创建工作流程
有以下几种简便方式可以新建流程:
-
从空白流程新建。
-
从流程模板新建。我们在“流程模板”中提供了一些针对常见场景的自动化流程模板,帮助您快速创建应对各种业务场景的流程。
-
从本地导入。当流程较为个性化,无法提炼成模板时,您可以选择将本地已有的模板包导入,以便更加快捷地完成操作。
在【工作中心】顶部栏中,可以点击【我的流程】,管理您所创建的流程,以及查看分配给您的流程。
› 工作流程使用场景示例
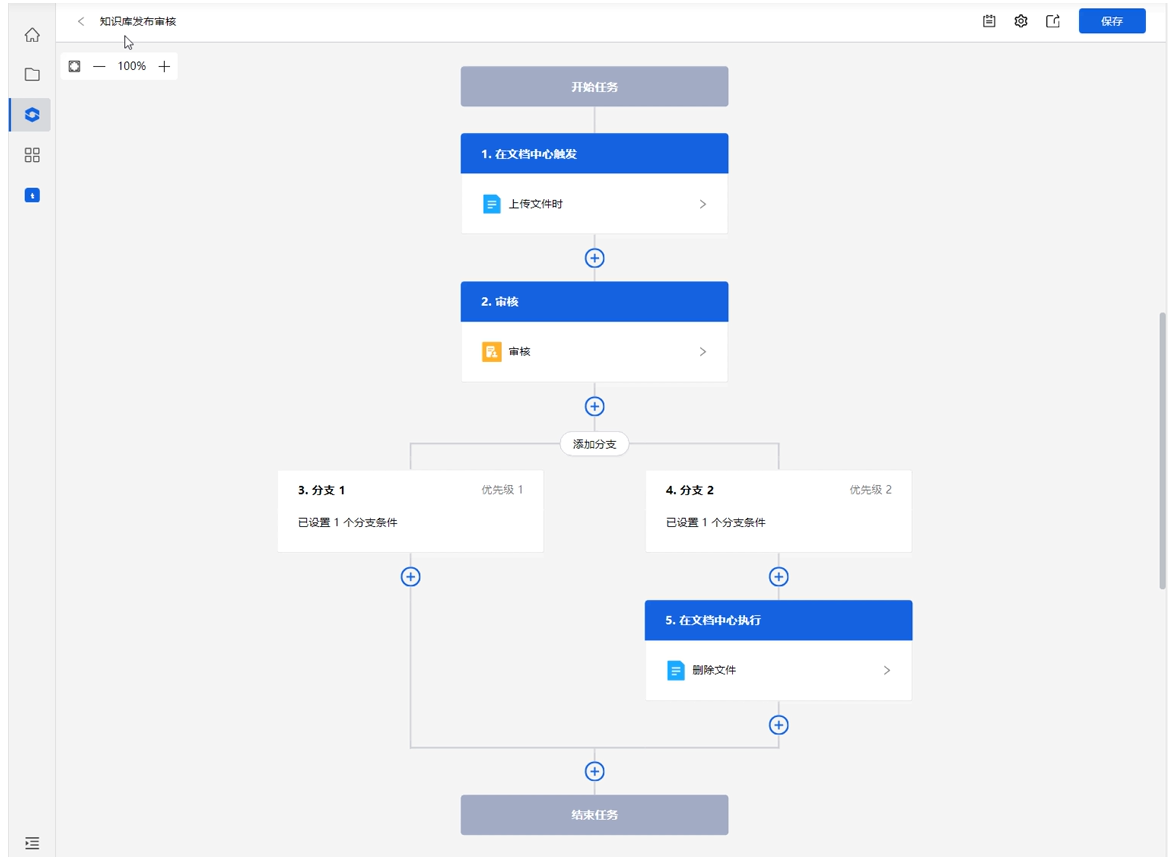
场景一:知识库发布文件审核
需求描述:在知识库发布文件时,需经过领导审核内容,审核通过后,文件发布成功。
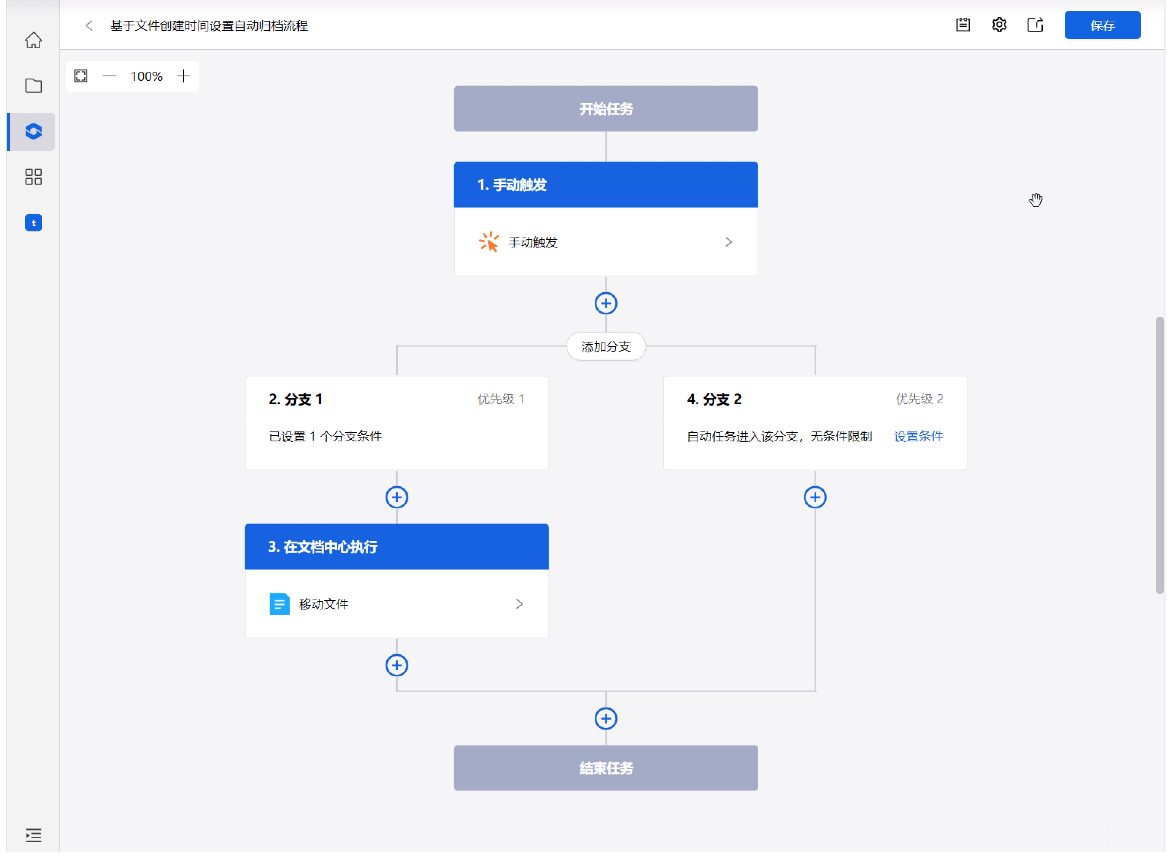
场景二:某电商企业文件过期后需自动归档
需求描述:某电商的图片库中放着大量的拍摄样片,这些样片具有时效性,一旦过季,这些样片需要被下线归档。
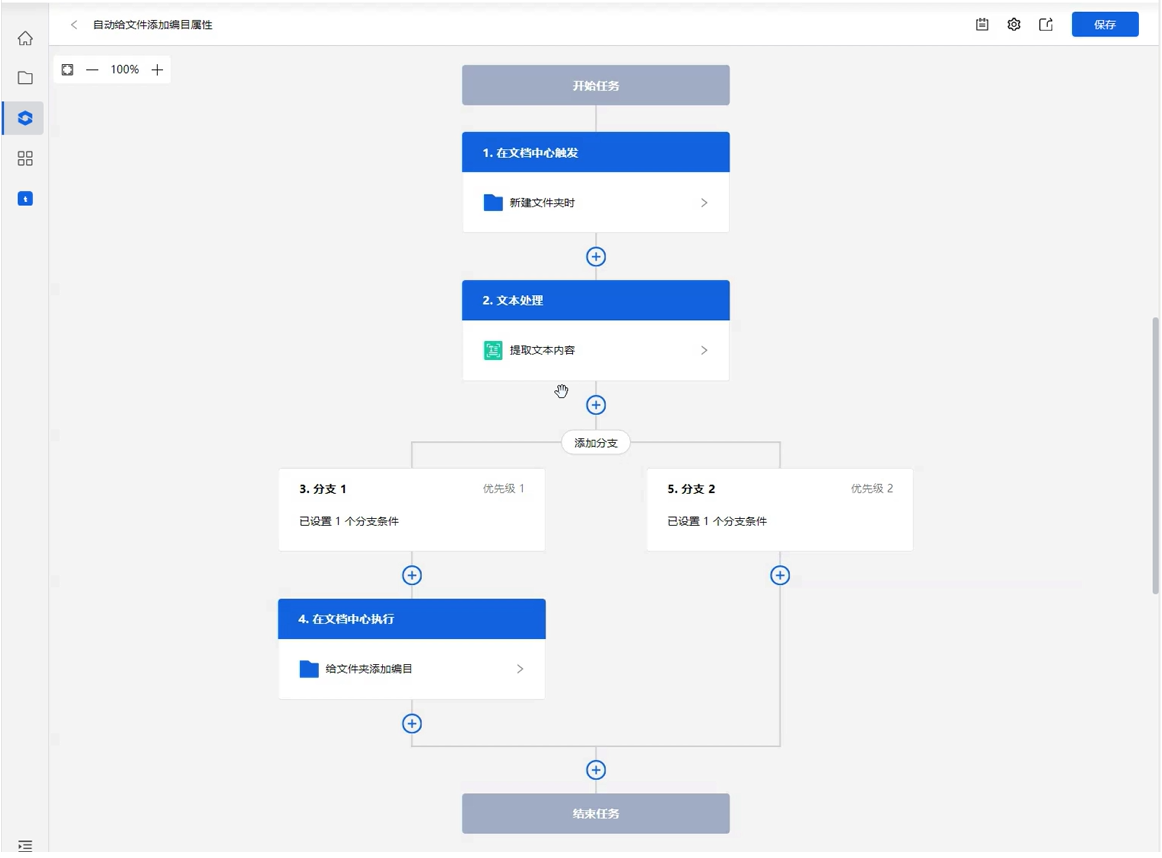
场景三:某建筑单位自动给文件夹添加编目属性
需求描述:某建筑单位在管理项目文档时,会用 档案分类号+分类描述 的形式,作为文件夹的名称,来创建文件夹的多级结构。在创建好一个文件夹时,期望给文件夹自动设置编目模板,同时将文件夹名称中的[档案分类号]作为编目模板中的某一个字段填入进去。
场景四:针对指定文件夹触发自动化知识发布流程
需求描述:企业内部文档及运营人员在完成运营、发版材料的撰写后,可基于指定文件夹发起审核流程,在填写元数据信息后,系统将自动把此文件夹提交至审核员审核。待审核通过后,待发布文件夹将自动复制到发布路径下,开放给企业内部员工共同查阅。
知识发布流程示意:
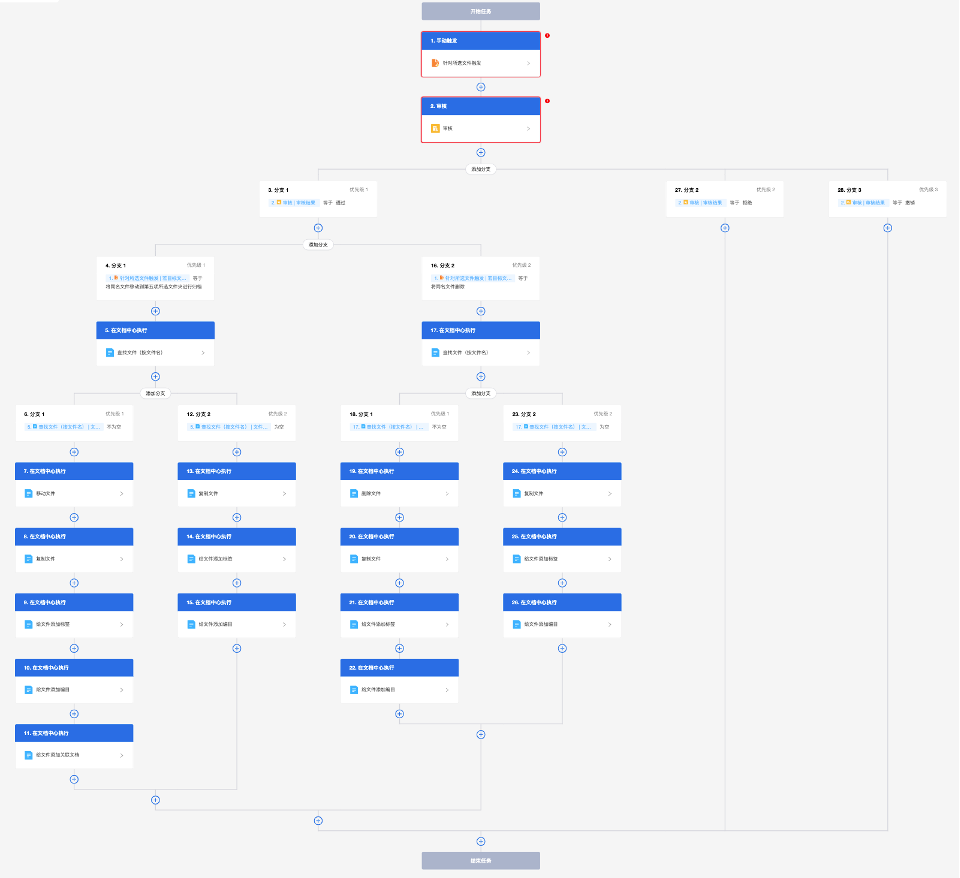
发起知识发布审核流程:
创建基于自然语言生成的工作流
除上述创建方法,为搭建更智能、更高效的企业级知识管理体系,借助大模型能力,AnyShare支持以对话交互的形式创建工作流。
系统将根据用户输入的描述性文字,智能分析并提取核心流程节点,并生成过程性的审核流程配置窗口,支持用户根据需求进一步完善、修改。配置说明,具体请参考 基于自然语言生成工作流。
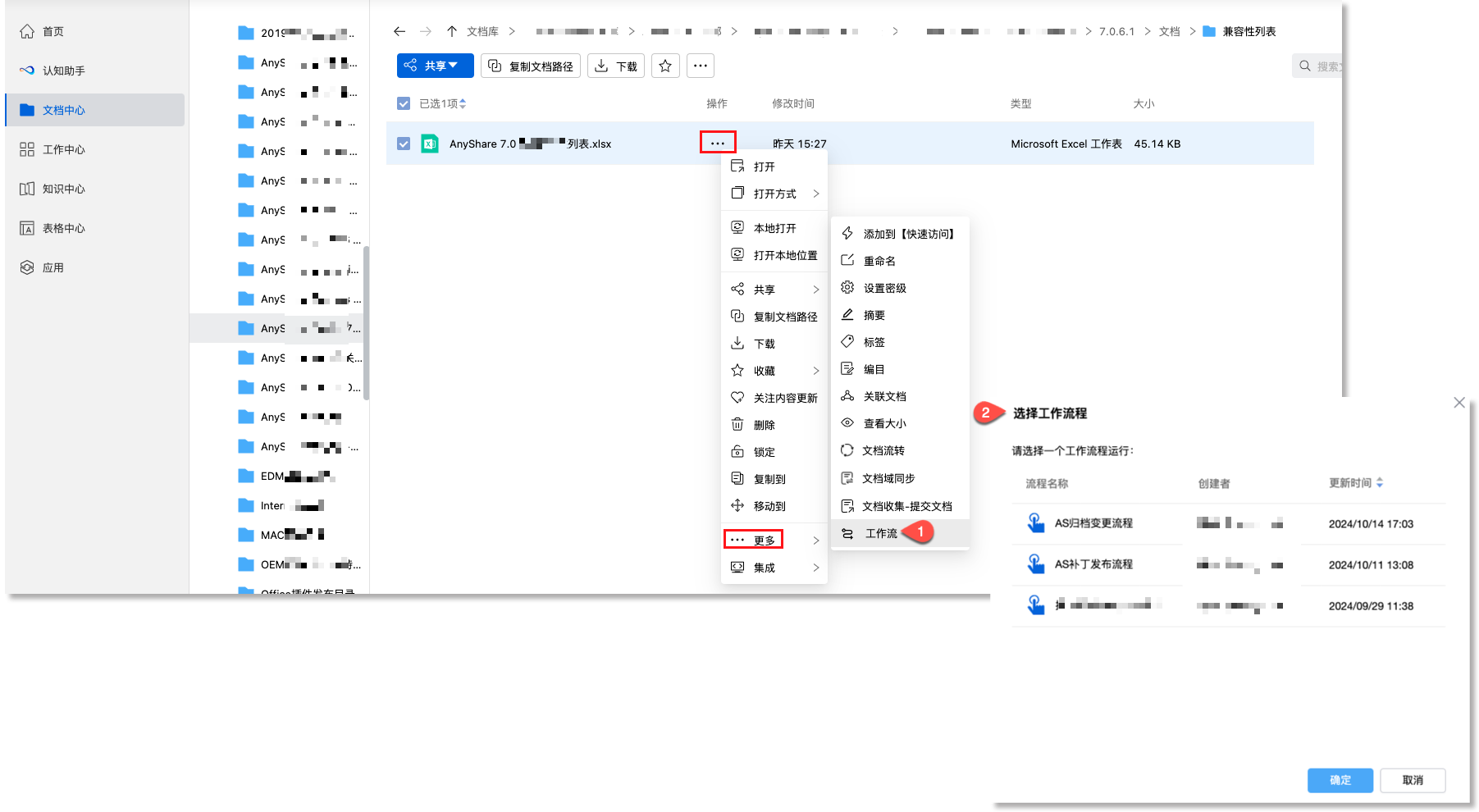
进入文档中心,点击某一文件/文件夹,在右侧侧边栏的工作流页签中唤起工作流交互窗口。
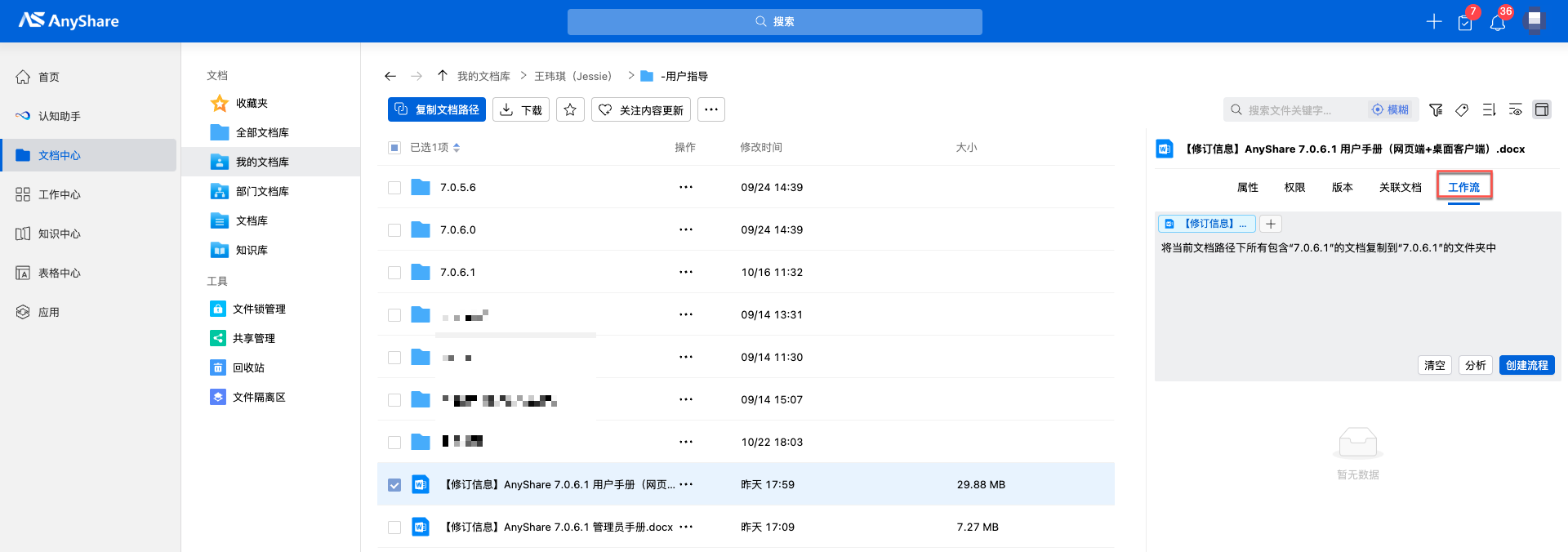
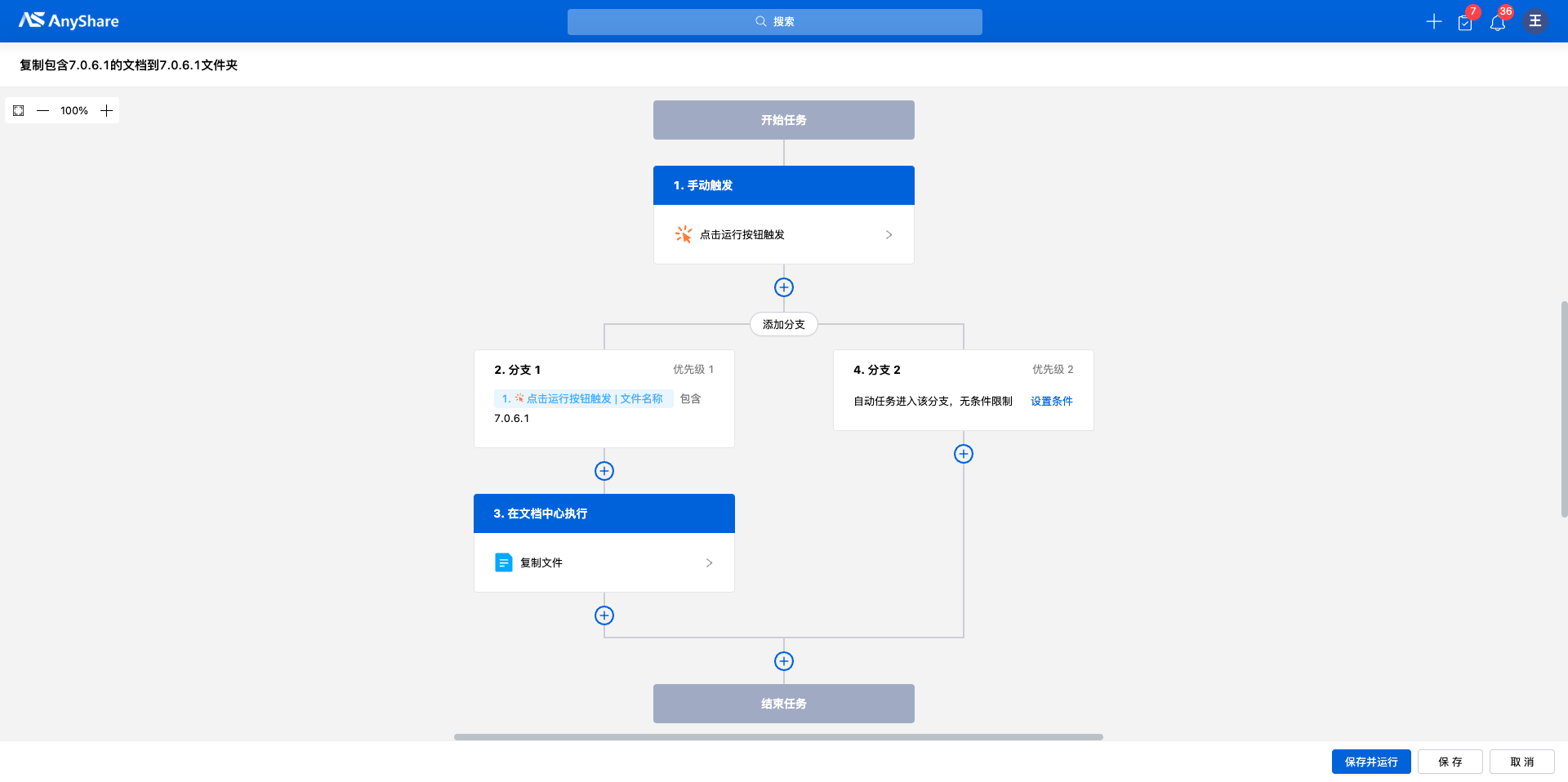
在对话窗口中输入工作流描述文字,描述文字需要尽量覆盖关键执行节点、简洁,例如,“将当前文档路径下所有包含’7.0.6.1’的文档复制到’7.0.6.1’的文件夹中”。
点击【分析】可查看系统提取到的关键工作流节点,点击“![]() ”按钮可手动添加流程节点中的用户/文档,点击【创建流程】可进入工作流配置页面。
”按钮可手动添加流程节点中的用户/文档,点击【创建流程】可进入工作流配置页面。
手动添加流程节点(用户/文档)
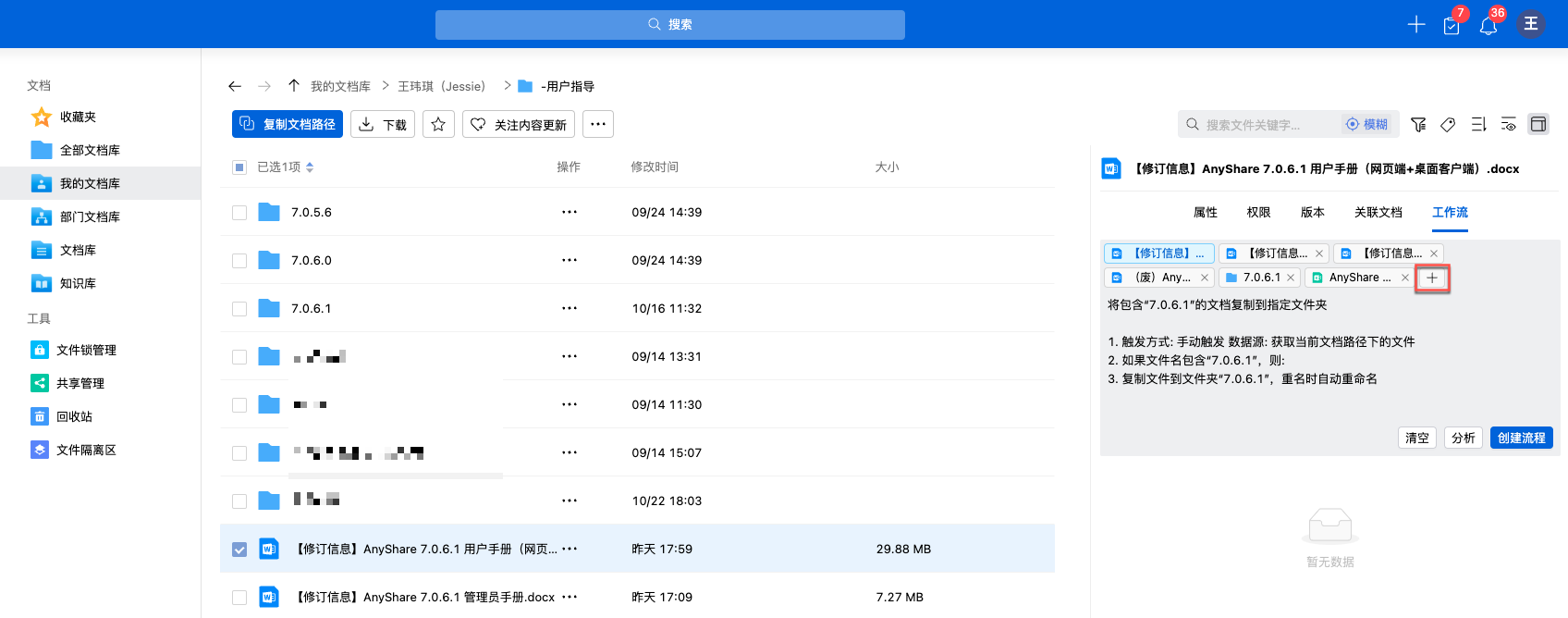
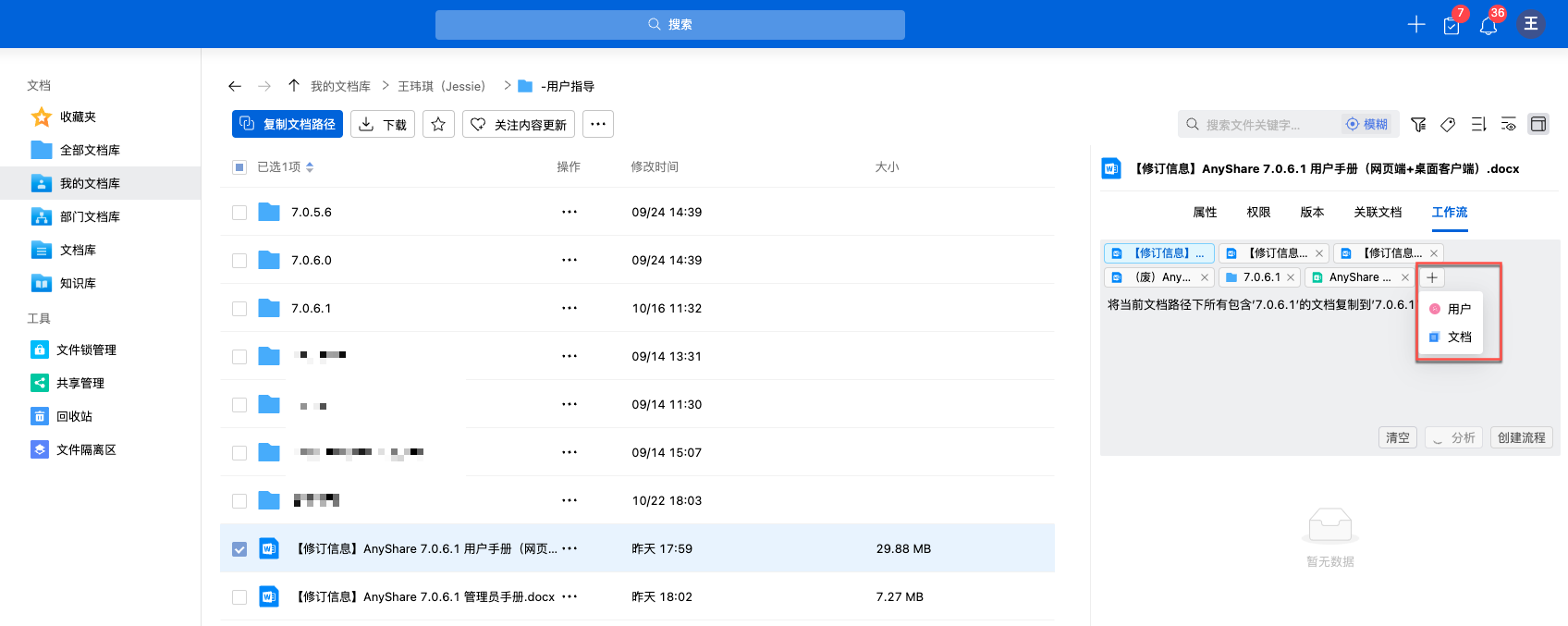
审核流程配置窗口
当前支持的自然语言生成工作流场景如下(需注意:若无文件/文件夹的相关操作权限,则执行不成功):
1)手动操作场景
|
操作
|
自然语言描述示例 |
备注 |
|
移动文件/文件夹 |
将包含后缀pdf和doc的文件移动到文件夹“2013”中 |
|
|
复制文件/文件夹 |
复制大于6MB的文件到2022文件夹中,同名文件自动覆盖 |
|
|
重命名文件/文件夹 |
给当前文件夹下的文件重命名,文件名称前缀添加当前时间 |
|
|
给文件/文件夹打标签 |
给名称包含“月”的文件夹打标签,标签是“日期” |
|
|
删除文件/文件夹 |
删除当前文件夹下文件名包含14的文件 |
|
|
新增文件/文件夹 |
分别在文件夹“1月记录”和“2月汇报”中新增文件夹“我的日常” |
|
|
更新文件 |
更新选中文件,在最后一行添加一行“我的测试内容” |
|
|
文件分享时,配置权限配置 |
分享文件给用户张三,并设置查看权限 |
权限过期时间需要用户手动配置 |
|
获取文件路径 |
获取当前文件所在的文档目录层级 |
|
|
获取时间 |
给当前文件夹下创建时间早于2天的文件,添加已过期标签 |
|
|
发起审核流程 |
申请文件编辑权限并发起审核 |
审核流程中的审核员需要用户手动配置 |
2)事件触发
|
触发事件 |
自然语言描述示例 |
备注 |
|
上传文件时 |
在文件夹“学习资料”上传文件时触发流程,将上传的文件复制到 “公开课”文件夹 |
|
|
新建文件夹时 |
新建文件夹“7.0.6.2”时触发流程,删除文件夹“7.0.6.1” |
|
|
复制文件/文件夹时 |
复制文件“7.0.6.1”时触发流程,重命名文件,后缀添加“过期文件” |
|
|
移动文件/文件夹时 |
移动文件到运营部门时触发流程,新建文件夹命名是“移动的文件+序号” |
|
|
删除文件/文件夹时 |
给名称包含“月”的文件夹打标签,标签是“日期” |
|
3)定时场景
|
触发时间 |
自然语言描述 |
备注 |
|
每天触发 |
将选中的文件在11:25分移动到文件夹学习文件下 |
|
|
每周触发 |
每周一上午10点新建文件夹”本周工作“ |
|
|
每月触发 |
每月28号12时分享文件夹并触发审核 |
审核流程中的审核员需要用户手动配置 |
注意:
1)若无文件/文件夹的相关操作权限,则执行不成功;
2)7.0.6.2版本暂不支持Python节点;
3)7.0.6.2版本下,暂不支持自动生成审核节点,需要用户手动指定。
创建基于对话流触发的工作流
对话流是一种面向对话场景的工作流编排模式,专为需要多步逻辑处理的交互式应用设计。
用户可创建绑定了对话流触发工作流的智能体,使用时通过问答交互启动自动化流程,以调用工作中心配置的工作流,结合流程中预设的执行操作,实现对话指令与业务自动化的联动。
下文以“通过对话形式生成财务报告并存储至指定目录”场景为例,说明完整配置流程:通过创建对话流触发工作流,结合内置RAG节点的检索与生成能力,自动完成财务报告的智能生成与归档,实现“用户提问→知识检索→内容生成→文件存储”的全流程自动化。
1. 创建对话流触发流程
进入工作中心,点击页面右上角的【新建】>“对话流触发”,进入流程编辑画布。

2. 配置触发器
“对话流触发”流程默认为对话流触发器,接收用户提问、上传临时文件等输入数据。相关变量为系统默认的固定参数,无需修改,变量说明如下:
o Query(用户提问):文本变量,接收用户输入的文本类指令、问题或结构化数据(如JSON文本、列表文本),是工作流/智能体获取用户核心诉求的入口。
o Source_range(临时区文件):数组<对象>变量,传递用户当前会话中需处理的临时文件信息。
o History(历史问题及回复):数组<对象>变量,记录多轮对话上下文以保障理解连贯性,单次指令场景可不做配置。
o Lib_range(文档库ID):数组<对象>变量,指定知识库检索范围,仅知识问答等需调用特定知识库的场景配置,无需求可不做配置。

3. 配置执行操作
1)RAG-Retrieval
点击“选择执行操作“,执行类型选择“RAG”、执行动作“Retrieval”,进入详情设置页面,配置参数说明如下:

o query:绑定变量“用户发起对话时 | Query(用户输入的参数)”,接收用户财务报告需求,把用户提问作为检索关键词,并结合其他数据,召回和提问相关的文档片段或数据;
o source_ranges:绑定变量“用户发起对话时 | Source_range(临时区文件)”,接收用户上传的财务数据文件。
点击【确定】,完成检索节点的配置,随后再配置大模型内容生成节点:
2)RAG-Generation
点击“选择执行操作“,执行类型选择“RAG”、执行动作“Generation”,进入详情设置页面,配置参数说明如下:

o query:绑定变量“用户发起对话时 | Query(用户输入的参数)”,传递用户原始报告需求,把用户原始提问传递给大模型,让大模型明确生成目标,同时结合检索结果rst来组织最终内容。
o rst:绑定变量“Retrieval | rst”,接收检索返回的财务相关数据。
o model_url:填写大模型服务地址,指定生成内容的大模型。
提示:model_url需配置有效的大模型服务地址,否则无法生成报告内容。如有疑问,请联系 AnyShare 相关技术支持人员获取。
3)添加“新建文件”操作
点击“选择执行操作“,执行类型选择“在文档中心执行”、执行动作“新建文件”,进入自动在指定目录下新建文件操作的详情页面,按需选择新建文件的类型、文件名称、存放的目标文件夹、文件重名的处理方式。

点击【确定】,完成新建文件节点配置。
4)添加“更新文件”操作
点击“选择执行操作“,执行类型选择“在文档中心执行”、执行动作“更新文件”,进入自动将文本内容写入到指定文件操作的详情页面,配置参数如下:
提示:用户需拥有目标文件夹创建、编辑等相关文档权限,否则新建/更新文件操作会执行失败。
o 要更新的文件:绑定变量“新建文件 | 文件”,即上一步新建的“总结报告”文件。
o 更新文件的方式:按需选择在原内容后换行新增内容或完全覆盖原内容。
o 更新内容:绑定变量“Generation | response“,即Generation节点生成的财务报告总结内容。

4. 运行测试流程
在工作中心>我的流程中,找到目标流程,点击【运行】,填写运行参数:
o Query:输入财务报告需求(如“基于上传的财务数据,生成 2025 年 Q4 部门财务总结报告”)。
o Source_range:按 JSON 格式填写上传的财务数据文件信息。
o 其余参数可留空。
点击【确定】,流程自动执行,执行完成后,可在目标文件夹中查看生成的财务报告文件。

工作流成功跑通后,您可以进入智能体创建页面,新建“对话流”类型的智能体,创建时绑定此流程。成功创建后,用户与智能体对话时,可在临时数据区上传财务数据文件并输入报告需求,智能体将按照绑定工作流的预设操作执行:生成并将报告文件存储到指定文件路径,并回复用户。
提示:关于智能体的创建步骤,请参见 知识助手 - 智能体 - 如何创建并发布智能体?章节。
在工作流中使用Python节点
› 添加流程管理员
1. 获取认证Token及用户信息
进入AnyShare管理控制台 > 组织管理 > 用户管理 > 用户和部门页面,按下[F12]快捷键打开浏览器开发者工具,在接口列表中找到Usrm_GetDepartmentOfUsers请求,依次查看并复制获取:
• “标头”标签页:复制Authorization 字段值的内容,即为接口认证 Token;
• “预览”标签页:获取目标用户(流程管理员)的id(即user_id)与 loginName(即user_name)。


2. 接口工具认证
安装并打开接口调试工具(如Postman),新建请求。切换至“Authorization”标签页,选择认证类型为 Bearer Token,将步骤 1 中获取的 Token 粘贴至输入框,点击【Send】完成接口身份认证。

3. 添加指定用户为流程管理员
在接口工具中,切换至 Body 页签,选择 raw 格式并设置为 JSON 类型。按如下格式填写请求体,将步骤 1 获取的user_id、user_name填入对应字段,将指定用户添加为流程管理员。
添加完成后,点击【Send】发送请求,若接口返回“204 No Content”状态码,即代表该用户已成功添加为流程管理员。

› Python 依赖包管理
在工作流中运行Python节点/自定义节点时,需要提前安装对应Python依赖包。AnyShare提供界面化的Python包管理后台,流程管理员可以点击“![]() ”, 进入工作中心【Python包管理】界面。
”, 进入工作中心【Python包管理】界面。
 在此管理界面,流程管理员可完成Python依赖包的上传、安装、删除等管理操作。
在此管理界面,流程管理员可完成Python依赖包的上传、安装、删除等管理操作。
点击【+上传】后,在弹出的本地文件选择框中选择“tar”格式的文件进行上传。上传完成后,将自动进入安装进程。完成后,普通用户方可在定义Python节点/自定义节点时使用此依赖包。
注意:
1)上传和安装的动作绑定,即上传成功后会自动开始安装;
2)当前暂不支持暂停上传中、安装中的依赖包;
3)依赖包被删除后也将随之失效。
› 在工作流中使用Python节点
在工作流中使用Python节点,可以通过代码完成自定义的逻辑操作,完成当前工作流已有的节点未提供的能力。
注意:使用Python节点,需要拥有一定的编码能力,并且了解AnyShare OpenAPI的相关调用。
下面给出一个在Python代码中实现调用OCR接口的示例:
from aishu_anyshare_api.api_client import ApiClientimport aishu_anyshare_api_efast as efastfrom datetime import datetimeimport requestsimport jsonimport reimport base64def main(doc_id):client = ApiClient(verify_ssl=False)try:json_file = file_download(client, doc_id)text = json_file.contenturl = 'http://10.4.132.197:8507/lab/ocr/predict/general'b64 = base64.b64encode(text).decode()data = {'scene': 'chinese_print', 'image': b64}res = requests.post(url, json=data).json()texts = res['data']['json']['general_ocr_res']['texts']return textsexcept Exception as e:return str(e)def file_download(client: ApiClient, doc_id: str) -> requests.Response:resp = client.efast.efast_v1_file_osdownload_post(efast.FileOsdownloadReq.from_dict({"docid":doc_id})) #type: ignoremethod, url, headers = resp.authrequest[0], resp.authrequest[1], resp.authrequest[2:]header = {}for val in headers:arr = val.split(": ")header[arr[0]] = arr[1].strip()resp = requests.request(method, url, headers=header, verify=False) # type: ignorereturn resp
• 代码说明:代码实现了获取文件的内容,交给ocr处理之后,基于ocr的处理结果json返回值,提取业务需要的数据。具体提取规则以及ocr返回的json数据格式会因为ocr的模型不同而有差异,请根据具体的业务进行调试。以上代码给出基础的实现示例代码。
• 代码原理:工作流框架内部将AnyShare的文档操作相关OpenAPI封装成Python sdk,可以直接调用,框架会自动处理用户token代码主函数的输入输出值都会记录在工作流的context中,在一个流程的生命周期中可以使用其值其工作流配置如下:
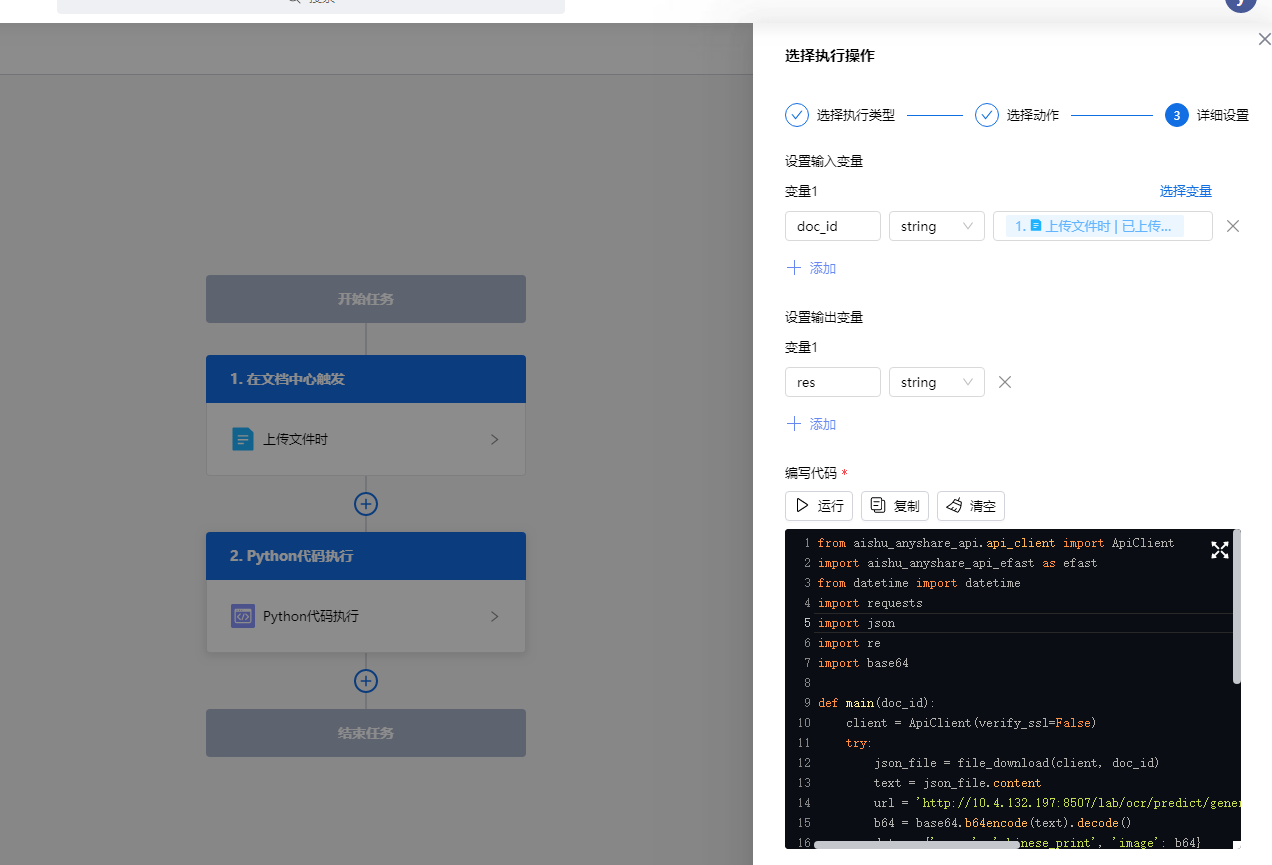
说明:
1)工作流在上传文件时触发;
2)Python节点设置一个输入变量,示例为doc_id,其值为触发该流程的文件docid,在Python节点中会基于此输出变量进行操作;
3)Python节点可以设置若干的输出变量,输出变量与Python节点中的main方法的return值一一对应;
4)在 Python节点中处理数据之后,将需要在后续流程进行处理的数据作为返回值输出,在后续流程中即可使用该数据,比如设置编目和标签等。
现在,试试新建您自己的自动化工作流程吧!