本文包括如下内容:
调用指标模型接口时需要用到指标模型ID,而迁移在不同环境定义好的指标模型时,指标模型ID会发生变化,这将导致模板的可移植性很差。如何解决指标模型模版的移植性问题呢?
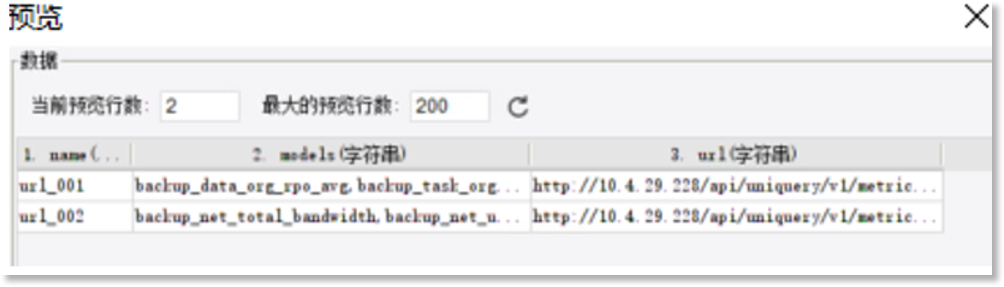
使用配置文件,将指标模型ID写入到一个映射表中,在定义数据连接时可以通过一个固定值去查询映射表中的ID值。因为,不同环境的URL地址和端口也不一样,可以将整个URL都视为被映射的目标值。
根据帆软大屏开发的特性,可选择采用文件数据集去实现这个映射表。
创建文件数据集:
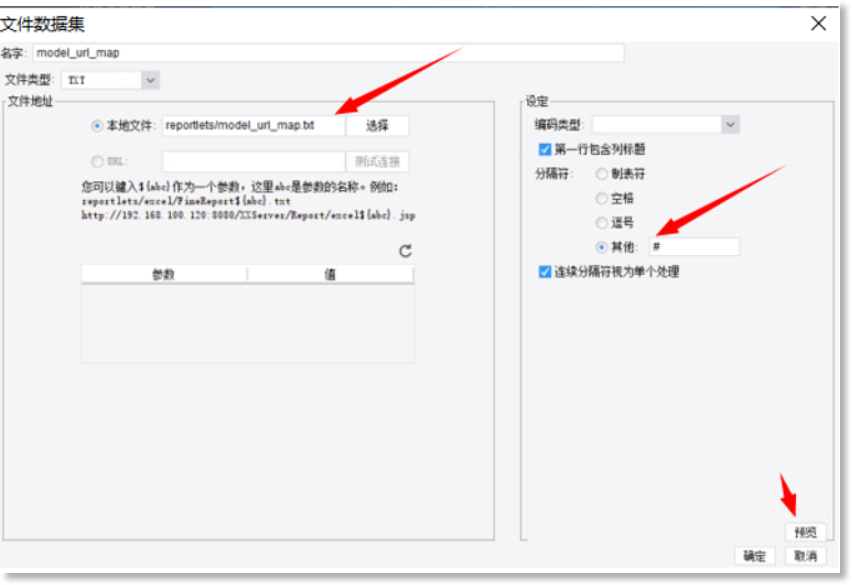
文件model_url_map.txt内容如下:
name#models#url
url_001#backup_data_org_rpo_avg,backup_task_org_status#http://10.4.29.228/api/uniquery/v1/metric-models/472875539401552602,472875539116339930
这个接口访问的路径是要同时获取指标模型backup_data_org_rpo_avg,backup_task_org_status的数据,给这个访问路径一个别url_001。
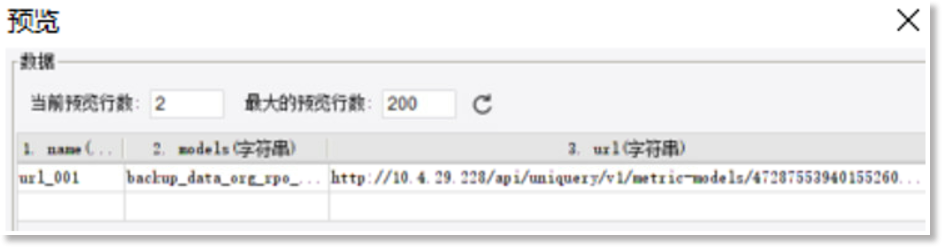
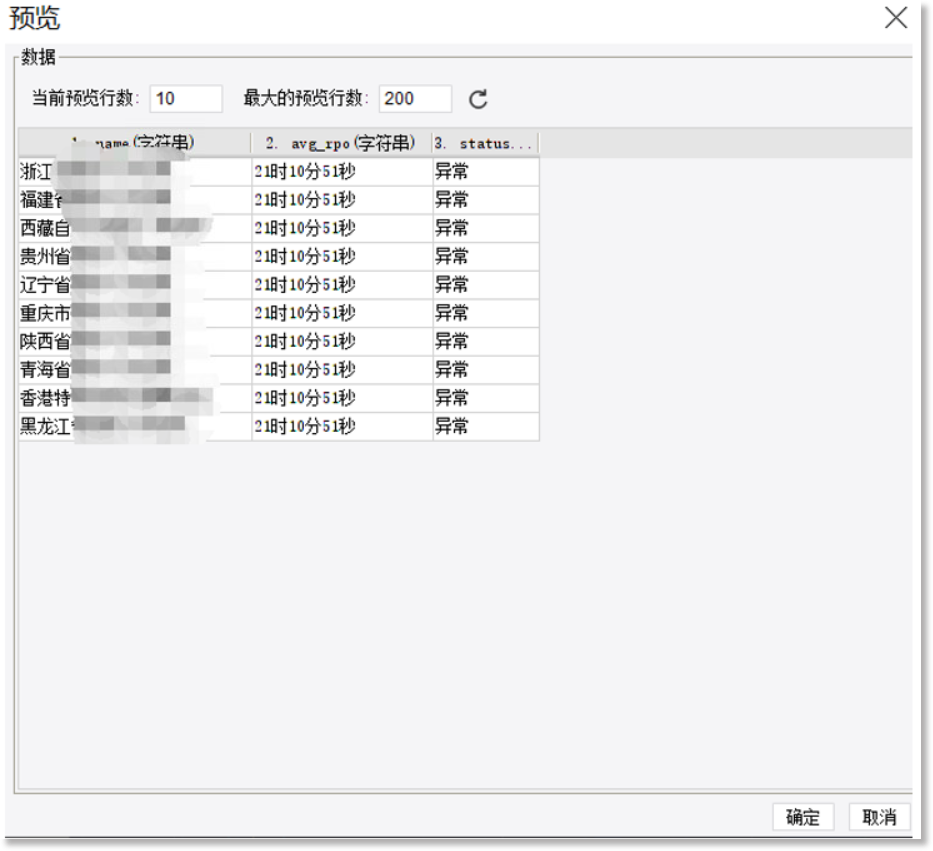
点击“预览”查看此文件数据集的内容,如下所示:
之前定义了数据连接“ar_multi_model_demo”,此内容是一个URL地址,把此地址改为公式。
修改前:
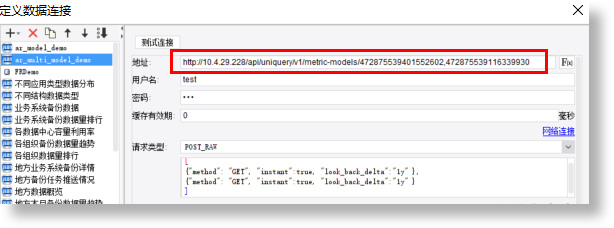
修改后:
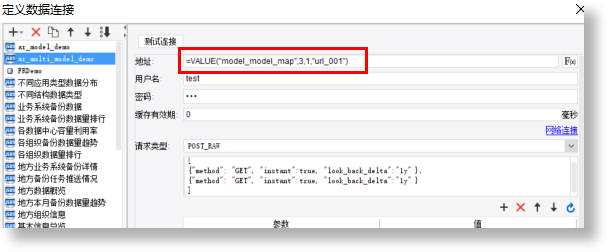
替换之后再去数据集预览数据,和替换之前效果一致:
文件数据集的源文件如果手动配置,工作量会比较大,且ID的可读性差容易出现配置错误,较合理的方案是写个Python脚本去生成一个配置文件。当要在不同的环境不部署时,只需要修改服务器地址和认证信息,执行脚本后就得到了新的配置文件。
下面给出一个脚本的示例:
#-*- coding:utf-8 -*-
import requests
import json
server = "http://10.4.29.228"
auth=('test', '12345678')
models_dict ={
"url_001":{
"单个XX平均RPO":"backup_data_org_rpo_avg",
"单个XX任务运行状态":"backup_task_org_status"
},
"url_002":{
"网络总带宽":"backup_net_total_bandwidth",
"网络已用带宽":"backup_net_used_bandwidth",
"网络带宽利用率":"backup_net_bandwidth_rate",
"网卡状态":"backup_net_status"
}
}
def gen_url_map_table():
batch_urls = []
for model_type_name, models in models_dict.items():
ids = []
model_names = []
for desc,model_name in models.items():
url = server + "/api/data-model/v1/metric-models?name="+model_name
resp = requests.get(url,auth=auth)
obj = json.loads(resp.text)
id = ""
if obj['total_count']>0:
id = obj["entries"][0]["id"]
print("%20s %40s %20s"%(desc,model_name,str(id)))
else:
print("%20s %40s %30s"%(desc,model_name,"未找到"))
ids.append(id)
model_names.append(model_name)
batch_url = server + "/api/uniquery/v1/metric-models/"+",".join(ids)
item = "%s#%s#%s"%(str(model_type_name),",".join(model_names),str(batch_url ))
batch_urls.append(item)
return batch_urls
def save_table_data(data_list,filename="model_url_map.txt"):
with open(filename,"w") as csvfile:
idx = 0
csvfile.write("name#models#url\n")
for batch_url in data_list:
print(batch_url)
idx += 1
csvfile.write(batch_url+"\n")
data_list = gen_url_map_table()
save_table_data(data_list)
执行上面的脚本,就会得到新的配置文件:
name#models#url
url_001#backup_data_org_rpo_avg,backup_task_org_status#http://10.4.29.228/api/uniquery/v1/metric-models/472875539401552602,472875539116339930
url_002#backup_net_total_bandwidth,backup_net_used_bandwidth,backup_net_bandwidth_rate,backup_net_status#http://10.4.29.228/api/uniquery/v1/metric-models/472875539451884250,472875539535770330,472875539502215898,472875539418329818
替换掉原来的文件,在文件数据集中预览结果: