数据视图是虚拟化的逻辑数据集,用于满足数据查询需求,在业务查询场景和多用户之间也充当了关键的数据隔离层。数据视图支持对数据源中的指定数据进行读取时的转换和加工,使用户能够灵活、便捷地根据特定查询需求进行数据选择和加工,提高数据查询和分析效率及可复用性的同时确保了原始数据源的完整性和安全性。
AnyRobot数据视图管理模块支持数据视图的创建(手动创建、批量导入创建),预览视图数据,查看、修改、删除数据视图,管理实时数据流订阅等功能。配置操作说明如下:
_61.png) 提示:您可以参照下方配置说明手动创建所需数据视图,也可以导入包含数据视图配置参数的合规文件批量创建数据视图。
提示:您可以参照下方配置说明手动创建所需数据视图,也可以导入包含数据视图配置参数的合规文件批量创建数据视图。
创建流程如下:
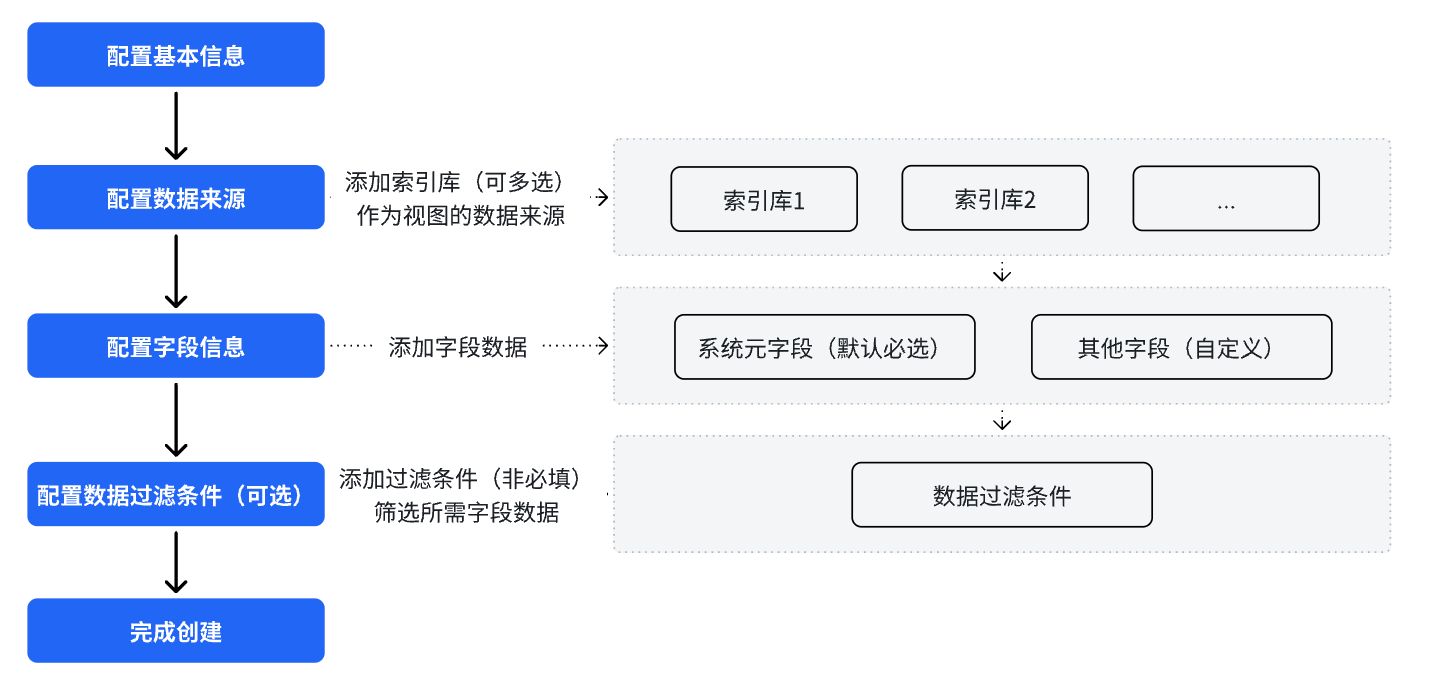
快速阅读链接:
进入数据管理>数据模型>数据视图配置页面,点击【+新建】,进入“新建数据视图”的配置流程,如下所示:
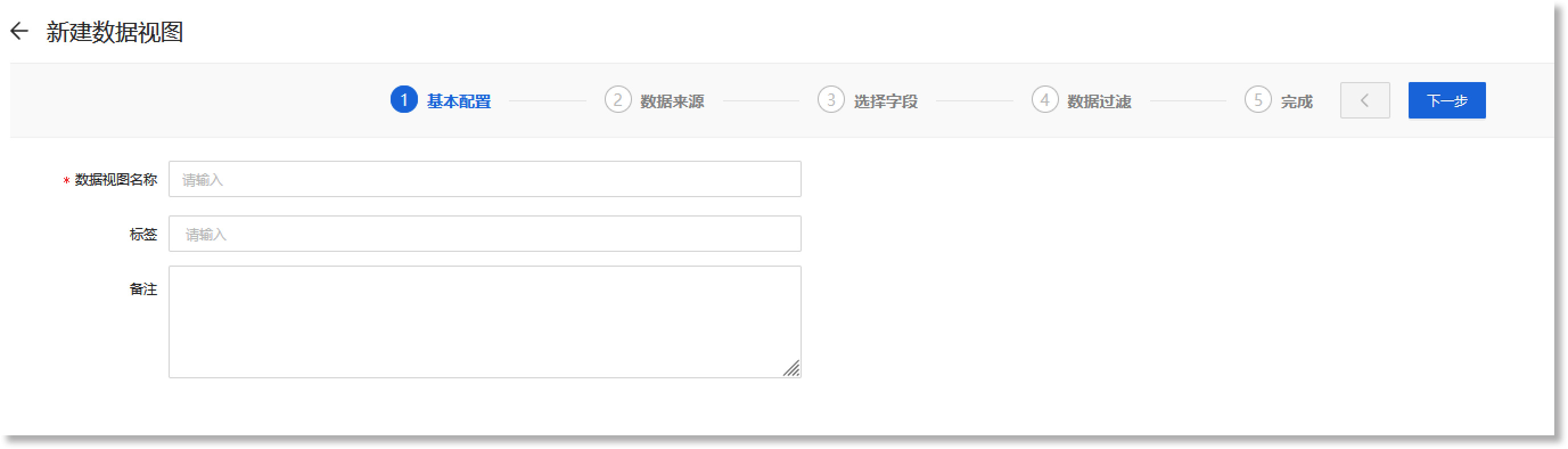
配置参数说明如下:
| 配置参数 | 参数说明 | 限制条件 |
| *数据视图名称 |
填写数据视图的名称,此名称具有全局唯一性。 |
• 数据视图名称不能重复,且不能为空; • ≤40个字符 |
| 标签 | 根据实际需求设置数据视图的标签信息,用于业务标识。可通过回车键添加多个标签。 |
• 最多支持创建5个标签 |
| 备注 | 根据实际需求填写数据视图的其他属性信息。 |
• ≤255个字符 |
![]() 说明:点击【下一步】,系统会对限制条件进行校验,并进行报错提示。
说明:点击【下一步】,系统会对限制条件进行校验,并进行报错提示。
完成“基本配置”参数配置后,点击【下一步】进入“数据来源”配置步骤页面,如下所示:
![]() 说明:若需要退回至上一配置步骤,点击配置步骤条的“
说明:若需要退回至上一配置步骤,点击配置步骤条的“![]() ”按钮,即可返回。
”按钮,即可返回。
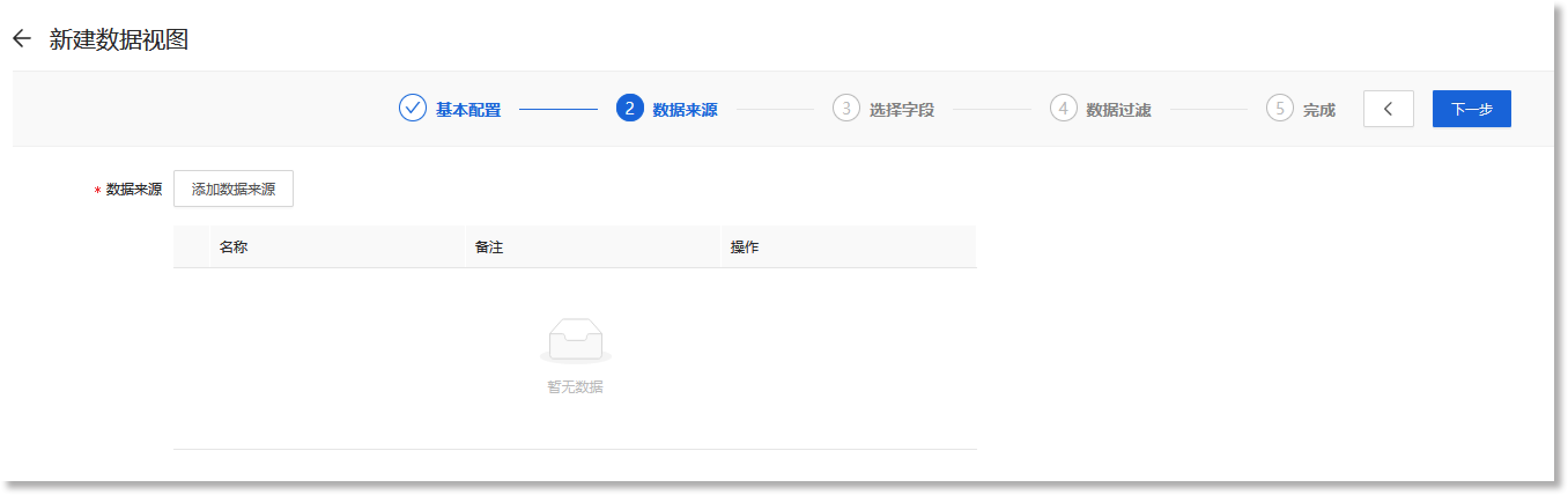
点击【添加数据来源】按钮,在页面右侧弹出的“添加索引库”抽屉中,选择数据视图的来源索引库,如下所示:

![]() 说明:数据来源为必填项。配置时,需要至少选择一个索引库,同时支持配置多个索引库。若未选择,点击【下一步】时系统会弹出报错提示。
说明:数据来源为必填项。配置时,需要至少选择一个索引库,同时支持配置多个索引库。若未选择,点击【下一步】时系统会弹出报错提示。
完成数据视图的“数据来源”参数配置后,点击【下一步】进入“选择字段”配置步骤页面,根据数据查询需求自行定义数据视图包含的字段,如下所示:
![]() 说明:若需要退回至上一配置步骤,点击配置步骤条的“
说明:若需要退回至上一配置步骤,点击配置步骤条的“![]() ”按钮,即可返回。
”按钮,即可返回。
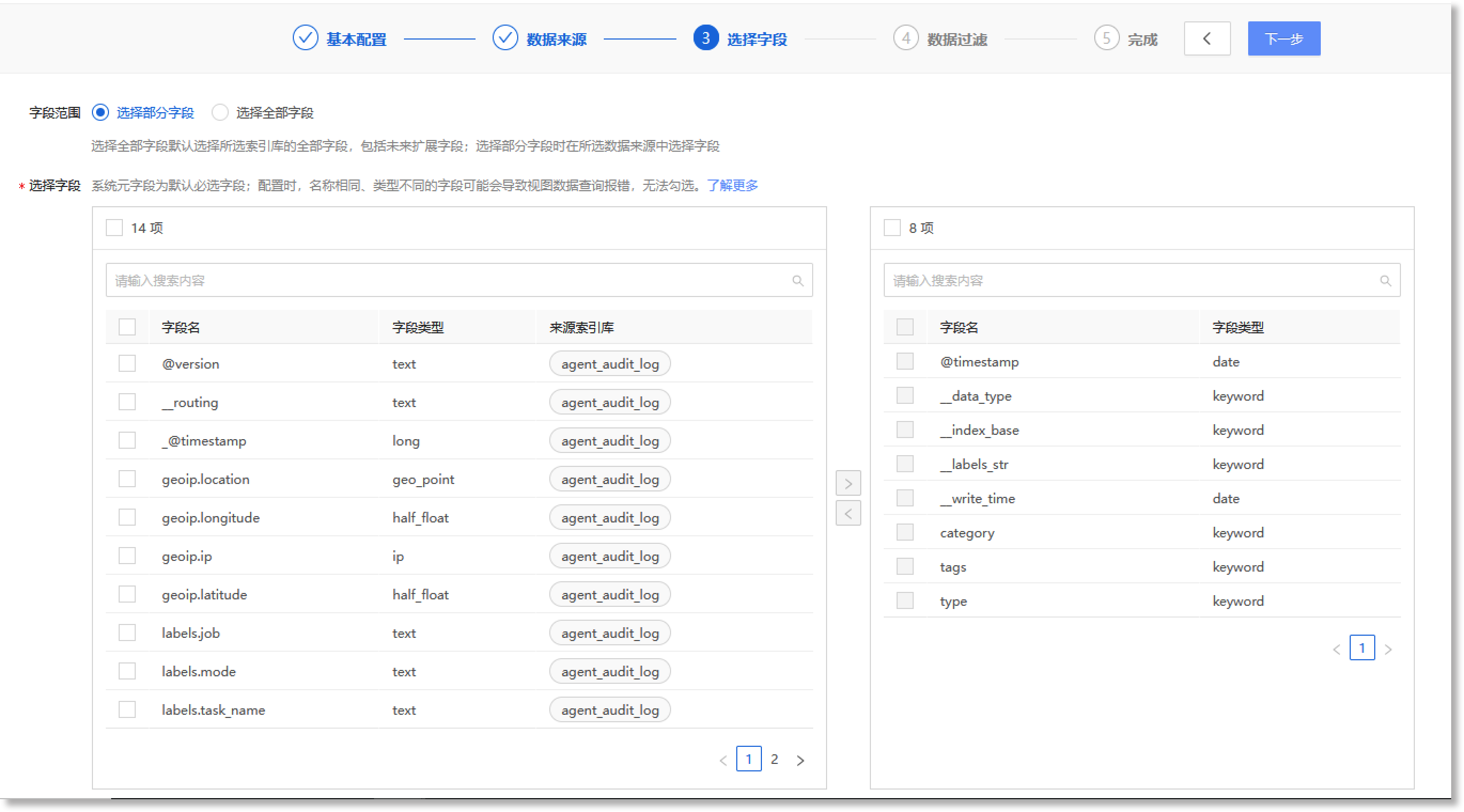
配置参数说明如下:
| 配置参数 | 参数说明 |
| 字段范围 |
根据实际需求选择数据视图需要包含的字段范围,可选项:选择部分字段、选择全部字段。“选择全部字段”即选择所选索引库中的全部字段,包括未来拓展字段。“选择部分字段”时,需要进一步配置所需字段,详情请参见*选择字段配置项。 |
| *选择字段 |
当字段范围“选择部分字段”时,此项可配置,且为必填项。 "选择字段"配置界面的左侧是来源索引库中所有可选择的字段池,右侧为此数据视图中已包含的字段池。在左侧区域勾选所需字段后(支持勾选多个),点击两个字段池中间的右箭头“ 注意: 1. 右侧备选字段池中默认包含的字段为系统元字段。系统元字段为默认必选字段,不支持删除或修改; 2.当数据视图的数据来源中配置了多个索引库,需注意多个索引库是否存有相同字段,以及此字段的字段类型是否冲突,具体情况为:
|
在将所需字段全部添加至备选字段池后,点击【下一步】即可。
进入"数据过滤"配置步骤,此配置项为选填项。若无数据过滤需求,您需要点击“![]() ”按钮,删除“过滤条件”配置框后,再点击【下一步】方可跳过此步骤,并完成数据视图的配置操作。如下所示:
”按钮,删除“过滤条件”配置框后,再点击【下一步】方可跳过此步骤,并完成数据视图的配置操作。如下所示:
![]() 说明:若需要退回至上一配置步骤,点击配置步骤条的“
说明:若需要退回至上一配置步骤,点击配置步骤条的“![]() ”按钮,即可返回。
”按钮,即可返回。
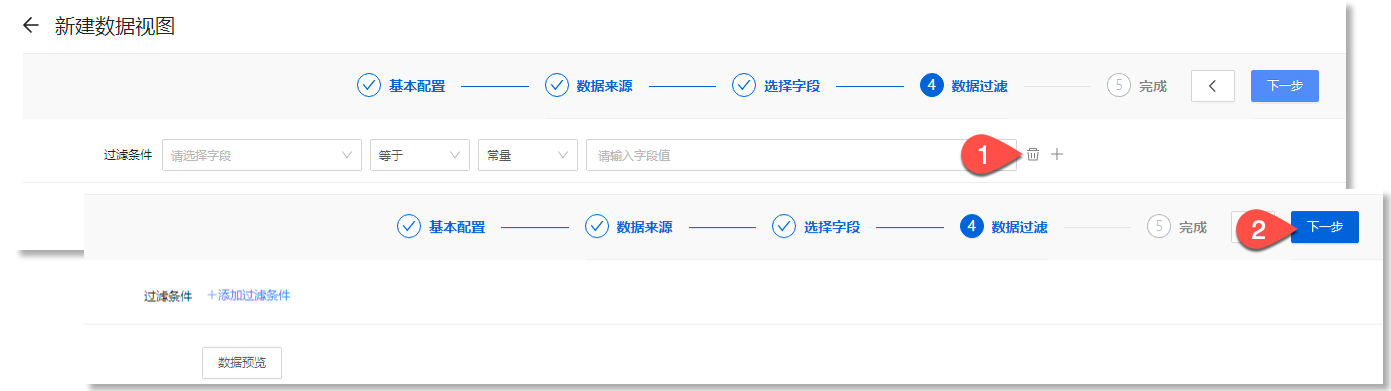
若有数据过滤需求,您需要根据实际数据需求配置过滤条件,在已选择的字段中筛选出满足需求的字段数据。如下所示:
| host |
| webserver1 |
| webserver2 |
| web2server1 |
| dbserver1 |
| mailserver1 |
-
筛选字段:表示需要进行过滤的字段名称。点击下拉框,在已配置的来源字段中选择,此处以“host”字段为例。
![]() 注意:当右侧运算符需配置为“相似(like)”、“不相似(not_like)“、”正则(regex)”时,此处配置的过滤字段必须为字符串类型,例如text、keyword类型。
注意:当右侧运算符需配置为“相似(like)”、“不相似(not_like)“、”正则(regex)”时,此处配置的过滤字段必须为字符串类型,例如text、keyword类型。
-
运算符:即过滤条件中使用的逻辑运算符。当左侧筛选字段的值与右侧配置的目标值满足指定运算符表示的逻辑关系时,命中此过滤条件。点击下拉框,支持配置以下运算符:
![]() 说明:当前支持添加19种运算符,具体包括:等于(eq)、不等于(ne)、大于(gt)、大于等于(gte)、小于(lt)、小于等于(lte)、属于(in)、不属于(not_in)、相似(like)、不相似(not_like)、包含(contain)、不包含(not_contain)、范围内(range)、范围外(out_range)、存在(exist)、不存在(not_exist)、正则(regex)、全文匹配(match)、短语匹配(match_phrase)。
说明:当前支持添加19种运算符,具体包括:等于(eq)、不等于(ne)、大于(gt)、大于等于(gte)、小于(lt)、小于等于(lte)、属于(in)、不属于(not_in)、相似(like)、不相似(not_like)、包含(contain)、不包含(not_contain)、范围内(range)、范围外(out_range)、存在(exist)、不存在(not_exist)、正则(regex)、全文匹配(match)、短语匹配(match_phrase)。
• 等于(eq):表示左侧指定筛选字段(此处为"host")的值与右侧配置的目标值完全相等,命中此过滤条件。例如,过滤条件为 “host eq webserver1” ,表示筛选出host字段值等于“webserver1”的数据,即:
| host |
| webserver1 |
![]() 注意:右侧配置的目标值需为单个值,不能为数组。否则无法实现精确相等的判定。
注意:右侧配置的目标值需为单个值,不能为数组。否则无法实现精确相等的判定。
• 不等于(ne):表示左侧指定筛选字段(此处为"host")的值与右侧配置的目标值不相等,命中此过滤条件;例如,过滤条件为 “host nq webserver1" ,表示筛选出host字段值不等于“webserver1”的数据,即:
| host |
| webserver2 |
| web2server1 |
| dbserver1 |
| mailserver1 |
![]() 注意:右侧配置的目标值需为单个值,不能为数组。否则无法实现精确不相等的判定。
注意:右侧配置的目标值需为单个值,不能为数组。否则无法实现精确不相等的判定。
• 大于(gt):表示左侧指定筛选字段(此处为"host")的值大于右侧配置的目标值,命中此过滤条件;
![]() 注意:右侧配置的目标值需为单个值,不能为数组。
注意:右侧配置的目标值需为单个值,不能为数组。
• 大于等于(gte):表示左侧指定筛选字段(此处为"host")的值大于或等于右侧配置的目标值,命中此过滤条件;
![]() 注意:右侧配置的目标值需为单个值,不能为数组。
注意:右侧配置的目标值需为单个值,不能为数组。
• 小于(lt):表示左侧指定筛选字段(此处为"host")的值小于右侧配置的目标值,命中此过滤条件;
![]() 注意:右侧配置的目标值需为单个值,不能为数组。
注意:右侧配置的目标值需为单个值,不能为数组。
• 小于等于(lte):表示左侧指定筛选字段(此处为"host")的值小于或等于右侧配置的目标值,命中此过滤条件;
![]() 注意:右侧配置的目标值需为单个值,不能为数组。
注意:右侧配置的目标值需为单个值,不能为数组。
• 属于(in):表示左侧指定筛选字段(此处为"host")的值属于右侧配置的目标值数组中的一个,命中此过滤条件;例如,过滤条件为 ”host in [webserver1, dbserver1, mailserver1]“,表示筛选出host字段值包含在指定数组中的数据 ,即:
| host |
| webserver1 |
| dbserver1 |
| mailserver1 |
![]() 注意:右侧配置的目标值需为一个或多个相同类型的值组成的数组。
注意:右侧配置的目标值需为一个或多个相同类型的值组成的数组。
• 不属于(not_in):表示左侧指定筛选字段(此处为"host")的值不在右侧配置的目标值数组中的任何一个,命中此过滤条件;例如,过滤条件为 ”host not_in [webserver1, dbserver1, mailserver1]“,表示筛选出host字段值不包含在指定数组中的数据 ,即:
| host |
| webserver2 |
| web2server1 |
![]() 注意:右侧配置的目标值需为一个或多个相同类型的值组成的数组。
注意:右侧配置的目标值需为一个或多个相同类型的值组成的数组。
• 相似(like):表示左侧指定筛选字段(此处为"host")的值与右侧配置的字符串存在相似的子串,命中此过滤条件。例如,过滤条件为 “host like ’web%‘”,表示筛选出host字段值以 "web" 开头的数据,即:
| host |
| webserver1 |
| webserver2 |
| web2server1 |
![]() 注意:右侧配置的目标值需为字符串。
注意:右侧配置的目标值需为字符串。
• 不相似(not_like):表示左侧指定筛选字段(此处为"host")的值与右侧配置的字符串不存在相似的子串,命中此过滤条件。例如,过滤条件为 host not_like "%server1%",表示筛选出host字段值不包含 "server1" 的数据,即:
| host |
| webserver2 |
![]() 注意:右侧配置的目标值需为字符串。
注意:右侧配置的目标值需为字符串。
• 包含(contain):表示左侧指定筛选字段(此处为"host")的值包含了右侧配置的单个目标值或目标值数组中的所有值,命中此过滤条件。例如,过滤条件为 ‘host contain "web"’,表示筛选出host字段值包含 "web" 的数据,即:
| host |
| webserver1 |
| webserver2 |
| web2server1 |
![]() 注意:左侧指定筛选字段(此处为"host")的值为数组,右侧配置的目标值需为单个值或数组。若右侧目标值为数组,则当数组中的所有值都在左侧指定字段值的数组内时,方可命中此过滤条件。
注意:左侧指定筛选字段(此处为"host")的值为数组,右侧配置的目标值需为单个值或数组。若右侧目标值为数组,则当数组中的所有值都在左侧指定字段值的数组内时,方可命中此过滤条件。
• 不包含(not_contain):表示左侧指定筛选字段(此处为"host")的值不能包含右侧配置的单个目标值或目标值数组中的所有值,命中此过滤条件。例如,过滤条件为 "host not_contain ‘server1’",表示筛选出host字段值不包含 "server1" 的记录,即:
| host |
| webserver2 |
![]() 注意:左侧指定筛选字段(此处为"host")的值为数组,右侧配置的目标值需为单个值或数组。若右侧目标值为数组,则当数组中的所有值都在左侧指定字段值的数组外时,方可命中此过滤条件。
注意:左侧指定筛选字段(此处为"host")的值为数组,右侧配置的目标值需为单个值或数组。若右侧目标值为数组,则当数组中的所有值都在左侧指定字段值的数组外时,方可命中此过滤条件。
• 范围内(range):表示左侧指定筛选字段(此处为"host")的值在右侧目标值范围内,命中此过滤条件。例如,过滤条件为 “host out_range [‘a’, ’n‘]”,表示筛选出在指定范围内的主机名称的记录,即:
| host |
| dbserver1 |
| mailserver1 |
![]() 注意:右侧目标值需配置为长度为2的数组,边界为左闭右开,即 [ value[0], value[1] )。此种情况下,符合过滤条件的值区间为 [ value[0], value[1] ),即左侧指定字段值中 ≥value[0] 且<value[1] 的值。
注意:右侧目标值需配置为长度为2的数组,边界为左闭右开,即 [ value[0], value[1] )。此种情况下,符合过滤条件的值区间为 [ value[0], value[1] ),即左侧指定字段值中 ≥value[0] 且<value[1] 的值。
• 范围外(out_range):表示左侧指定筛选字段(此处为"host")的值在右侧目标值范围外,命中此过滤条件。例如,过滤条件为 ”host out_range [’a‘, ‘n’]“,表示筛选出不在指定范围内的主机名称的数据,即:
| host |
| webserver1 |
| webserver2 |
| web2server1 |
![]() 注意:右侧目标值需配置为长度为2的数组,边界为左闭右开, 即 [ value[0], value[1] )。此种情况下,符合过滤条件的值的区间为 (-inf, value[0] ) & [ value[1], +inf ),即左侧指定字段值中<value[0] 或 ≥value[1] 的值。
注意:右侧目标值需配置为长度为2的数组,边界为左闭右开, 即 [ value[0], value[1] )。此种情况下,符合过滤条件的值的区间为 (-inf, value[0] ) & [ value[1], +inf ),即左侧指定字段值中<value[0] 或 ≥value[1] 的值。
• 存在(exist):表示存在左侧指定筛选字段(此处为"host")的数据,将命中此过滤条件。例如,过滤条件为 ‘host exist’,表示筛选出存在host字段的数据;
• 不存在(not_exist):表示不存在左侧指定筛选字段(此处为"host")的数据,将命中此过滤条件。例如,过滤条件为 ‘host not_exist’,表示筛选出不存在host字段的数据;
• 正则(regex):表示左侧指定筛选字段(此处为"host")的值匹配了右侧配置的正则表达式时,命中此过滤条件。例如,过滤条件为 host regex "^web",表示筛选出host字段值以 "web" 开头的数据,即:
| host |
| webserver1 |
| webserver2 |
| web2server1 |
• 全文匹配(match):表示左侧指定筛选字段(此处为“host”)的值包含了右侧目标值中的所有词汇,即仅需词汇匹配,词汇之间的间隔及顺序无需完全一致,命中此过滤条件。例如,过滤条件为"host match ‘server 2’",表示筛选出包含host字段值同时包含“server” 和 “2“的数据,即:
| host |
| webserver2 |
| web2server1 |
![]() 注意:string、number、date类型的字段都可以使用全文匹配(match)运算符。使用时,配置的筛选字段除了可以指定为某一单个字段外,也可以指定全部字段(即筛选字段配置为“*”),表示目标值将与来源索引库的所有字段的值进行匹配。
注意:string、number、date类型的字段都可以使用全文匹配(match)运算符。使用时,配置的筛选字段除了可以指定为某一单个字段外,也可以指定全部字段(即筛选字段配置为“*”),表示目标值将与来源索引库的所有字段的值进行匹配。
• 短语匹配(match_phrase):表示左侧指定筛选字段(此处为“host”)的值与右侧目标值中的词汇完全匹配,即词汇、词汇之间的间隔及顺序完全一致时,方可命中此过滤条件。例如,过滤条件为"host match_phrase ‘server 2’",表示筛选出host字段值与 "server 2" 完全一致的数据,即无符合条件的数据;若过滤条件为"host match_phrase ‘server2’",则筛选出的数据如下:
| host |
| webserver2 |
![]() 注意:string、number、date类型的字段都可以使用短语匹配(match_phrase)运算符。使用时,配置的筛选字段除了可以指定为某一单个字段外,也可以指定全部字段(即筛选字段配置为“*”),表示目标值将与来源索引库的所有字段的值进行匹配。
注意:string、number、date类型的字段都可以使用短语匹配(match_phrase)运算符。使用时,配置的筛选字段除了可以指定为某一单个字段外,也可以指定全部字段(即筛选字段配置为“*”),表示目标值将与来源索引库的所有字段的值进行匹配。
• 有效值类型:表示过滤条件中,用于与左侧字段值比较的目标值的数据类型,当前仅支持"常量",即过滤条件直接使用指定的常量值作为目标值,而非从数据集或其他字段中提取的值。
• 目标值:表示过滤条件中用于与字段值比较的目标值。
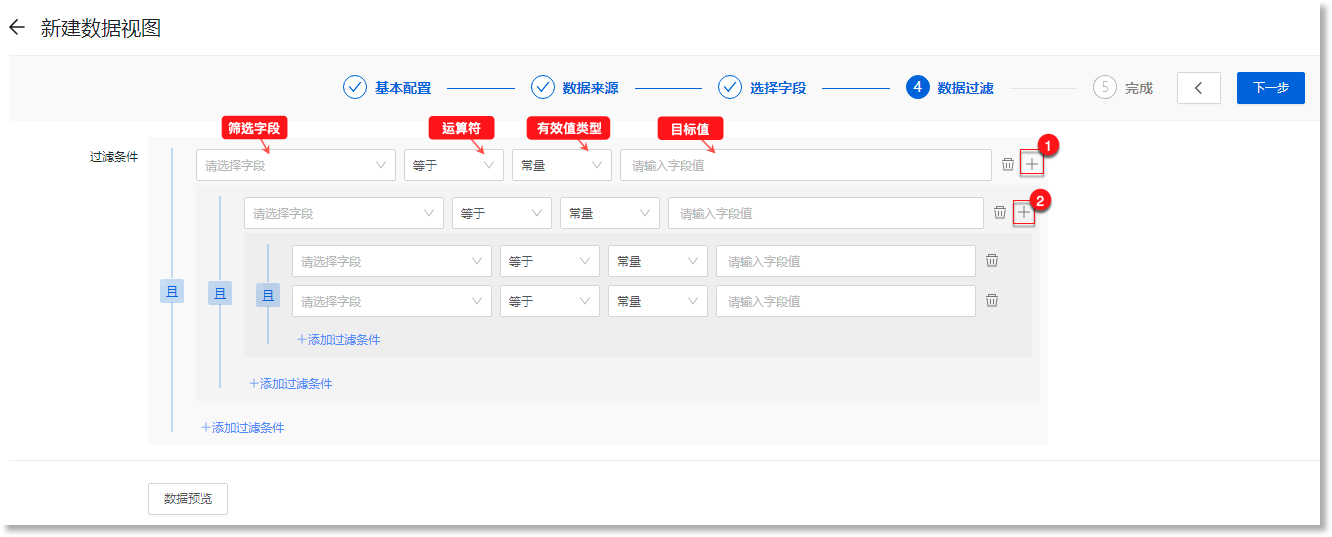
› 添加多层级过滤条件
支持添加多层级过滤条件,当前最多支持添加3层级的过滤条件,点击“![]() ””
””![]() “按钮,即可依次添加;点击添加按钮左侧的“
“按钮,即可依次添加;点击添加按钮左侧的“![]() “按钮,即可删除对应层级的过滤条件。多层级过滤条件之间支持配置“且”与“或”关系,点击对应层级的“
“按钮,即可删除对应层级的过滤条件。多层级过滤条件之间支持配置“且”与“或”关系,点击对应层级的“![]() ”按钮,即可切换多层级过滤条件的关联关系为“或”。
”按钮,即可切换多层级过滤条件的关联关系为“或”。
› 添加多个过滤条件
同一层级的过滤条件支持添加多个过滤条件,当前同一层级最多支持添加10个过滤条件,点击过滤条件下方的”+添加过滤条件“,即可添加;点击过滤条件尾部的“![]() “按钮,即可删除对应过滤条件。
“按钮,即可删除对应过滤条件。
您可以在创建、修改数据视图的过程中,点击“数据过滤”步骤条下方的【数据预览】按钮,预览数据视图的数据样例,及时根据需求调整数据视图的配置参数。如下所示:

![]() 说明:默认支持查询10条数据。
说明:默认支持查询10条数据。
完成所有参数配置后,点击【下一步】即可完成数据视图的创建操作。数据视图成功创建后,您可以基于数据视图ID进行数据查询。
进入数据视图配置页面,点击列表上方的【导入】按钮,在弹出的窗口中选中包含数据视图配置信息的文件,点击【打开】后即可批量导入并创建数据视图。
注意:
1. 仅支持导入json格式的文件;
2. 支持导入多个数据视图:导入时,若数据视图绑定的来源索引库不存在,则导入操作失败。您需在完成对应索引库的创建后,再进行导入操作;
3. 若AnyRobot中存有重名的数据视图对象,则导入动作将会停止,导入操作失败;
4. 批量导入失败后,您可在审计日志中查看对应的“失败”记录。
在数据视图列表中勾选某一视图后,点击列表上方的【导出】按钮,可将已创建的数据视图配置参数以“.json”格式导出,供其他场景快速应用。
提示:支持导出多个数据视图。
› 其他管理功能
进入数据管理>数据模型>数据视图配置页面,数据视图管理列表中展示了系统当前已存的所有数据视图,如下所示:

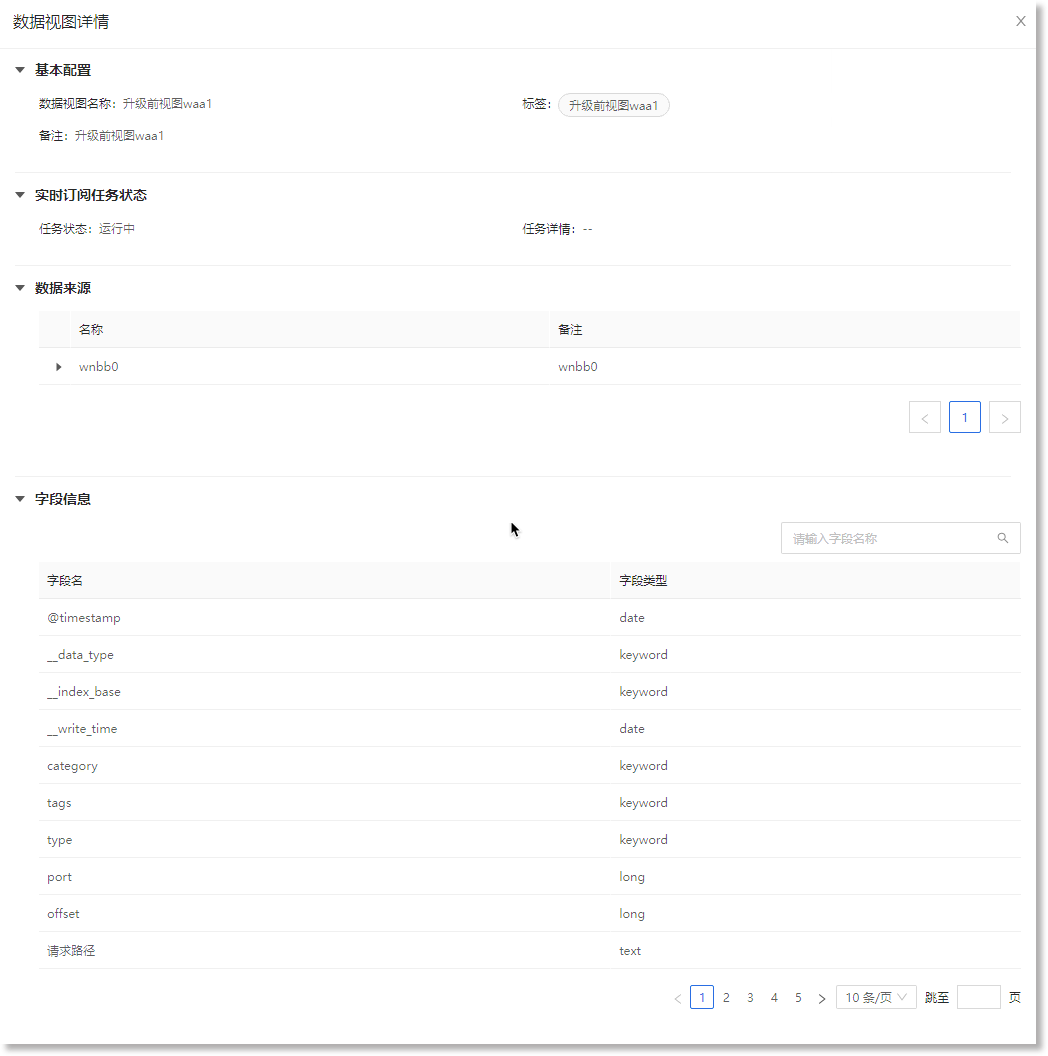
点击数据视图列表中指定数据视图“操作”列的“查看”按钮,在右侧弹出的“数据视图详情”抽屉中可以查看此视图的配置详情,包括视图基本配置信息、实时订阅任务的运行状态(仅开启此任务的数据视图展示此信息)、视图的来源数据、包含的字段信息等。如下所示:
点击数据视图列表中指定数据视图“操作”列的“编辑/删除”按钮后,可以“修改/删除”此数据视图。
![]() 说明:
说明:
1. 对于由日志分组升级上来的数据视图,进行编辑操作时,“过滤条件”配置步骤页面将新增展示日志分组的过滤条件。需注意此过滤条件仅支持删除,不支持修改操作。
2. 数据视图被删除后,您可在审计日志中查看相应的“删除”日志。
实时数据流订阅功能依托于AnyRobot流式、批量、即席一体化的实时处理架构,用于确保数据在采集和加工后,能够迅速且准确地提供给AnyRobot的下游数据应用环节,从而最大限度的缩短数据处理周期,满足用户在大数据量场景下的即时业务需求,如实时监控告警等。同时,这种实现方式也为数据在数据处理、查询等场景中的应用提供了可复用性,有效降低了数据集成的成本和复杂性。
完成数据视图的创建操作后,您可以进入数据视图管理列表管理其实时订阅功能。如下所示,数据视图的【允许实时订阅】开关默认处于“![]() ”关闭状态,点击即可切换至“
”关闭状态,点击即可切换至“![]() ”开启状态。开启后,数据视图将按照默认配置进行实时数据复制,将此数据视图来源索引库topic的数据复制到默认topic,以供AnyRobot的其他数据应用模块订阅。如下所示:
”开启状态。开启后,数据视图将按照默认配置进行实时数据复制,将此数据视图来源索引库topic的数据复制到默认topic,以供AnyRobot的其他数据应用模块订阅。如下所示:
