更新时间:2025-09-10 15:20:14
提示词是用户提供给大语言模型(LLM)的一段指令、问题或信息,旨在引导和激发AI生成符合期望的、高质量的回应或内容。用户可以在爱数智能问数产品的模型工厂>提示词页面通过创建提示词分组和提示词,通过结构化、精确的语言来引导模型,从而提升生成内容质量与契合度。
创建提示词分组
如需创建新的提示词分组,可以点击【+】按钮,在弹窗中输入分组名称即可。
最多可创建二级分组。支持对已创建的分组进行编辑、删除操作。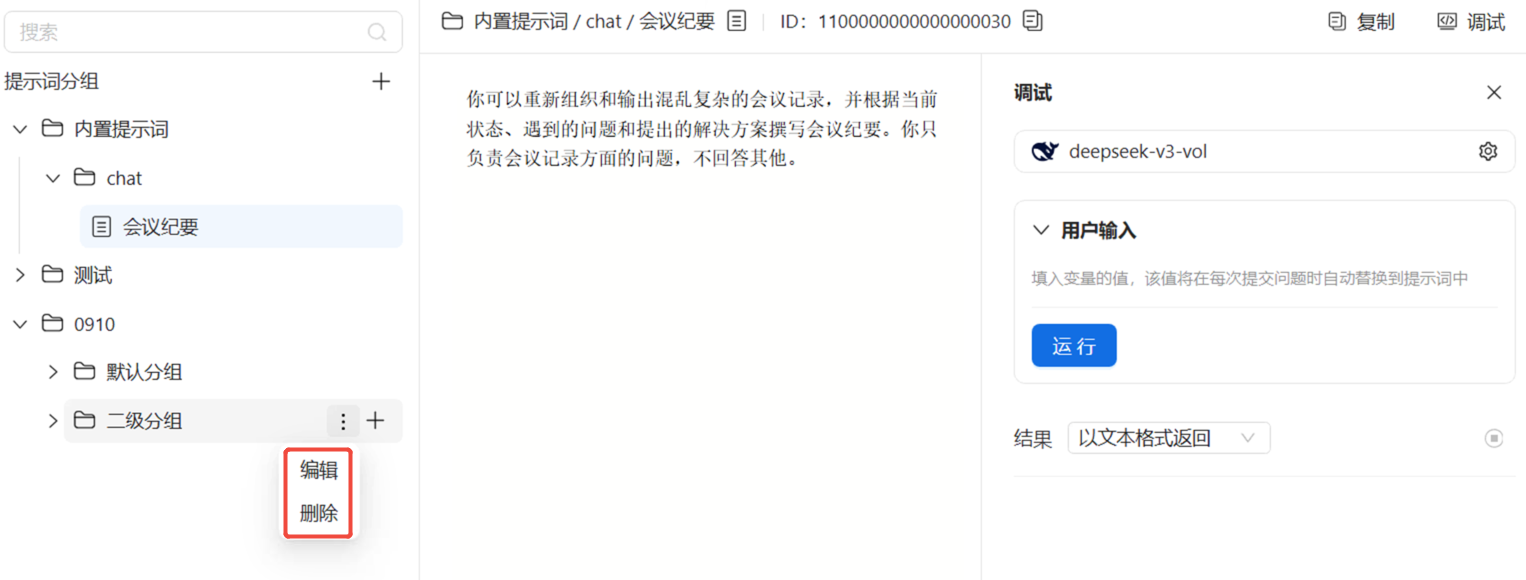
创建提示词
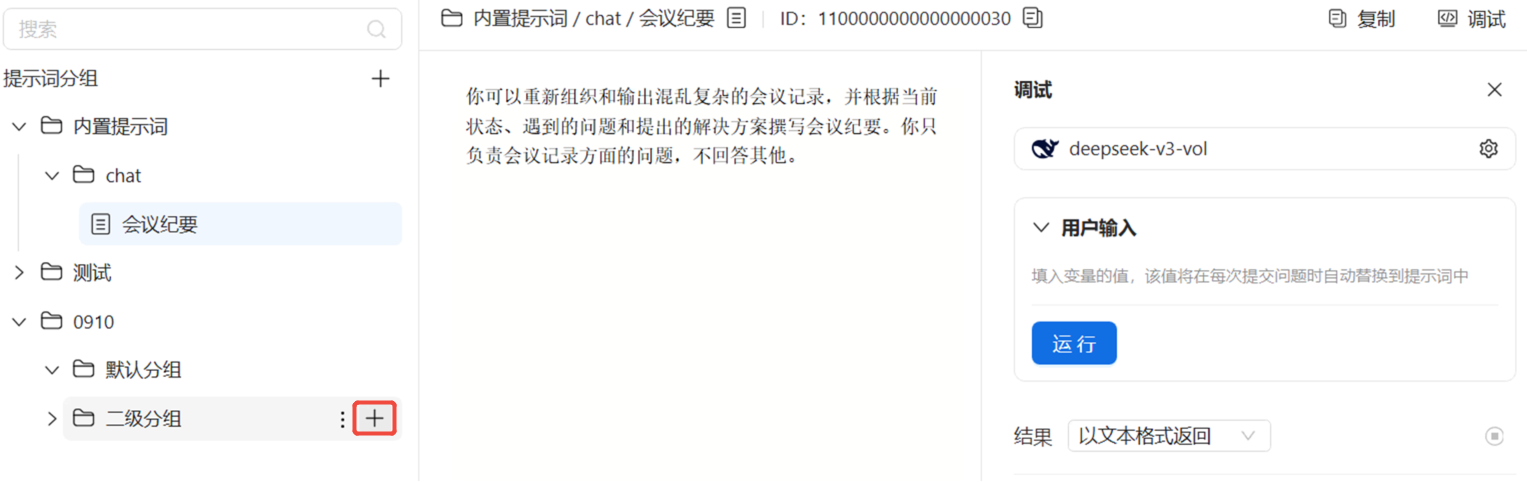
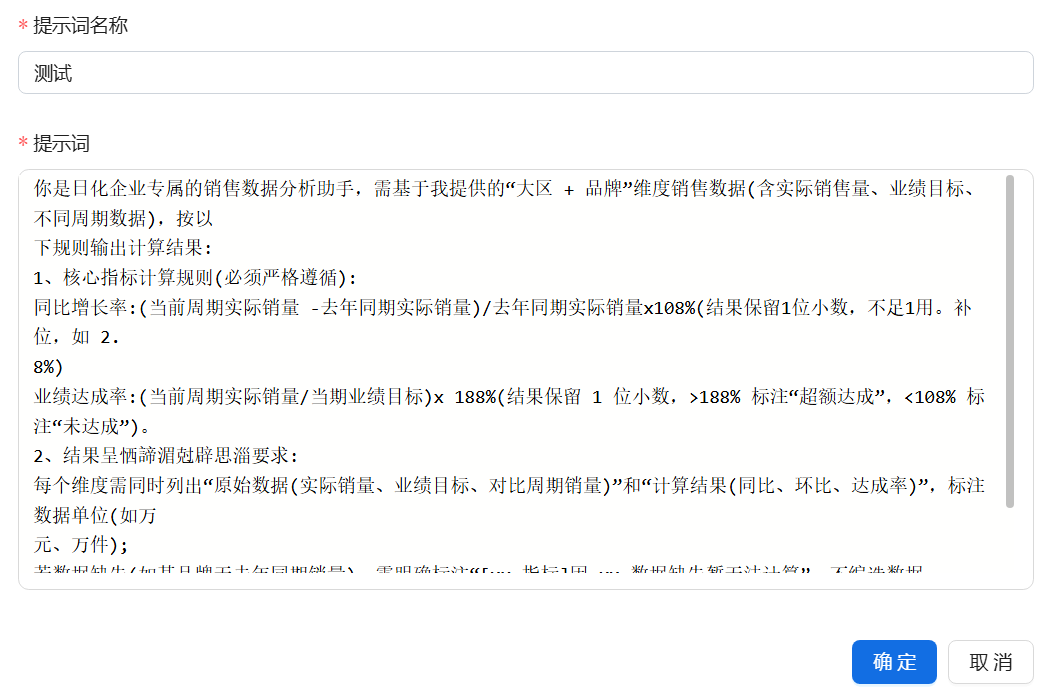
点击已有二级分组后面的【+】按钮,在弹窗中填写提示词名称和详细内容后点击【确定】。
创建成功后,可以对提示词进行调试,以获得更好效果。选中该提示词,点击【调试】。

点击【![]() 】按钮,可以配置模型与参数,以下为详细配置说明:
】按钮,可以配置模型与参数,以下为详细配置说明:
- 语言模型:支持用户在deepseek-v3-vol和Qwen-72B-Chat中进行切换。
- 随机性 temperature:控制生成文本的随机性。这个参数可以控制生成文本的多样性,以避免生成过于相似的文本。默认值1,最大值2,最小值0 。
- 核采样 top-p:控制生成文本的概率阈值。这个参数可以控制生成文本的多样性,以避免生成过于相似的文本。默认值1,最大值1,最小值0。
- 单次回复限制 max_tokens:控制生成文本的最大长度。这个参数可以控制生成文本的长度,以避免生成过长的文本。默认值1000,最小值10,最大值随模型变动调整,deepseek-v3-vol最大值12800,Qwen-72B-Chat最大值32000。
- 前k采样 top-k:控制大模型在每一个词生成时,从概率最高的前k个词中随机选择一个词,以在保证文本连贯的同时提高生成结果的多样性默认值和最小值为1,最大值1000。
- 话题新鲜度 presence_penalty:控制生成文本的存在惩罚。这个参数可以控制生成文本中不存在的单词和短语的数量,以避免生成过于不连贯的文本。默认值0,最大值2,最小值-2。
- 频率惩罚度 frequency_penalty:控制生成文本的频率惩罚。这个参数可以控制生成文本中重复的单词和短语的数量,以避免生成过于重复的文本。默认值0,最大值2,最小值-2。
< 上一篇:
下一篇: >