您可以根据实际业务场景中的指标需求,通过定义说明指标计算规则的查询语句、指标度量单位等参数,创建适于不同数据类型(支持指标数据(Metric)、链路数据(Trace)、日志数据(Log)及事件数据(Event))的指标模型,同时支持配置指标模型的持久化任务,用于实现指标数据的持久化。
› 创建指标模型
_61.png) 提示:您可以参照下方配置流程手动创建所需要的指标模型,也可以导入含有指标模型配置参数的合规文件批量创建指标模型。
提示:您可以参照下方配置流程手动创建所需要的指标模型,也可以导入含有指标模型配置参数的合规文件批量创建指标模型。
配置流程如下:
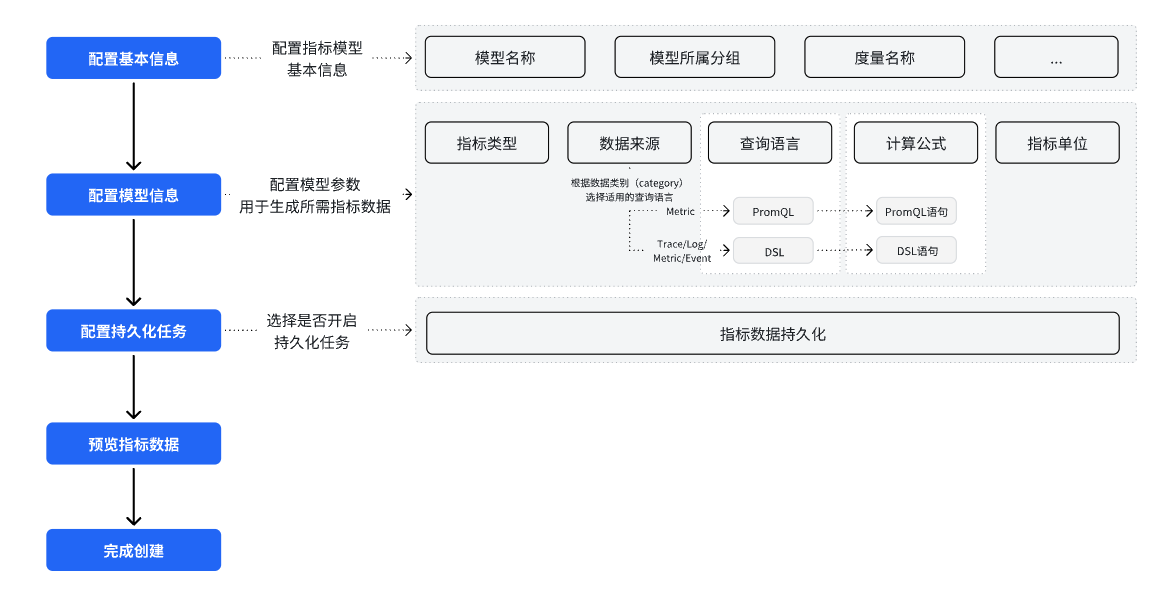
快速阅读链接如下:
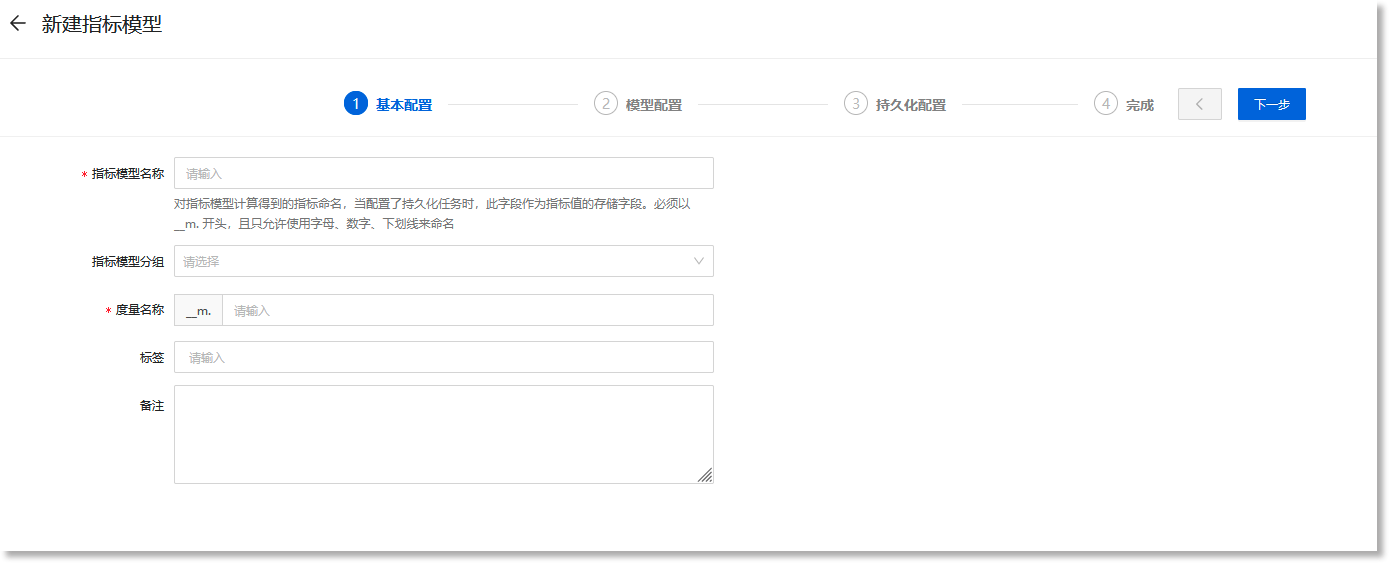
进入数据管理 > 数据模型 > 指标模型配置页面,点击【+新建】,进入“新建指标模型”的配置流程,如下所示:
配置参数说明如下:
| 配置参数 | 参数说明 | 限制条件 |
| *指标模型名称 | 填写指标模型的名称 |
• 指标模型名称不能重复,且不能为空; • ≤40个字符 |
| 指标模型分组 |
选填项。选择指标模型所属的分组信息,若此指标模型未指定分组,则自动分组至"默认分组"下。 |
- |
| *度量名称 | 必填项。当指标模型配置持久化任务后,此字段将作为指标持久化后存储的字段。 |
• 度量名称全局唯一不能重复,且不能为空; • 度量名称必须以特殊字符(__m.)开头,此前缀不允许被修改; • 度量名称的自定义部分只允许以字母、数字开头,且只允许包含字母、数字、下划线,不允许使用英文句号 |
| 标签 | 根据实际需求设置指标模型的标签信息,用于业务标识。可通过回车键添加多个标签。 | • 最多支持创建5个标签 |
| 备注 | 根据实际需求填写指标模型的其他属性信息 | • ≤255个字符 |
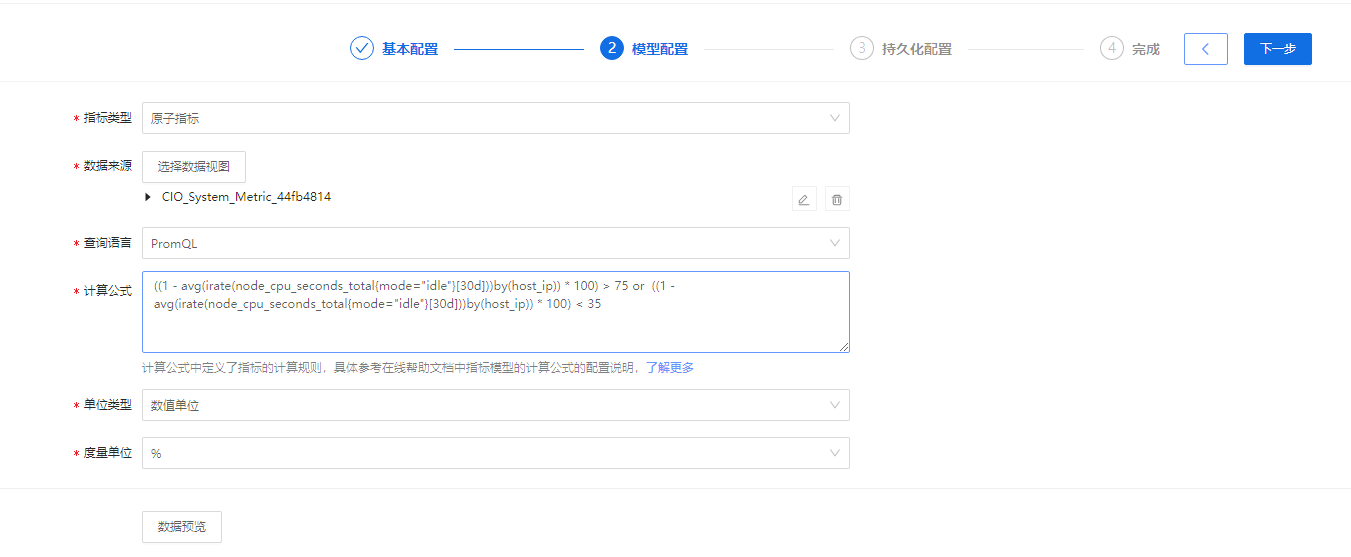
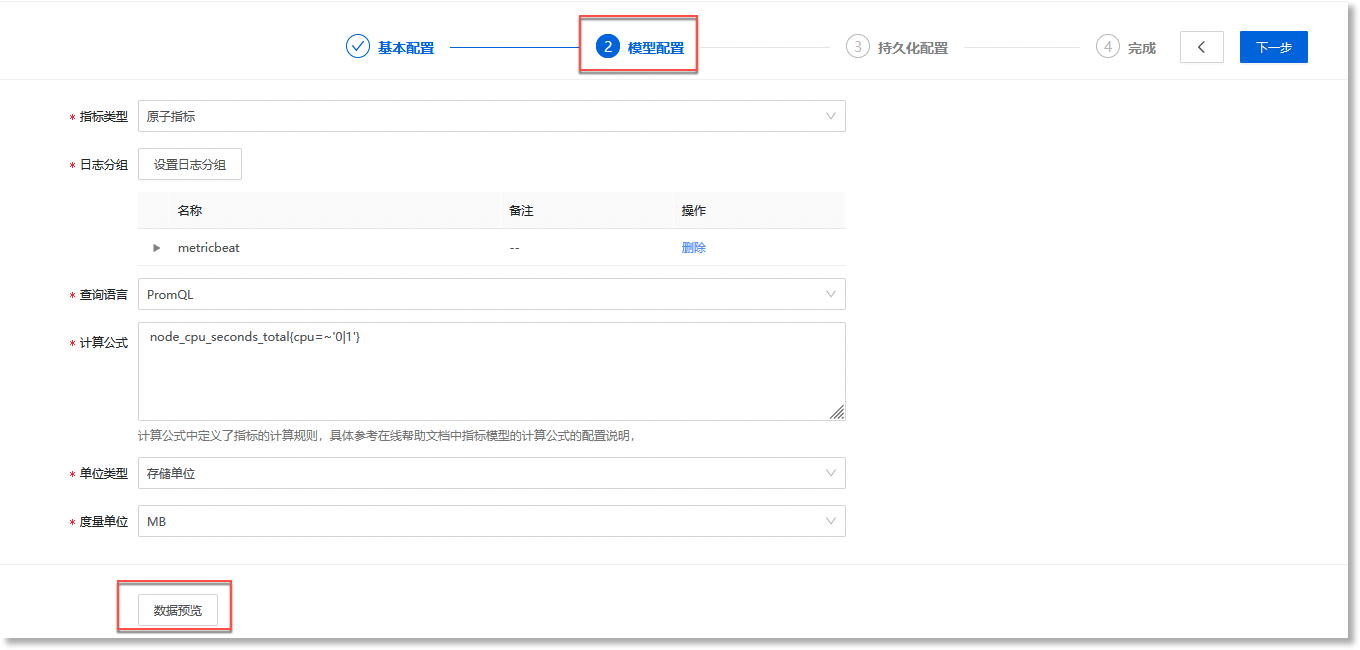
完成"基本配置"后,点击配置步骤条右侧的【下一步】,进入“模型配置”步骤页面,如下所示:
配置参数说明如下:
• *指标类型:在下拉框中选择指标的类型,默认为“原子指标”。原子指标可以理解为是对指标计算逻辑、具体算法的第一层抽象,皆在从根源上规范指标的定义,以保证指标的一致性。
说明:指标类型为必选项,当前仅支持配置“原子指标”。
• *数据视图:点击【设置数据视图】后,在弹出的"选择数据视图"抽屉中配置数据来源所属的数据视图。
说明:1. 数据视图为必填项。配置时,仅支持配置1个数据视图;
2. 若找不到需要的数据视图,您可以点击抽屉最下方的“新建数据视图”进行创建。
• *查询语言:您需根据数据源的数据类别(category)选择适用的查询语言,可选项:PromQL、DSL。具体如下:
说明:查询语言为必选项。
• *计算公式:根据上方已配置的*查询语言,填写用于说明指标计算规则的对应查询语句。配置生效后,系统会根据此处定义的计算公式进行指标计算,得到对应指标数据(请参见 预览指标数据了解详情)。
说明:计算公式为必填项。
1)当*查询语言选择“PromQL”时,需填写用于说明指标计算规则的PromQL查询语句,具体书写规范请参见《AnyRobot Eyes 5 UniQuery 开发者指南》2.3PromQL查询语言>2.3.1-2.3.4 章节,若获取此文档失败请联系相关技术支持人员。
2)当*查询语言选择“DSL”时,配置框中默认提供了计算公式(DSL语句)的预输入结构,指标模型通过此处配置的DSL语句实现对指定数据集的聚合查询操作,进而获取所需的指标数据(即返回的查询结果)。
具体配置时:
-若您所需的指标数据能够基于此预输入计算公式结构实现,您可以查阅下方› 预输入计算公式(DSL语句)配置说明,并结合实际需求修改少量参数,应用此预输入结构,快速配置所需计算公式;
-若您所需的指标数据需要基于其他聚合方式实现,您可以参考下方› 计算公式(DSL语句)基本规范说明,遵循不同聚合方式的合法格式,配置所需计算公式。
注意:此处配置的计算公式中,必须包含一层date_histogram(日期直方图)聚合和一层value_count(计数)聚合。
配置框中提供的预输入DSL语句为嵌套的聚合结构,包括过滤查询部分、嵌套的三层聚合查询部分。基于此结构的计算公式,其查询结果将返回一个多层嵌套的数据结构,此结果包含了按照指定字段值进行分组(terms聚合)后,在每个分组内再按照时间间隔分组后(date_histogram聚合)的统计值(value_count聚合)信息,如下所示:
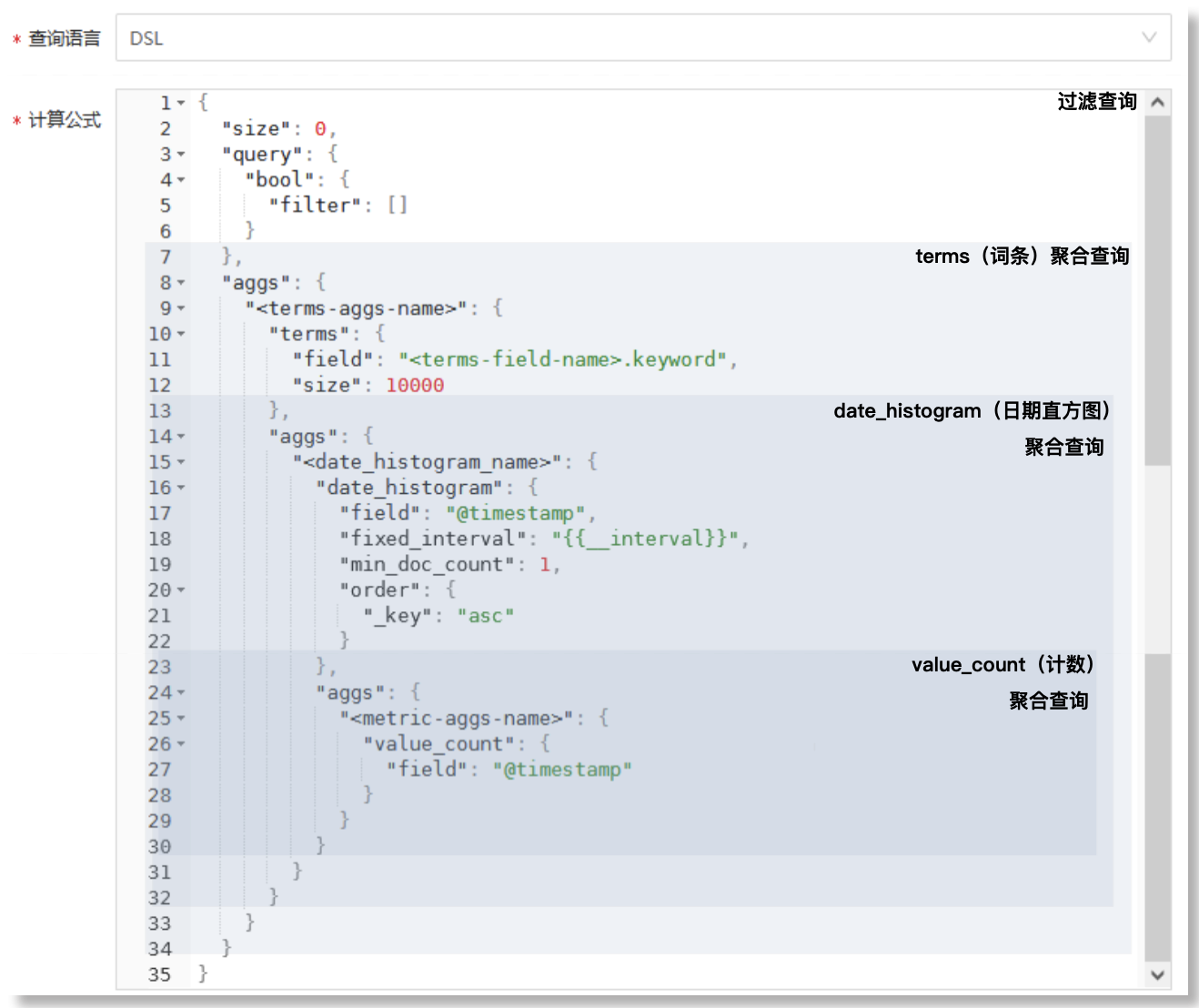
关于嵌套的三层聚合查询,每层聚合的查询结果说明如下:
-
-
- 最外层terms聚合:按照指定字段的值对来源数据进行分组
- 第二层的date_histogram聚合:在每个terms分组内,按照指定时间字段对数据进行分组
- 第三层的value_count聚合:统计每个时间段内文件数量(事件发生次数或数据记录数量)
-
若您所需的指标数据能够基于此预输入计算公式结构实现,您可以参照下方的简要配置提示,或查看下方的详细配置说明,配置所需计算公式。
» 下图为预输入计算公式(DSL语句)的简要配置说明。配置时,请参考下方说明,并结合实际需求进行:
-计算公式中尖括号"<>"标识的项(红框标识)为用户自定义配置项,您需要根据实际情况直接替换修改此参数;
-系统为计算公式中的某些项(灰框标识)提供了默认参数,您可以直接应用此类参数,也可以根据实际需求修改;
-系统对计算公式中的某些项(黑框标识)有强限制配置要求,具体限制请查看下图:
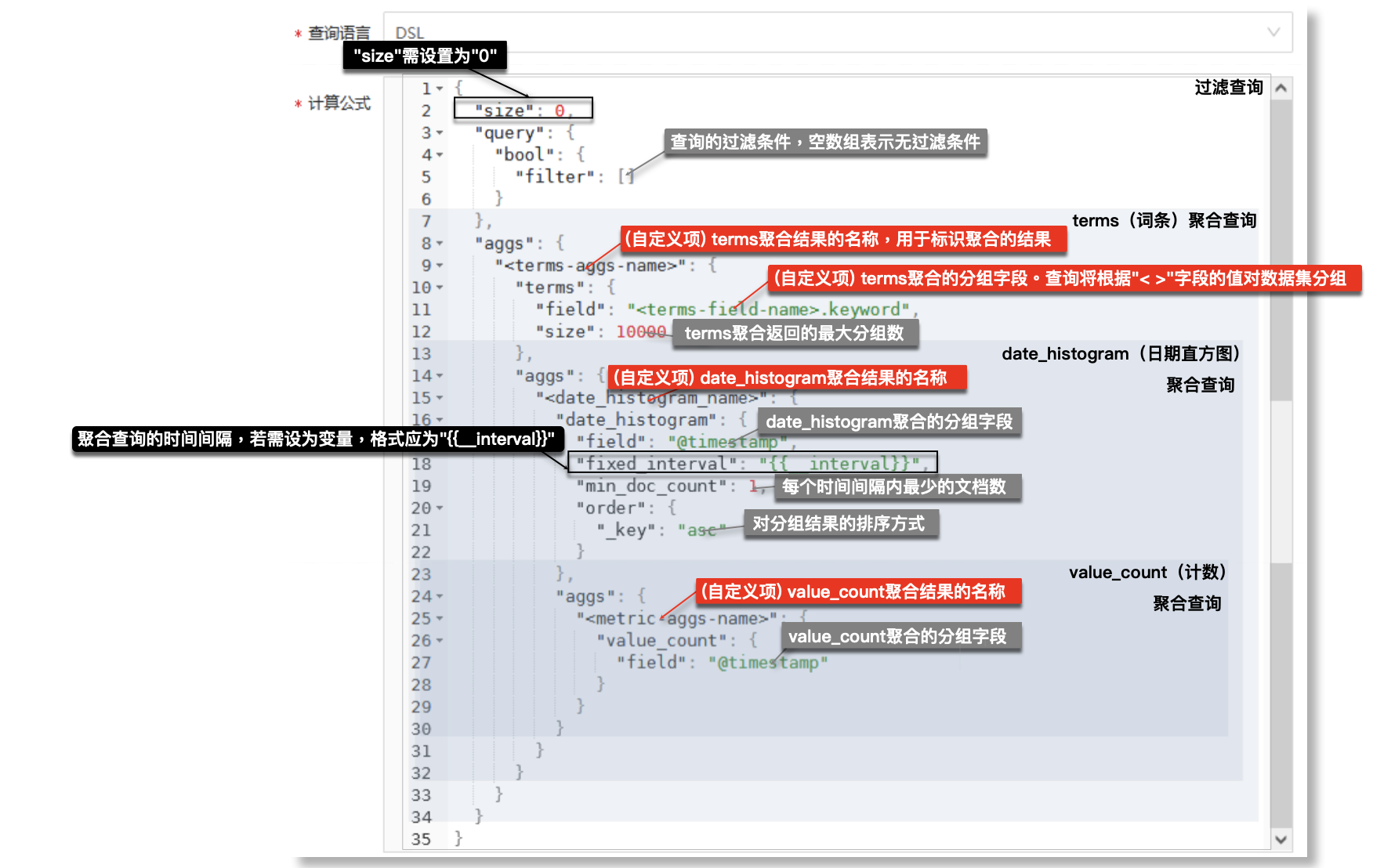
» 若需要了解此预输入计算公式结构及配置限制的详细说明,请具体参考下文。配置框中提供的预输入DSL语句为嵌套的聚合结构,包括过滤查询部分、聚合查询部分。
• 过滤查询部分
| 键 | 含义 |
size |
size需设置为0。表示查询结果只返回聚合结果,不返回文档数据。 |
query |
表示这是一个查询操作。 |
bool |
布尔查询部分 |
filter |
查询的过滤条件。此处filter为空数组,表示此查询没有筛选条件,即查询时会匹配所有文档。可根据实际需求自行定义查询必要的匹配条件,以筛选指定数据,书写格式可参见OpenSearch官网文档>Filter context的相关内容。 |
• 聚合查询部分
“aggs”部分具体定义了需执行的聚合查询操作,包括三层嵌套的聚合:terms(词条)聚合、date_histogram(日期直方图)聚合、value_count(计数)聚合。terms聚合将按照<terms-field-name>.keyword字段的值对所选数据集分组。每个分组内再执行date_histogram聚合,具体按照@timestamp字段的值进行时间分组,时间分组的具体时间间隔由{{__interval}}的具体参数决定。最后,每个时间间隔内再进行value_count值聚合,用于统计每个间隔内@timestamp字段值对应的文档数量,查询指标数据。此默认嵌套聚合结构,可用于实现根据指定时间间隔(按天/周/月)对指定对象类别下某一指标的统计分析,帮助进行时间趋势相关的数据分析及可视化。
提示:您可根据实际指标需求自行定义所需的聚合方式,详情请参见支持的聚合方式。
三层嵌套聚合的详细说明如下:
| 键 | 含义 |
aggs |
聚合查询部分 |
<terms-aggs-name> |
terms(词条)聚合结果的名称,用于标识此聚合的结果,您可根据实际需求自定义命名。 |
terms |
terms(词条)聚合部分。分桶聚合类型,用于根据指定字段的值对数据进行分组,并统计每个不同值对应的文档数量或计算其他度量指标。 |
field |
terms(词条)聚合的分组字段。此处field:<terms-field-name>.keyword表示聚合将根据<terms-field-name>.keyword字段值对数据集进行分组,您可根据实际需求定义分组字段,书写格式可参见OpenSearch官网文档>AGGREGATIONS>Terms aggregations的相关内容。 |
size |
terms(词条)聚合返回的分组数量。此处size:10000表示最多返回10000个不同值对应的分组。
提示: |
| 键 | 含义 |
aggs |
嵌套的date_histogram聚合查询部分。表示将在terms聚合的每个分组中进行的date_histogram聚合。 |
<date-histogram-name> |
date_histogram(日期直方图)聚合结果的名称,用于标识聚合操作的结果,您可根据需求自定义命名。 |
date_histogram |
date_histogram(日期直方图)聚合部分。分桶聚合类型,用于根据指定日期字段的值对数据进行分组,并统计指定的时间间隔内的文档数量或计算其他度量指标。 |
field |
date_histogram(日期直方图)聚合的分组字段。您可根据实际需求自定义分组所需的日期字段,书写格式可参见OpenSearch官网文档>AGGREGATIONS>Date histogram aggregation 的相关内容。 |
fixed_interval |
date_histogram分桶聚合下,支持使用fixed_interval(固定时间间隔)以及calendar_interval(日历感知时间间隔)定义时间分桶的间隔。
指标模型中,date_histogram聚合方式中 若设置为变量,格式应配置为 若设置为常量,表示此值不可修改,查询时无论查询范围是多少,分桶的时间间隔都不变。 |
calendar_interval |
• 当选择按照日历感知时间间隔进行分桶时,不支持配置为变量,当前支持的日历间隔如下:
• 当选择按照日历感知时间间隔进行分桶时,可指定时区(默认为
|
min_doc_count |
时间间隔内最少文档数。如:"min_doc_count":1 表示若某个时间间隔内文档数<1,则该时间间隔不会被包含在聚合结果中。 |
order |
表示将对分组结果进行排序。 |
_key |
分组结果的具体排序方式。如 |
| 键 | 含义 |
aggs |
嵌套的value_count(计数)聚合部分。 |
<metric-aggs-name> |
value_count(计数)聚合结果的名称,用于标识聚合操作的结果,您可根据需求自定义命名。 |
value_count |
value_count(计数)聚合部分。值聚合类型,用于统计指定字段中非空值的数量。 |
field |
value_count(计数)聚合需要统计的字段。如"field": "@timestamp"表示要统计的字段是@timestamp。 |
上文仅对预输入框架中示意的聚合方式进行了配置说明,若实际场景中需要使用其他聚合方式,请参考OpenSearch官网文档>Aggregations章节中对应聚合方式的示例结构书写。DSL计算公式的书写需遵循DSL语句的基本语法结构(具体请参见OpenSearch官网文档)及以下特有约束。
• 聚合方式及聚合层数约束
• 当前不支持并行聚合(Multiple aggregation)查询;
1)分桶聚合:date_histogram(日期直方图)、terms(词条)、filters(过滤)、range(范围)、date_range(日期范围);
2)值聚合:value_count(计数)、cardinality(去重计数)、sum(求和)、avg(均值)、max(最大值)、min(最小值)、top_hits(桶内排序取 Top N)。
• 支持配置的分桶聚合层数需≤7,值聚合层数需=1,各层聚合的聚合名称不能重复。
• 子聚合约束
• date_histogram(日期直方图)
• 计算公式中必须包含date_histogram,且只能有一个;
• date_histogram 分桶聚合下的子聚合类型需为值聚合。
• top_hits(桶内排序取 Top N)
• top_hits 需满足如下结构:
"size": <number>,"sort": [ { "<sort_field_name>": { "order": "desc | asc" } }],"_source": { "includes": [ "<field_name1>", "<field_name2>", ...... ]}
校验说明:
1. 完成指标模型的配置后,点击【数据预览】/【保存】按钮,系统将对计算公式(PromQL语句/DSL语句)的合法性进行校验,校验通过后,方可预览指标数据/成功创建指标模型;
2. 当前暂不支持对查询语句中字段的权限进行校验,若查询了数据视图中不存在的字段,数据查询结果则为空。
注意:当前版本仅支持DSL的时序分析。
• *度量字段:仅当*查询语言选择“DSL”时,此项可配置且为必填项,配置说明如下:
• 当计算公式中的值聚合方式为top_hits时,此处配置的度量字段应为top_hits中_source所包含的字段名称,且此字段名称对应的字段类型应为数值字段,不兼容日期。
• 当计算公式中的值聚合方式为其他类型时,此处配置的度量字段应为公式中的值聚合名称,若配置的度量字段与值聚合名称不匹配,系统将会报错。
说明:度量字段为必填项。
• *单位类型:根据实际指标需求设置输出指标(即“度量值”)的度量单位类型,可选项包括:数值单位、存储单位、时间单位、传输速率。
• *度量单位:根据实际指标需求设置输出指标(即“度量值”)的度量单位,不同单位类型下可选择的具体度量单位如下:
• 数值单位:无, 千, 百万, 十亿, 万亿,%
• 存储单位:Byte(s), KiB, MiB, GiB, TiB, PiB
• 时间单位:纳秒,微秒,毫秒, 秒, 分, 时, 天
• 传输速率:B/s, KiB/s, MiB/s
指标模型的数据持久化是指将指标模型查询到的指标数据存储到指定索引库中,确保数据的长期存储、保持数据历史状态,以实现基于所需指标数据在复杂场景中的计算,加速指标数据查询。
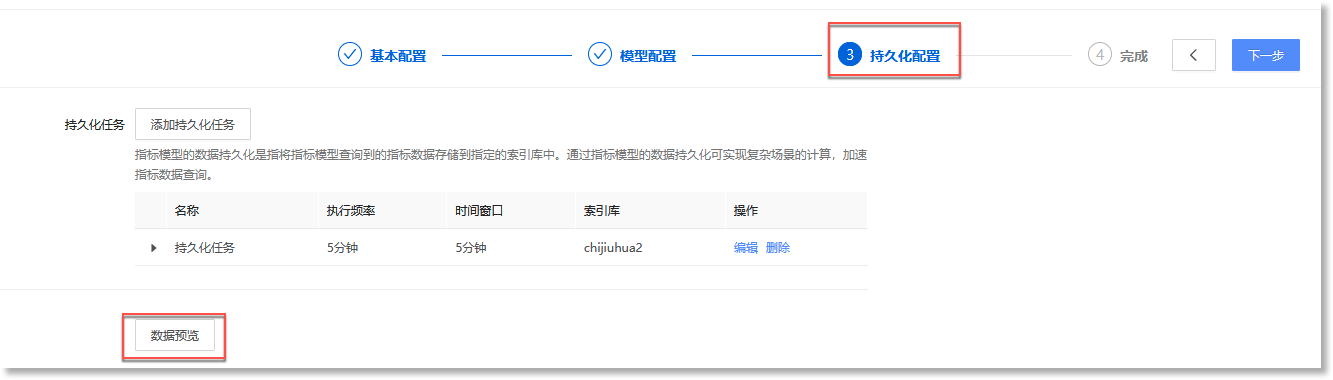
完成"模型配置"后,点击配置步骤条右侧的【下一步】进入“持久化配置”页面,如下所示:
注意:指标模型持久化配置默认为“关闭”状态,即默认不进行对应指标数据的持久化存储;
点击打开持久化配置开关“![]() ”,可以为此模型添加数据持久化任务,以便将模型查询到的指标数据存储到指定索引库中。如下所示:
”,可以为此模型添加数据持久化任务,以便将模型查询到的指标数据存储到指定索引库中。如下所示:
注意:开启“持久化配置”后,每个指标模型仅支持添加一个持久化任务。
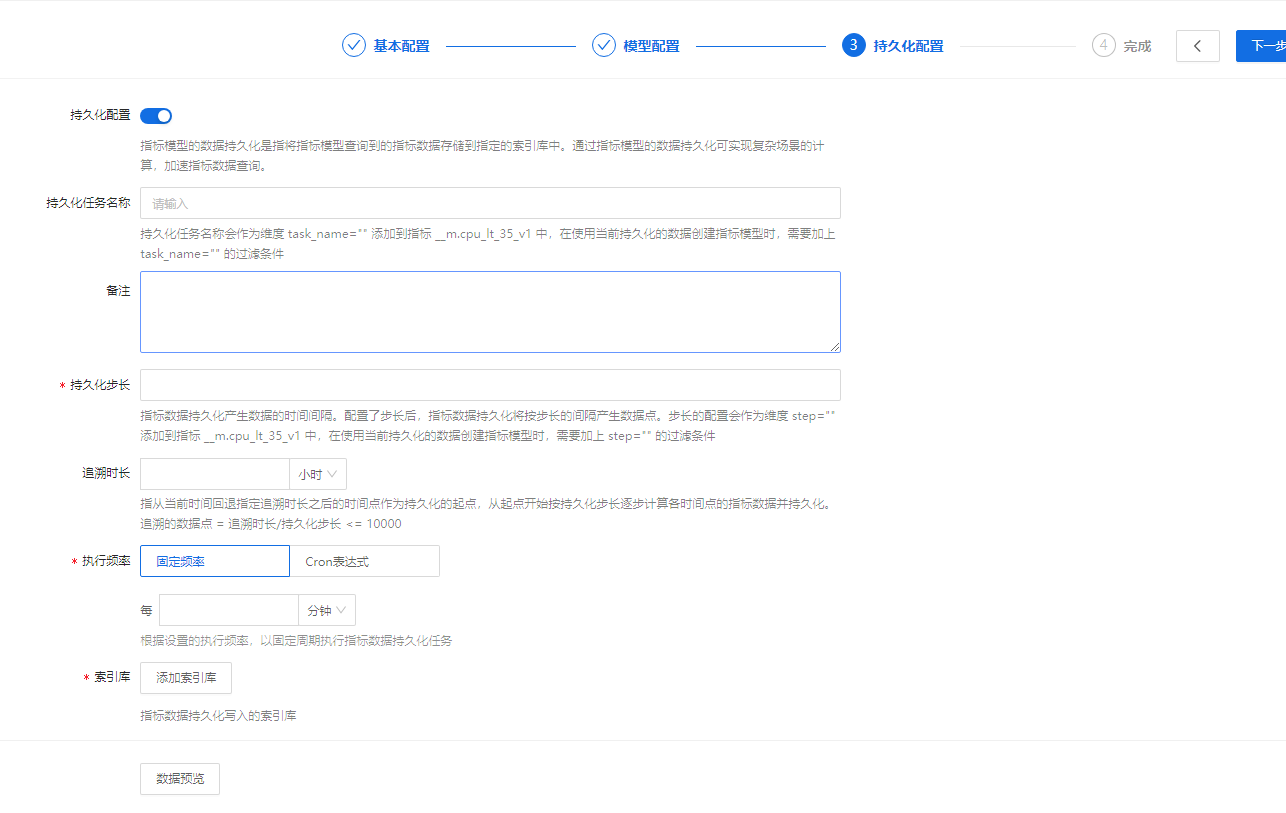
注意:指标模型查询语言为PromQL、DSL时,支持配置的持久化任务参数不同,具体请参见下方说明。配置参数说明如下:
• *持久化任务名称:持久化任务的任务名称,此名称将会作为维度字段(labels.task_name)写入到持久化的指标数据中。
说明:持久化任务名称为必填项,需要≤40个字符,不能为空,也不能重复。
• 备注:根据实际需求,填写持久化任务的其他属性信息。
说明:备注信息需要≤255个字符。
*时间窗口:设置指标模型查询指标数据的时间范围,用于获取指定时间段内的指标数据,进行持久化。点击【添加时间窗口】,在时间窗口输入框中填写正整数,选择时间窗口的时间单位,可选单位:分钟、小时、天。
说明:
1. 仅当查询语言为DSL时,此参数可配置,且为必填项;
2. 配置自定义时间窗口参数时,需要输入正整数数字;
3. 同一任务中,支持添加多个时间窗口,但不能重复添加;
4. 时间窗口会作为维度字段(labels.time_window)写入到持久化的指标数据中,在使用当前持久化的数据继续创建指标模型时,需添加“time_window={{*时间窗口}}”的过滤条件。
• *持久化步长:设置指标数据持久化时生成指标数据点的时间间隔。点击配置框,在下拉框中展示的系统固定持久化步长集中选择所需步长,当前支持配置:5分钟、10分钟、15分钟、20分钟、30分钟、1小时、2小时、3小时、6小时、12小时、1天。
说明:
1. 持久化步长为必填项,不能为空;
2. 当前持久化步长不支持配置为自定义参数;
3. 同一个持久化任务支持配置多个持久化步长,但不能重复添加;
4. 指标模型配置完成后,持久化步长参数将会作为维度字段(labels.step)写入到持久化的指标数据中,在使用当前持久化的数据继续创建指标模型时,需添加“step={{*持久化步长}}”的过滤条件。
1)当查询语言为PromQL,此参数也决定了指标模型查询指标数据的时间范围。例如,当持久化步长配置为5分钟时,则每隔5分钟,指标模型将查询当前时间点前5分钟的指标数据,计算生成指标数据点,并进行持久化存储。
特殊情况说明:查询语言为PromQL时,若计算公式中使用了 irate() 函数,持久化步长与数据查询的时间范围参数有如下情况:
-
- 若计算公式中的
range参数设置为auto,则持久化任务查询指标数据时,持久化步长参数也决定了查询指标数据的时间范围; - 若计算公式中的
range参数设置为常量,则持久化任务查询指标数据时,查询指标数据的时间范围由此常量决定。
- 若计算公式中的
2)当查询语言为DSL,此参数不影响指标模型查询指标数据的时间范围。例如,当持久化步长配置为5分钟,则每隔5分钟,指标模型将查询当前时间点前5分钟(时间范围由上方*时间窗口参数决定)的指标数据,计算生成指标数据点,并存入持久化数据。
特殊情况说明:查询语言为DSL时,若计算公式中使用了date_histogram聚合方式,持久化步长与数据查询的时间范围参数有如下情况:
-
- 若计算公式中
date_histogram使用了fixed_interval:- 若使用了变量
{{_interval}},则持久化任务在查询指标数据时,持久化任务配置的时间窗口参数决定了指标数据查询时的具体时间范围; - 若使用了常量,则持久化任务查询指标数据时,查询指标数据的时间范围由此常量决定。
- 若使用了变量
- 若计算公式中
date_histogram使用了calendar_interval,则持久化任务查询在指标数据时,查询指标数据的时间范围由此参数决定。
- 若计算公式中
• 追溯时长:追溯时长是指从当前时间向过去回退的时间长度,用于确定持久化数据的起始时间点。点击文本配置框,填写或点击“![]() ”按钮设置追溯时长,并选择其时间单位,可选单位:小时、天。例如,当追溯时长配置为“2天”,系统会从当前时间回退2天的时间点开始,并按照持久化任务配置信息,逐个步长计算历史数据点,进行数据持久化。即系统会根据持久化任务的配置信息补充前面2天的持久化数据点。
”按钮设置追溯时长,并选择其时间单位,可选单位:小时、天。例如,当追溯时长配置为“2天”,系统会从当前时间回退2天的时间点开始,并按照持久化任务配置信息,逐个步长计算历史数据点,进行数据持久化。即系统会根据持久化任务的配置信息补充前面2天的持久化数据点。
说明:追溯时长需要配置为正整数,追溯的数据点需要<=10000,追溯的数据点=追溯时长/持久化步长;完成指标模型的配置后,不支持修改此配置项。
• *执行频率:设置系统执行持久化任务的时间间隔,即持久化任务的运行频率。当前支持固定频率、Cron表达式两种配置方式,具体如下:
1)固定频率:点击文本配置框,填写或点击“”按钮配置具体时间间隔,并选择时间单位,可选单位:分钟、小时、天。例如:当固定频率设置为“每5分钟”,则此持久化任务每5分钟执行一次;
2)Cron表达式:Cron表达式是一个具有时间含义的字符串,用于计划任务。使用Cron表达式可以精准配置持久化任务的执行时间,包括持久化任务执行的具体时间点、任务执行间隔、任务执行频率。
-手动输入Cron表达式:点击文本配置框,您可以参考通用Cron语法,手动输入Cron表达式字符串,定义任务执行频率。Cron表达式以5个空格隔开,分为6个域,每个域可以是确定取值,也可以是具有逻辑意义的特殊字符。关于域取值及特殊字符的说明如下:
域取值(下表为Cron表达式中7个域允许的取值以及支持的特殊字符)
| 域 | 是否必须 | 取值范围 | 特殊字符 |
| 秒/Seconds | 是 | [0,59] | * , - / |
| 分钟/Minutes | 是 | [0,59] | * , - / |
| 小时/Hours | 是 | [0,23] | * , - / |
| 日期/DayofMonth | 是 | [1,31] | * , - / ? |
| 月份/Month | 是 | [1,12]或[JAN,DEC] | * , - / |
| 星期/DayofWeek | 是 | [1,7]或[MON,SUN] | * , - / ? |
特殊字符
| 特殊字符 | 含义 |
| * | 表示匹配该域的任意值。例如,在秒域用"*",表示每秒钟都会触发事件。 |
| , | 表示该域有多个取值。例如,在分钟域使用“5,10”,表示第5分钟、第10分钟会触发事件。 |
| - | 表示范围。例如,在小时域使用"5-7",表示从5到7点,即5,6,7点触发一次。 |
| / | 表示“起始时间/间隔时间”。例如,在分钟域使用“5/20”,表示从第5分钟开始,每隔20分钟触发一次,即5,25,45分钟。 |
| ? | 仅适用于日期、星期域,因为两个域会互相影响,因此可以将此字符理解为“无意义的值”。例如,想要设置每月20日触发事件,则星期域需使用"?",表示不论20日指向星期几都会触发事件。 |
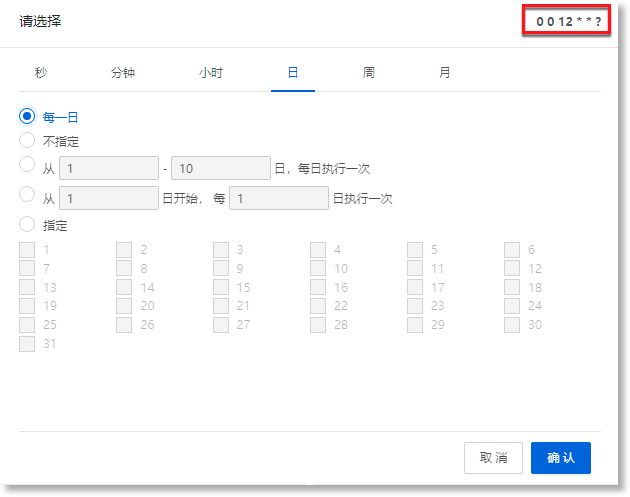
-勾选配置Cron任务:您也可以点击“![]() ”进入任务执行频率配置窗口,自行勾选Cron表达式每个域(秒/分钟/小时/日/周/月)的取值,配置窗口右上角会同步展示该执行频率对应的Cron表达式。例如:0 0 12 * * ?,表示每天中午12点执行一次。
”进入任务执行频率配置窗口,自行勾选Cron表达式每个域(秒/分钟/小时/日/周/月)的取值,配置窗口右上角会同步展示该执行频率对应的Cron表达式。例如:0 0 12 * * ?,表示每天中午12点执行一次。
说明:执行频率为必填项,不能为空。
• *索引库:选择存储持久化数据的索引库。
说明:索引库为必选项,不能为空。
在创建指标模型的过程中,完成指标模型基本信息以及模型信息的配置后,您可以点击“模型配置”步骤条或“持久化配置”步骤条下方的【数据预览】,预览基于当前配置参数生成的指标数据,便于及时根据实际需求调整指标模型的配置参数。如下图所示:
页面右侧弹出的抽屉中展示了此模型定义的指标数据,包括指定统计周期内的指标趋势图、指标数据,如下所示:
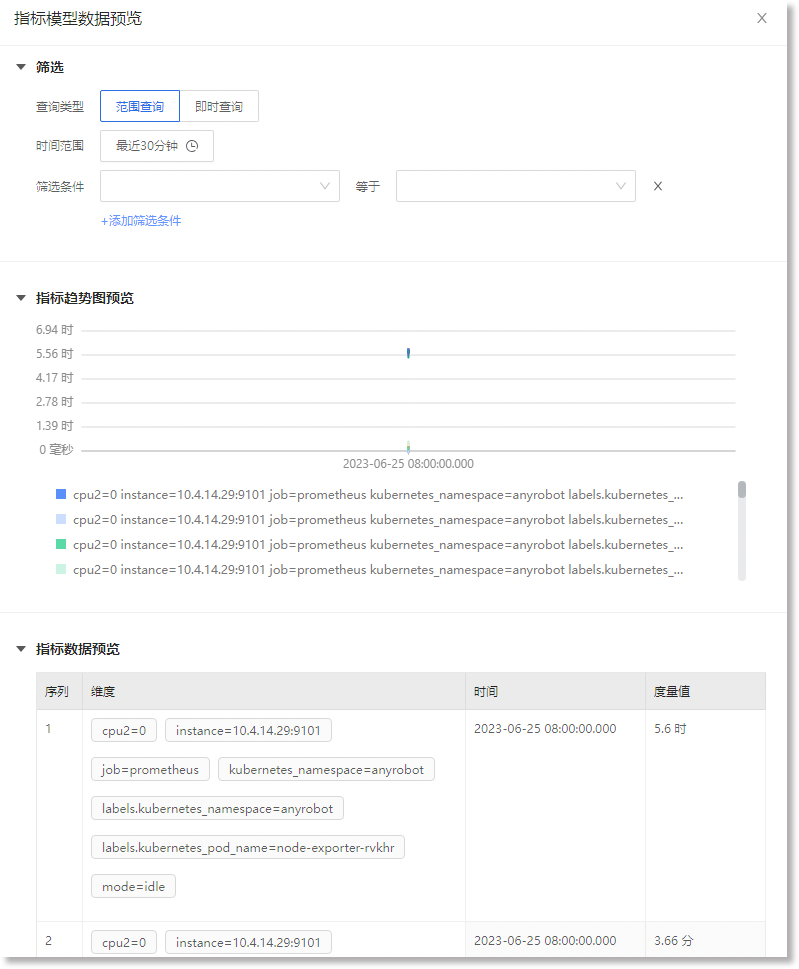
| 参数 | 参数说明 | |
| 筛选 | 查询类型 | 必选项。设置筛选的类型,可选项:范围查询、即时查询。 |
| 时间范围/时间 |
必选项。设置筛选的时间范围或时间点,具体如下: ・当查询类型选择“范围查询”时,需配置具体的“时间范围”,默认为“最近30分钟”。筛选成功生效后,预览抽屉下方的<指标趋势图>、<指标数据预览表>区域将只展示匹配此时间范围的数据预览结果。 ・当查询类型选择“即时查询”时,需配置具体的“时间”点,默认为当前日期及当前时刻。筛选成功生效后,预览抽屉下方的<指标数据预览表>区域将展示此时间点的数据预览结果。 提示:选择“即时查询”后,仅可查看指定时间点的<指标数据预览表>。 |
|
| 筛选条件 |
选填项。设置筛选的维度(lables字段值)及维度值,如设置的筛选维度为“cpu”、维度值为“1”,下方的<指标趋势图>、<指标数据预览表>区域将展示维度包含“cpu=1”的统计结果。点击“+添加筛选条件”可添加多个维度条件。 |
|
| 指标趋势图预览 | 指标趋势图 | 仅当选择【范围查询】时,可查看此趋势图。<指标趋势图>以时间为横轴,以度量值(度量值单位为系统自动转换的单位)为纵轴,展示了符合筛选条件的指标在指定时间范围内的趋势。通过预览指标趋势,您可根据实际指标需求及时调整指标模型的相关参数。 |
| 指标数据预览 | 指标数据预览表 |
<指标数据预览表>展示了指定时间周期/时间点内符合筛选条件的指标数据,具体如下: ・维度:即指标模型执行计算公式(即查询语句)后,在来源日志库中查询到的指标数据的lables字段值; ・时间:即指标模型执行计算公式(即查询语句)后,在来源日志库中查询到的指标数据的@timestamp字段值; ・度量值:即指标模型执行计算公式(即查询语句)后得到的计算结果。为便于展示且方便用户查看,在预览时,此度量值的单位为系统自动转换的单位。 |
说明:数据预览抽屉默认展示最近30分钟的数据,数据的默认步长会因指标模型已配置的查询语言及计算公式中的数据间隔(interval)值的不同而有所不同,具体如下:
1. 当指标模型的查询语言为“PromQL”,预览数据时默认步长为6min;
2. 当指标模型的查询语言为“DSL”:
-
-
- 若计算公式中配置的间隙(interval)值为常量,预览数据的默认步长为已配置的间隙(interval)值;
- 若计算公式中配置的间隙(interval)值为变量,预览数据的默认步长为6min。
-
提示:在时序数据中,“步长”指的是时间序列相邻数据点之间的时间间隔或间距,步长的设置对于时序数据的分析、建模非常重要,需要结合具体场景及数据特征进行设置,较小的步长可以提供更为详细和动态变化的数据,同时也会导致数据量激增从而提高对计算性能的要求。
进入指标模型配置页面,点击列表上方的【导入】按钮,在弹出的窗口中选中包含指标模型配置信息的文件,点击【打开】后即可批量导入并创建指标模型。
注意:
1. 仅支持导入json格式的文件;
2. 支持导入多个指标模型:导入时,若指标模型的数据视图名称不存在,则导入操作失败。您需在完成对应数据视图的创建后,再进行导入操作;若AnyRobot中存有重名的指标模型对象,则导入动作将会停止,导入操作失败;
3. 批量导入失败后,您可在审计日志中查看对应的“失败”记录。
在指标模型列表中勾选某一指标模型后,点击列表上方的【导出】按钮,可将已创建的指标模型以“.json”格式导出,可供其他场景快速应用,如下所示:

提示:支持导出多个指标模型。
指标模型创建成功后,您可以在AnyRobot其他数据模型模块和可视化分析模块引用此指标数据资源,进一步丰富数据基础,对模型定义的指标数据实现多维度、多场景的可视化指标分析、指标告警。详情请参见 指标模型应用 章节。