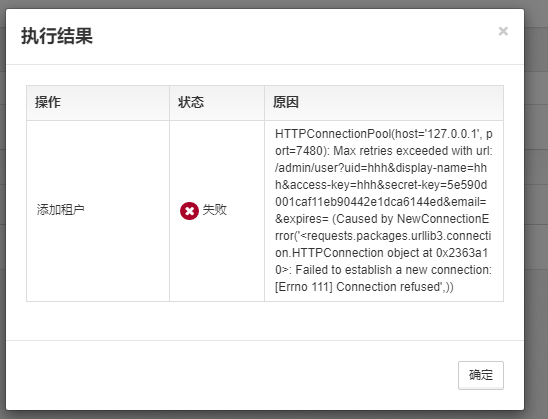
- Nginx层面排查
netstat -an | grep -e 10001 -e 10002查看Nginx对外端口是否监听:- 如果未监听,运行
systemctl status slb-nginx查看服务是否运行,若未运行,手动启动该服务。 - 如果监听,执行
curl http://{对象存储IP}:10001或者curl -k https://{对象存储IP}:10002看下是否返回正常;- 若返回502,则是RGW层面问题。
- 如果未监听,运行
- RGW层面排查
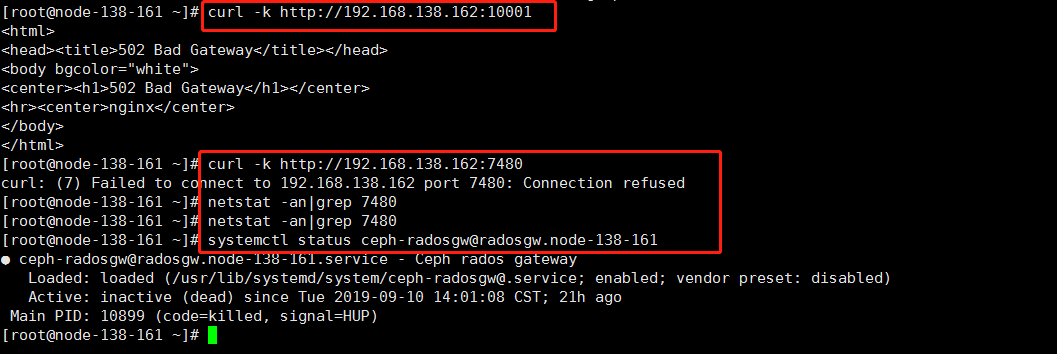
- 检查RGW服务状态:
systemctl status ceph-radosgw@radosgw.{主机名},看服务是否启动- 如果未启动,重启服务,或者查看日志
/var/log/ceph/client.radosgw.{hostname}排查启动失败问题。 - RGW服务已经启动,运行
curl http://{对象存储IP}:7480,看下是否返回正常:- 如果是,说明rgw正常。
- 如果不是,则一般为Ceph集群本身不能对外提供服务。
- 如果未启动,重启服务,或者查看日志
- 检查RGW服务状态:
- Ceph层面排查
- ceph -s看ceph是否健康,一般ceph ERROR情况下,不允许读写,rgw返回错误,此时需要修复ceph集群。
说明:最新版本的ECeph,ceph命令不支持在主机运行,需要进入eceph-node-agent容器执行。
- ceph -s看ceph是否健康,一般ceph ERROR情况下,不允许读写,rgw返回错误,此时需要修复ceph集群。
4.2、添加保护域时不能选择节点
如下图所示,节点上没有表示选择的向左的箭头,原因为该节点上的OSD少于2个。为满足3副本数据完整,需要至少3块盘,为了有多余盘可以及时进行数据均衡,推荐每节点至少4块盘。
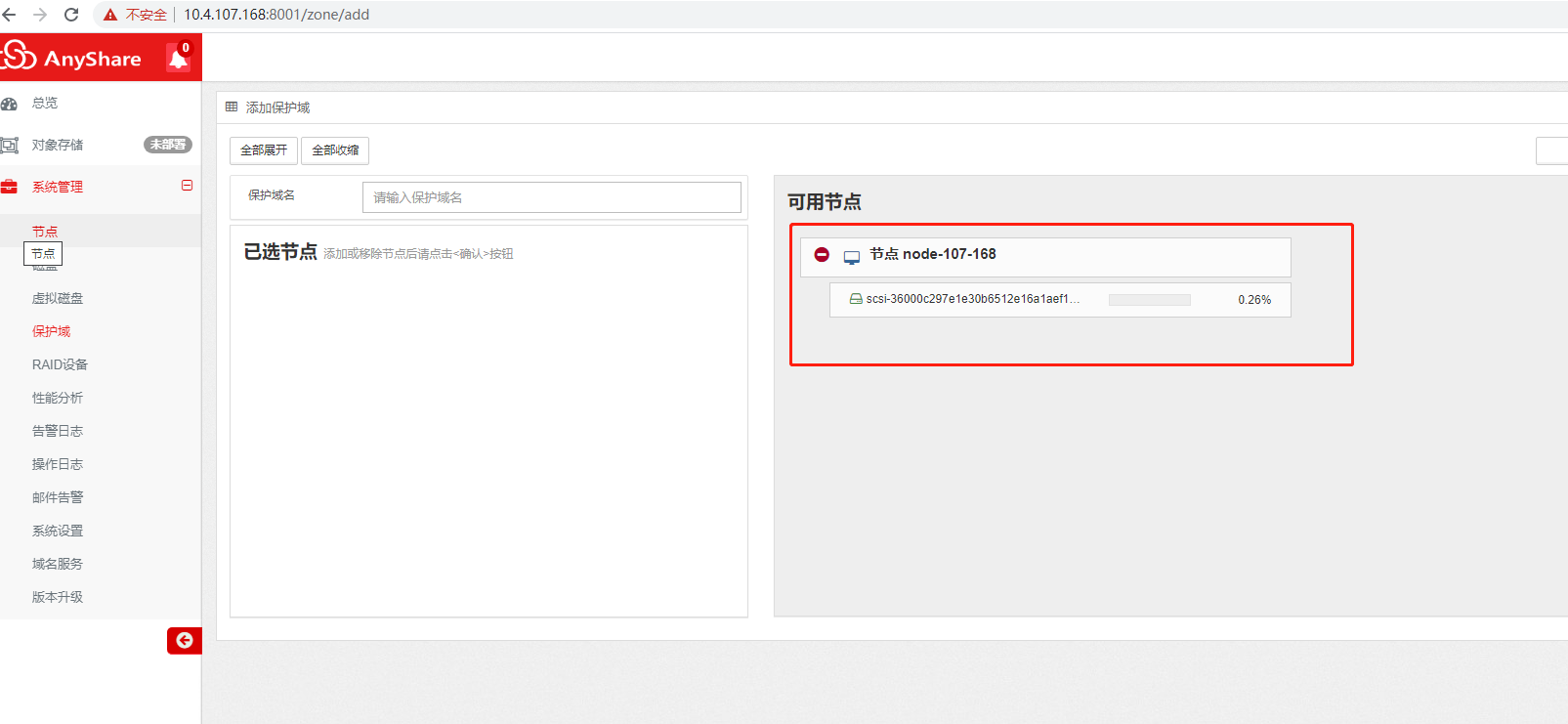
添加OSD的方法为:
- 添加磁盘,在系统层面可以用lsblk看到
- 在【系统管理】-【磁盘】界面可以看到空闲状态的磁盘
- 在【系统管理】-【虚拟磁盘】界面添加空闲磁盘为OSD
五、日志调试
5.1、如何开启rgw debug日志?
日志位置:/var/log/ceph/client.radosgw.`hostname`.log
-
永久开启
编辑/etc/ceph/ceph.conf设置debug_rgw为20/20。
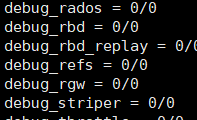
重启rgwsystemctl restart ceph-radosgw@radosgw.
hostname -
在线开启
进入/var/run/ceph找到rgw的asok文件,ceph-client.radosgw.[主机名]开头,asok结尾,可能有几个,找到创建时间最新的那个
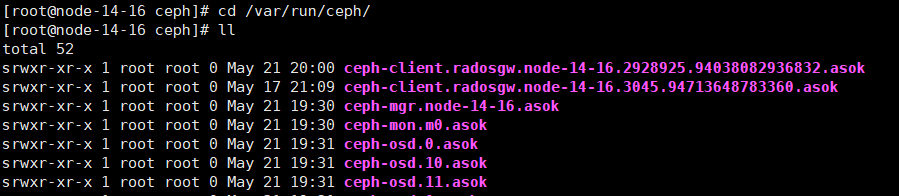
设置日志级别:ceph --admin-daemon [asok文件] config set debug_rgw 20/20

设置完后即可查看rgw的debug日志:
/var/log/ceph/client.radosgw.[主机名].log
问题调试完之后可以设回0/0:ceph --admin-daemon [asok文件] config set debug_rgw 0/0
5.2、如何开启nginx日志?
ECeph使用nginx来对集群的rgw进行负载均衡,nginx对外提供10001(http)、10002(https)两个端口,对应的配置文件路径为:/usr/local/slb-nginx/conf.d/http。配置文件为eceph_10001.conf及eceph_10002.conf。打开对应端口的日志则修改对应的配置文件,以下是10002端口为例。
-
在文件最上面定义日志格式(可选):
log_format json '{"scheme":"$scheme","http_host":"$http_host","remote_addr":"$remote_addr","server_addr":"$server_addr","time_local":"[$time_local]","request":"$request","status":$status,"body_bytes_sent":$body_bytes_sent,"upsteam_response_time":$upstream_response_time,"request_time":$request_time,"request_length":$request_length}'; -
打开日志,找到access_log,设置为on,并添加 access_log /var/log/ceph_nginx.log json(如果执行了第一步设置了日志格式)。
注意:- 添加一行后注意前面一行结尾注意加分号。
- 如果未设置日志格式,添加 access_log /var/log/ceph_nginx.log即可。

-
重新加载slb-nginx
运行:systemctl reload slb-nginx