更新时间:2024-12-10 10:47:11
- 问题描述:Prometheus的pod不断重启pod状态为CrashLoopBackOff,且日志出现 “A lockfile from a previous execution already existed. It was replaced”报错信息。
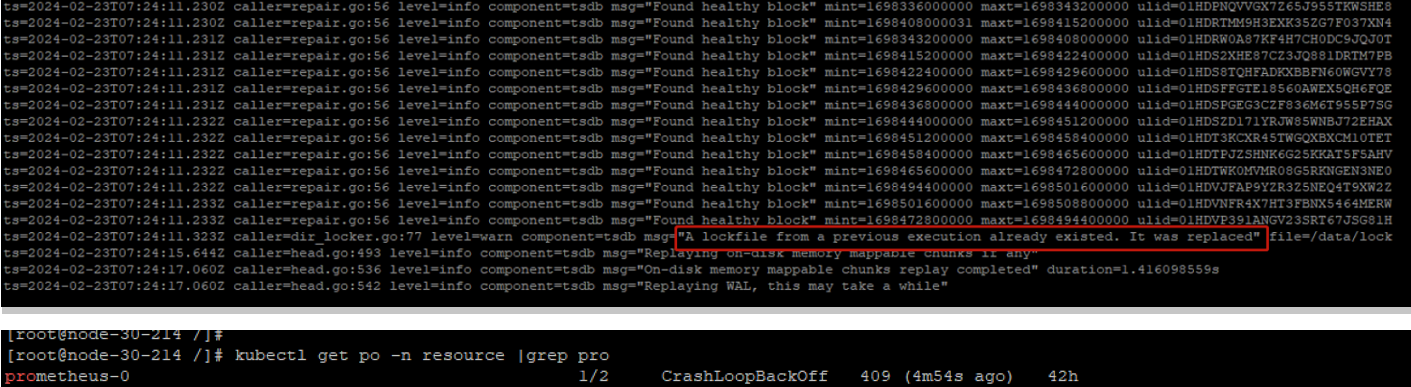
- 解决方法:进入Prometheus的数据目录(数据目录/mnt/prometheus为例,其它以实际环境部署目录为准),不需保留监控数据,可直接清空该数据目录,需要保留数据请联系管理员处理。
# 清空Prometheus数据目录 & 检查是否清空
rm -rf /mnt/prometheus/*
ls -al /mnt/Prometheus
# 重启prometheus & 检查重启是否成功
kubectl get pods -n resource | awk /prometheus/'{print $1}' | xargs kubectl -n resource delete pod
kubectl get pods -n resource | grep prometheus

< 上一篇:
下一篇: >