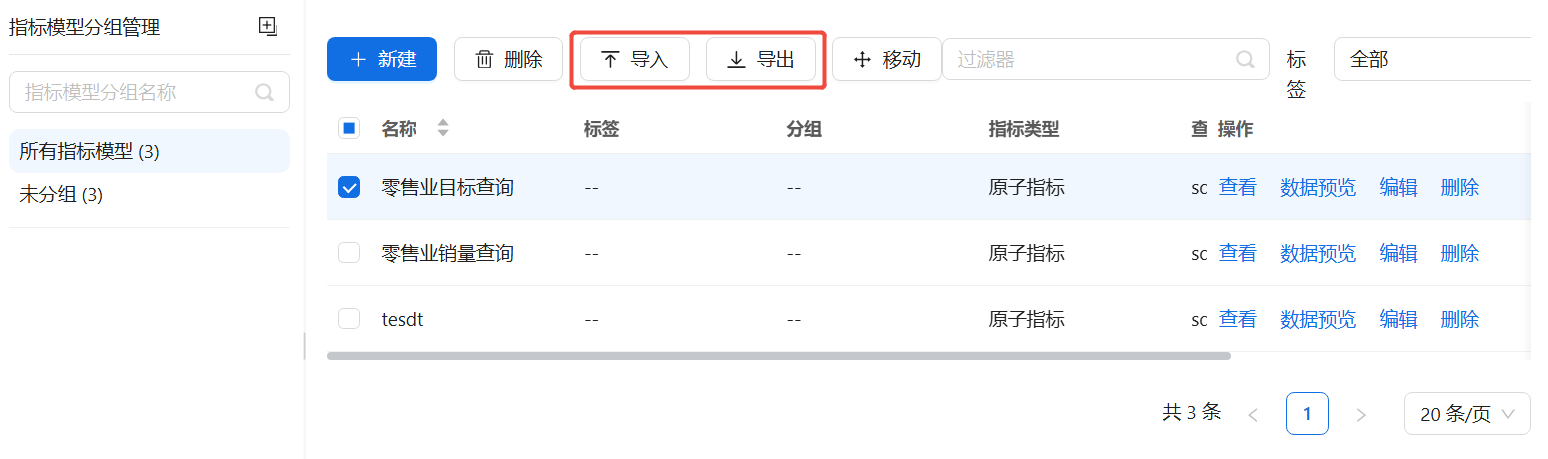
指标管理模块为用户提供统一的指标研、管、用一体化功能,帮助指标开发人员高效开发和管理指标。已创建的指标可以作为智能体的知识来源。
创建指标模型基本步骤
1. 在元数据管理>数据连接创建数据源,请参考如何创建数据连接
2. 在元数据管理>数据视图创建数据视图,请参考原子视图
3. 基于数据视图在元数据管理>数据模型>指标模型页面创建指标模型
_61.png) 说明:
说明:
- 衍生指标需要基于原子指标创建;
- 复合指标需要基于原子指标、衍生指标或其他复合指标创建。
新建指标模型
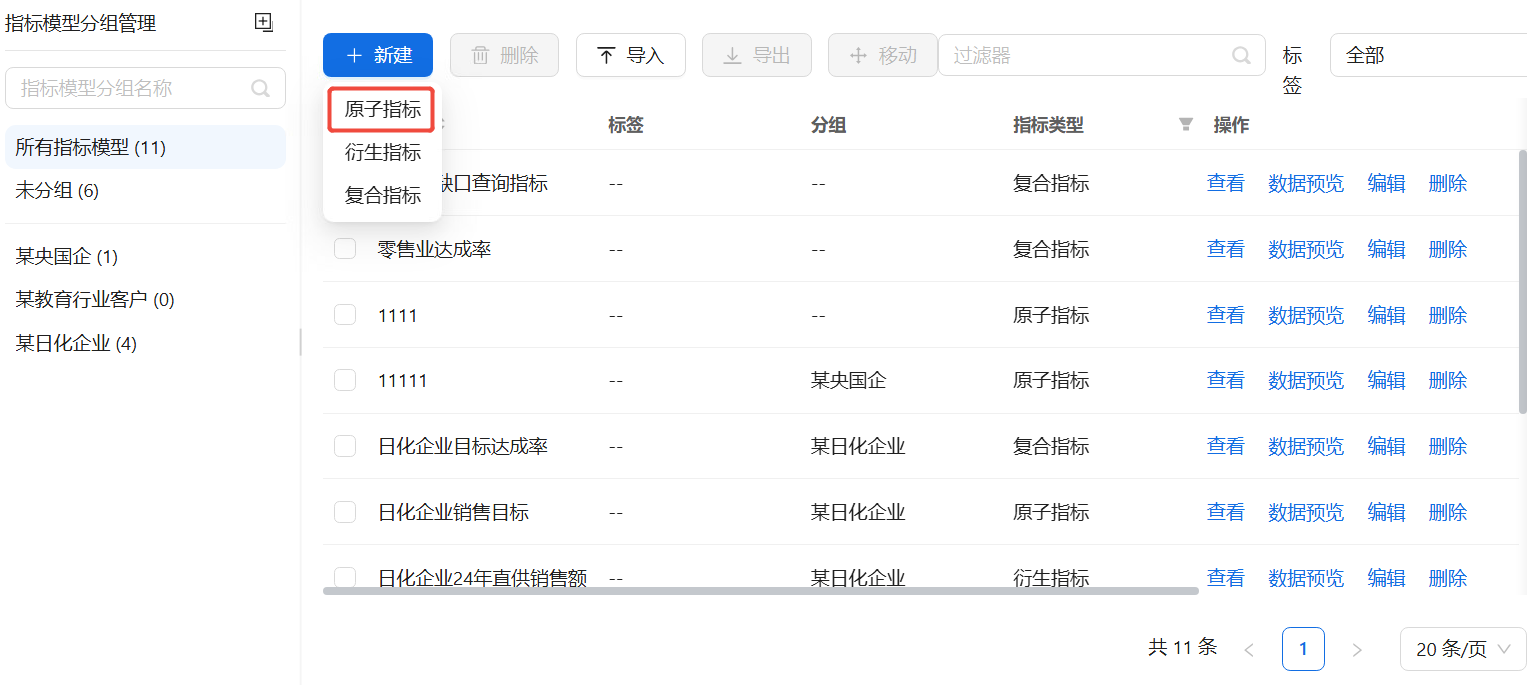
原子指标
原子指标由事实表中的度量字段生成,在指标管理页面点击【新建】,选择【原子指标】。
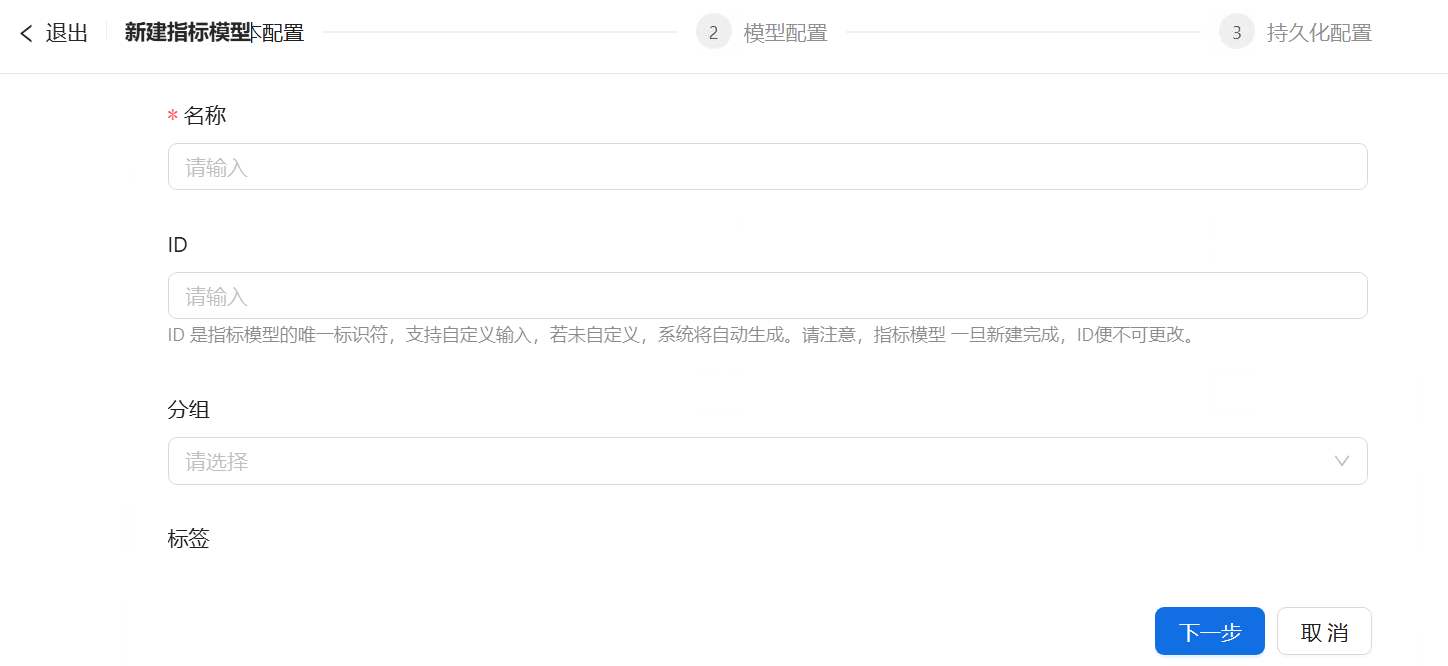
第1步 基本配置:输入指标名称,按需填写ID、分组、标签和备注信息,然后点击【下一步】。
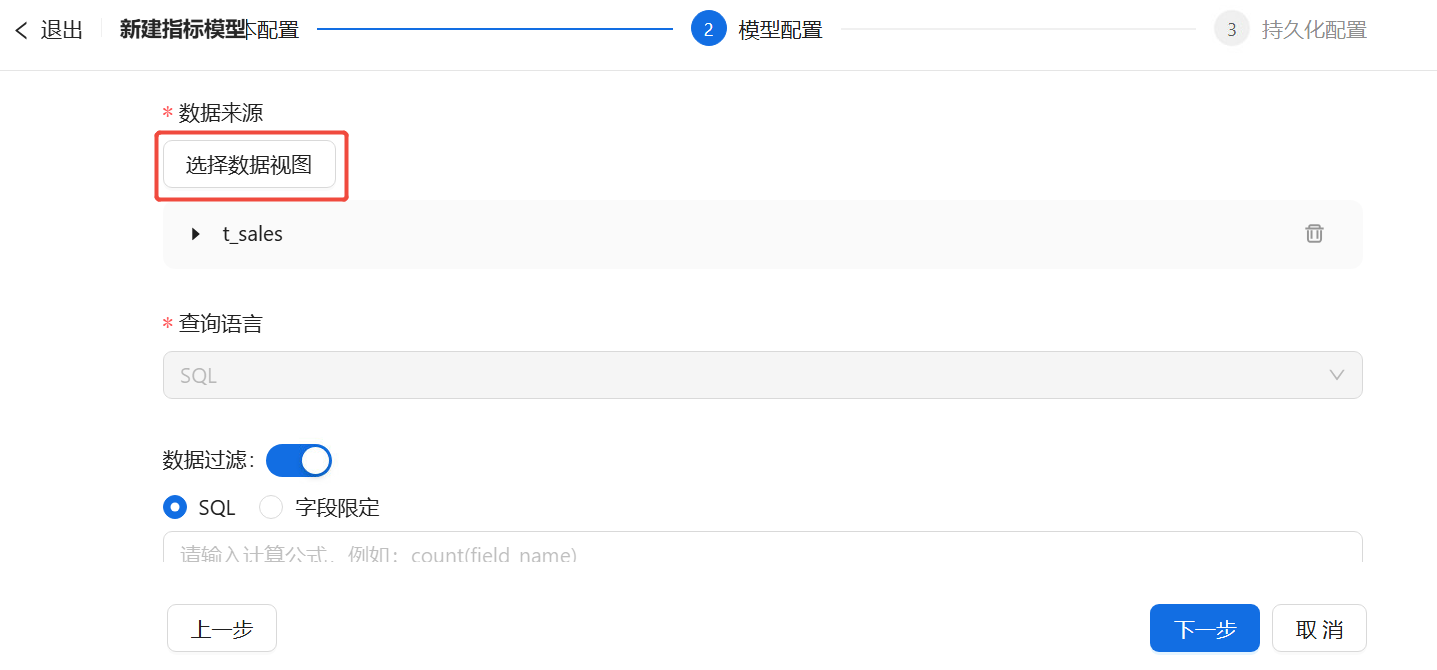
第2步 模型配置:首先选择指标的数据来源视图,选择完成后,才能进一步配置。根据指标类型的不同,需要配置的内容也有所差异。
◊ VEGA类视图:
- 数据过滤:打开开关后,可以在SQL计算公式或字段限定中选择一种过滤方式。若用户选择“SQL”配置方式,需要在编辑器中输入SQL语句;若选择“字段限定”配置方式,用户可根据需要增加数据过滤的条件,例如:当用户想要筛选出缴过费的数据时,可以新增过滤条件,字段名称选择表示缴费履行情况的字段,过滤条件为“等于”,限定内容为“已缴费”。
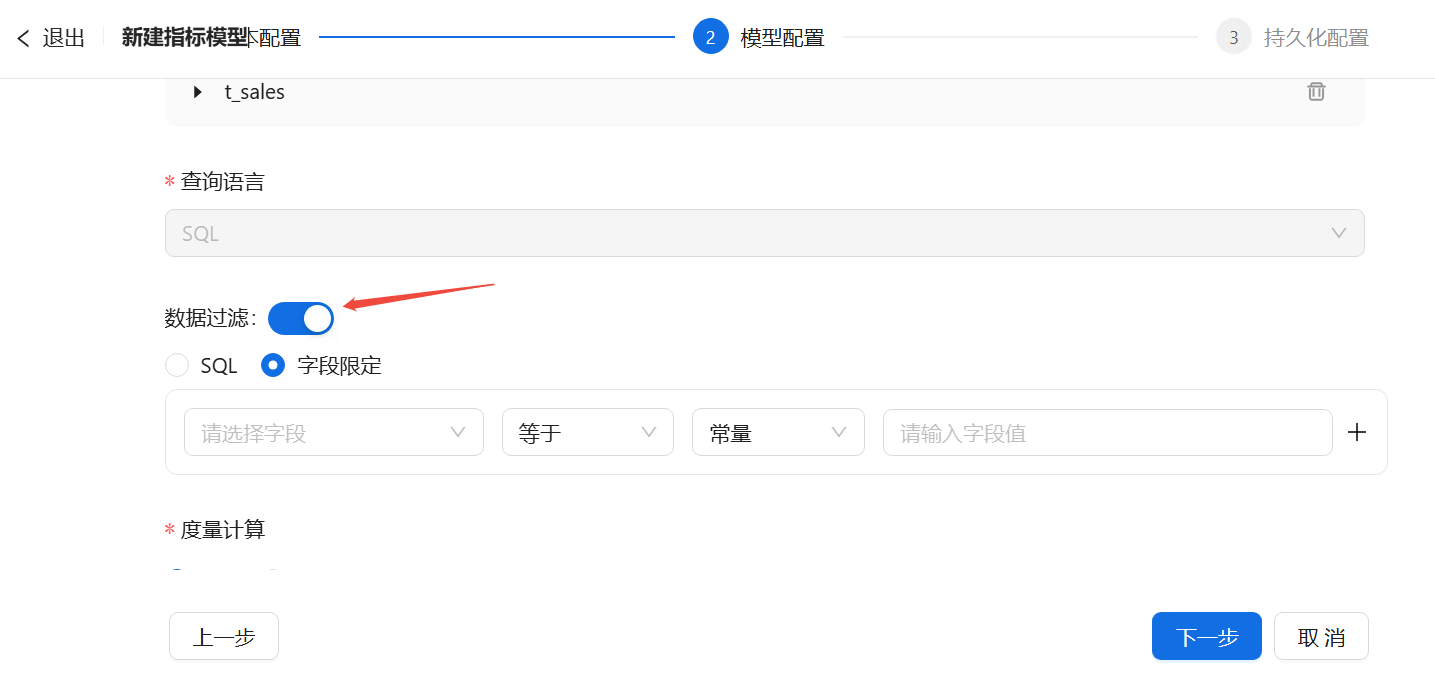
- *度量计算:在SQL计算公式或字段聚合中选择一种度量方式。若选择字段聚合配置方式,用户可根据可选字段的类型选择度量方式,例如:用户想要计算正常工时的总和,且该字段类型为数字型,则度量方式可以选择“求和”。
| 数据类型 | 支持的聚合函数 |
| 字符型 | 计数、去重计数 |
| 数字型 |
计数、去重计数、求和、最大值、最小值、平均值 |
| 日期型 | 计数、去重计数 |
| 日期时间型 | 计数 |
| 时间戳型 | 计数 |
| 布尔型 | 计数 |
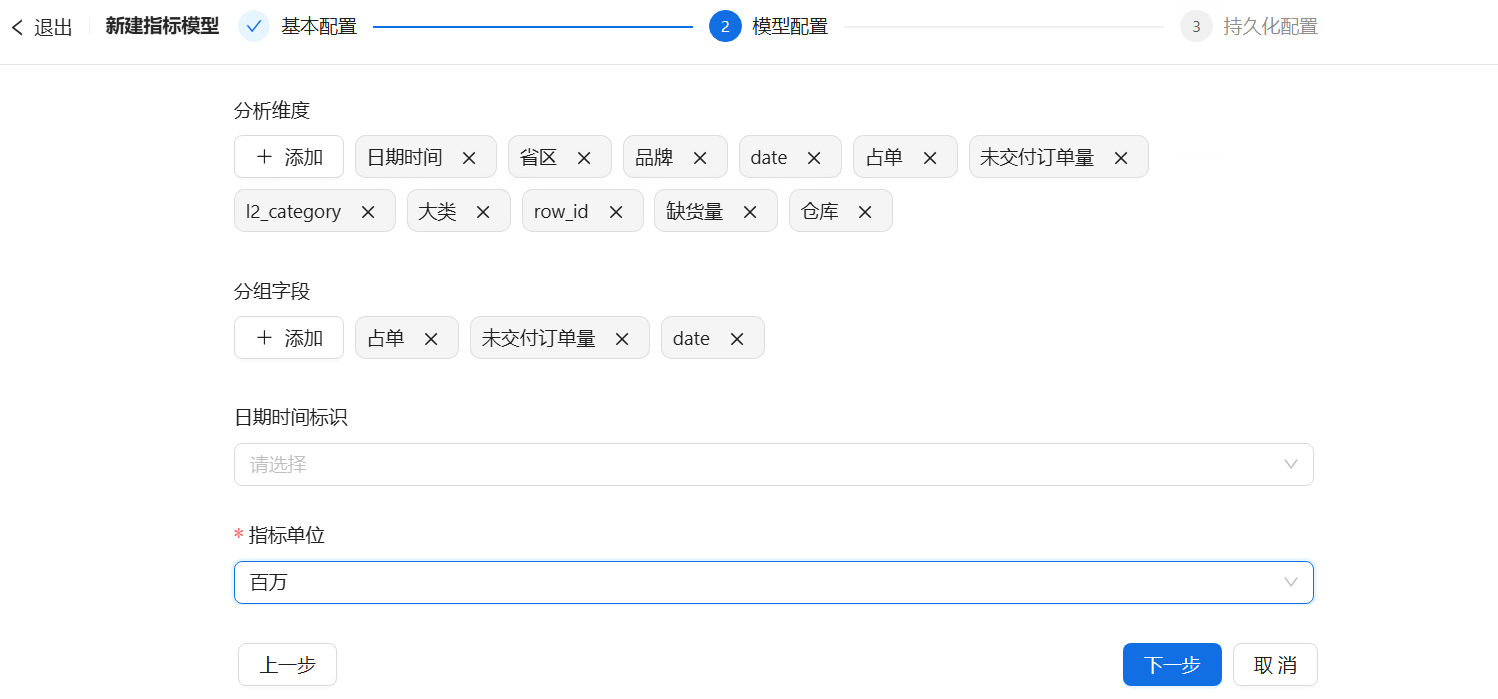
- 分析维度:除日期时间维度标签外,用户可自行添加或删除其他维度标签。
- 分组字段:可选视图内字段。
- 日期时间标识:可选所引用的视图中所有日期型、日期时间型、时间戳型的字段,若当前无可选字段,用户可以将当前引用的视图导入自定义视图中,通过SQL算子转换数据类型。
- *指标单位:根据指标性质选择合适的数值单位。
◊ 索引类视图:
- *查询语言:可选PromQL或DSL。
- *计算公式:根据上方已选择的查询语言,填写用于说明指标计算规则的对应查询语句。配置生效后,系统会根据此处定义的计算公式进行指标计算,得到对应指标数据。当*查询语言选择“DSL”时,配置框中默认提供了计算公式(DSL语句)的预输入结构,指标模型通过此处配置的DSL语句实现对指定数据集的聚合查询操作,进而获取所需的指标数据(即返回的查询结果)。
具体配置时:
-若您所需的指标数据能够基于此预输入计算公式结构实现,您可以查阅下方› 预输入计算公式(DSL语句)配置说明,并结合实际需求修改少量参数,应用此预输入结构,快速配置所需计算公式;
-若您所需的指标数据需要基于其他聚合方式实现,您可以参考下方› 计算公式(DSL语句)基本规范说明,遵循不同聚合方式的合法格式,配置所需计算公式。
注意:此处配置的计算公式中,必须包含一层date_histogram(日期直方图)聚合和一层value_count(计数)聚合。
配置框中提供的预输入DSL语句为嵌套的聚合结构,包括过滤查询部分、嵌套的三层聚合查询部分。基于此结构的计算公式,其查询结果将返回一个多层嵌套的数据结构,此结果包含了按照指定字段值进行分组(terms聚合)后,在每个分组内再按照时间间隔分组后(date_histogram聚合)的统计值(value_count聚合)信息,如下所示:
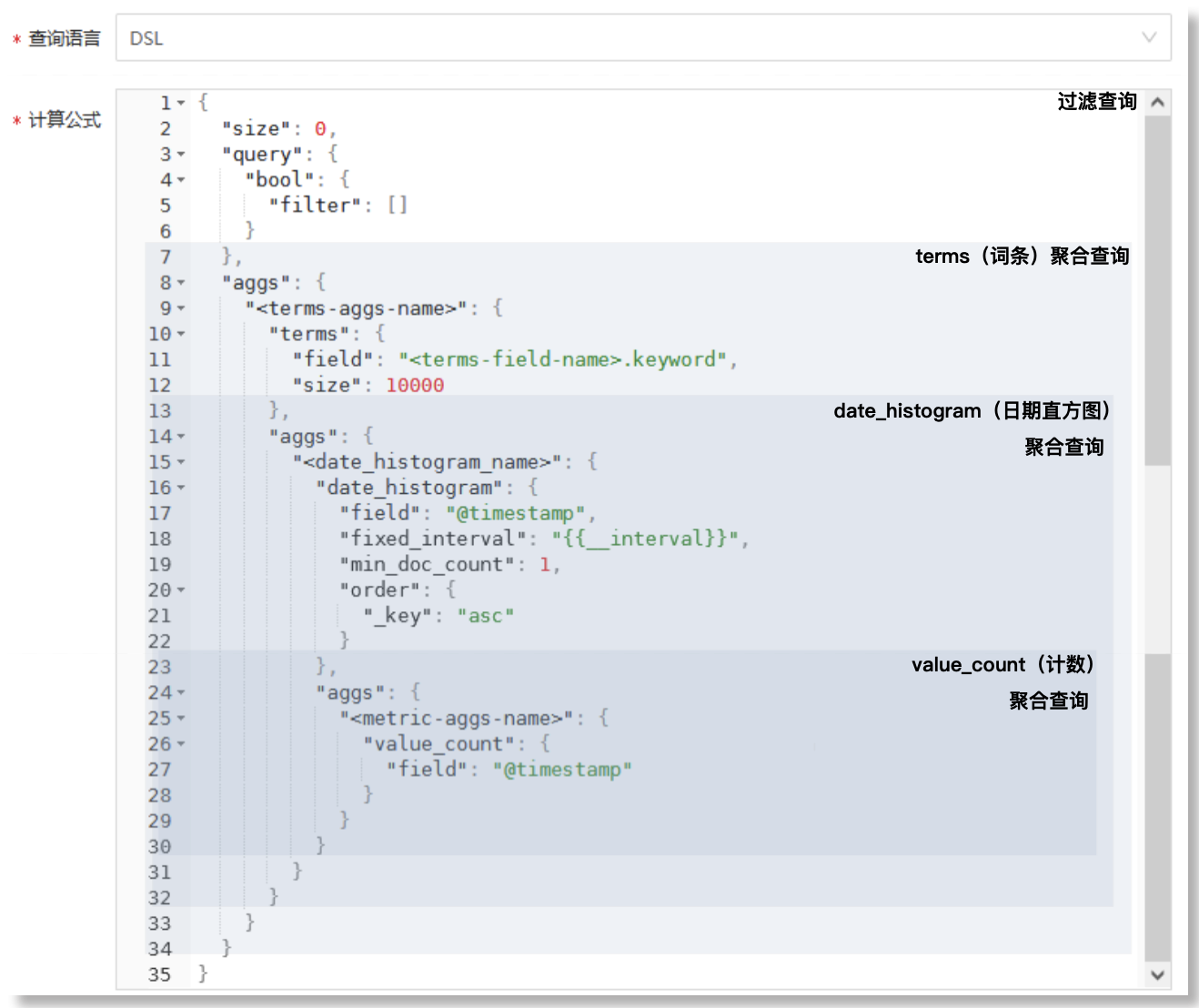
关于嵌套的三层聚合查询,每层聚合的查询结果说明如下:
-
-
- 最外层terms聚合:按照指定字段的值对来源数据进行分组
- 第二层的date_histogram聚合:在每个terms分组内,按照指定时间字段对数据进行分组
- 第三层的value_count聚合:统计每个时间段内文件数量(事件发生次数或数据记录数量)
-
若您所需的指标数据能够基于此预输入计算公式结构实现,您可以参照下方的简要配置提示,或查看下方的详细配置说明,配置所需计算公式。
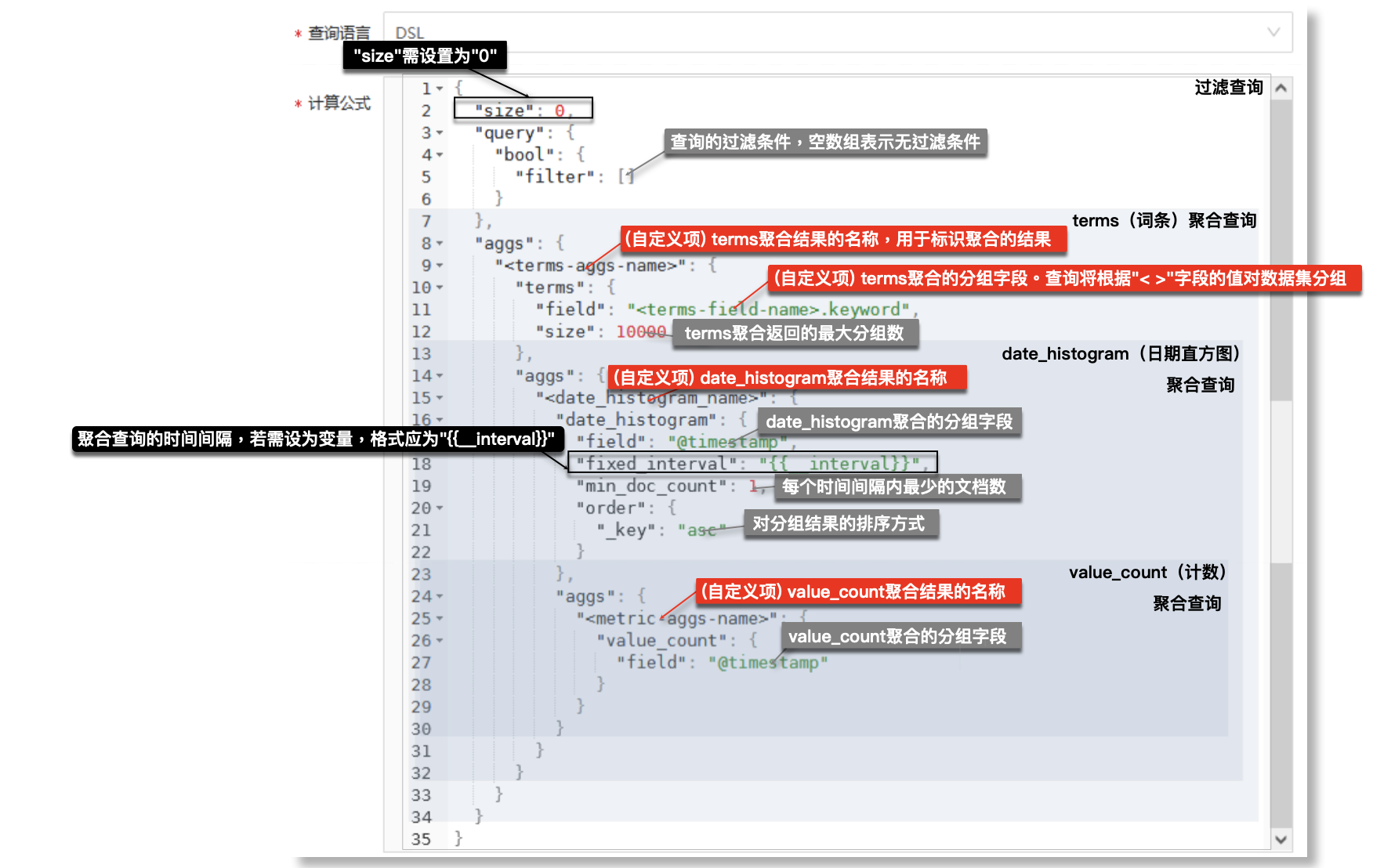
» 下图为预输入计算公式(DSL语句)的简要配置说明。配置时,请参考下方说明,并结合实际需求进行:
-计算公式中尖括号"<>"标识的项(红框标识)为用户自定义配置项,您需要根据实际情况直接替换修改此参数;
-系统为计算公式中的某些项(灰框标识)提供了默认参数,您可以直接应用此类参数,也可以根据实际需求修改;
-系统对计算公式中的某些项(黑框标识)有强限制配置要求,具体限制请查看下图:
» 若需要了解此预输入计算公式结构及配置限制的详细说明,请具体参考下文。配置框中提供的预输入DSL语句为嵌套的聚合结构,包括过滤查询部分、聚合查询部分。
• 过滤查询部分
| 键 | 含义 |
size |
size需设置为0。表示查询结果只返回聚合结果,不返回文档数据。 |
query |
表示这是一个查询操作。 |
bool |
布尔查询部分 |
filter |
查询的过滤条件。此处filter为空数组,表示此查询没有筛选条件,即查询时会匹配所有文档。可根据实际需求自行定义查询必要的匹配条件,以筛选指定数据,书写格式可参见OpenSearch官网文档>Filter context的相关内容。 |
• 聚合查询部分
“aggs”部分具体定义了需执行的聚合查询操作,包括三层嵌套的聚合:terms(词条)聚合、date_histogram(日期直方图)聚合、value_count(计数)聚合。terms聚合将按照<terms-field-name>.keyword字段的值对所选数据集分组。每个分组内再执行date_histogram聚合,具体按照@timestamp字段的值进行时间分组,时间分组的具体时间间隔由{{__interval}}的具体参数决定。最后,每个时间间隔内再进行value_count值聚合,用于统计每个间隔内@timestamp字段值对应的文档数量,查询指标数据。此默认嵌套聚合结构,可用于实现根据指定时间间隔(按天/周/月)对指定对象类别下某一指标的统计分析,帮助进行时间趋势相关的数据分析及可视化。
提示:您可根据实际指标需求自行定义所需的聚合方式,详情请参见支持的聚合方式。
三层嵌套聚合的详细说明如下:
| 键 | 含义 |
aggs |
聚合查询部分 |
<terms-aggs-name> |
terms(词条)聚合结果的名称,用于标识此聚合的结果,您可根据实际需求自定义命名。 |
terms |
terms(词条)聚合部分。分桶聚合类型,用于根据指定字段的值对数据进行分组,并统计每个不同值对应的文档数量或计算其他度量指标。 |
field |
terms(词条)聚合的分组字段。此处field:<terms-field-name>.keyword表示聚合将根据<terms-field-name>.keyword字段值对数据集进行分组,您可根据实际需求定义分组字段,书写格式可参见OpenSearch官网文档>AGGREGATIONS>Terms aggregations的相关内容。 |
size |
terms(词条)聚合返回的分组数量。此处size:10000表示最多返回10000个不同值对应的分组。
提示: |
| 键 | 含义 |
aggs |
嵌套的date_histogram聚合查询部分。表示将在terms聚合的每个分组中进行的date_histogram聚合。 |
<date-histogram-name> |
date_histogram(日期直方图)聚合结果的名称,用于标识聚合操作的结果,您可根据需求自定义命名。 |
date_histogram |
date_histogram(日期直方图)聚合部分。分桶聚合类型,用于根据指定日期字段的值对数据进行分组,并统计指定的时间间隔内的文档数量或计算其他度量指标。 |
field |
date_histogram(日期直方图)聚合的分组字段。您可根据实际需求自定义分组所需的日期字段,书写格式可参见OpenSearch官网文档>AGGREGATIONS>Date histogram aggregation 的相关内容。 |
fixed_interval |
date_histogram分桶聚合下,支持使用fixed_interval(固定时间间隔)以及calendar_interval(日历感知时间间隔)定义时间分桶的间隔。
指标模型中,date_histogram聚合方式中 若设置为变量,格式应配置为 若设置为常量,表示此值不可修改,查询时无论查询范围是多少,分桶的时间间隔都不变。 |
calendar_interval |
• 当选择按照日历感知时间间隔进行分桶时,不支持配置为变量,当前支持的日历间隔如下:
• 当选择按照日历感知时间间隔进行分桶时,可指定时区(默认为
|
min_doc_count |
时间间隔内最少文档数。如:"min_doc_count":1 表示若某个时间间隔内文档数<1,则该时间间隔不会被包含在聚合结果中。 |
order |
表示将对分组结果进行排序。 |
_key |
分组结果的具体排序方式。如 |
| 键 | 含义 |
aggs |
嵌套的value_count(计数)聚合部分。 |
<metric-aggs-name> |
value_count(计数)聚合结果的名称,用于标识聚合操作的结果,您可根据需求自定义命名。 |
value_count |
value_count(计数)聚合部分。值聚合类型,用于统计指定字段中非空值的数量。 |
field |
value_count(计数)聚合需要统计的字段。如"field": "@timestamp"表示要统计的字段是@timestamp。 |
上文仅对预输入框架中示意的聚合方式进行了配置说明,若实际场景中需要使用其他聚合方式,请参考OpenSearch官网文档>Aggregations章节中对应聚合方式的示例结构书写。DSL计算公式的书写需遵循DSL语句的基本语法结构(具体请参见OpenSearch官网文档)及以下特有约束。
• 聚合方式及聚合层数约束
• 当前不支持并行聚合(Multiple aggregation)查询;
1)分桶聚合:date_histogram(日期直方图)、terms(词条)、filters(过滤)、range(范围)、date_range(日期范围);
2)值聚合:value_count(计数)、cardinality(去重计数)、sum(求和)、avg(均值)、max(最大值)、min(最小值)、top_hits(桶内排序取 Top N)。
• 支持配置的分桶聚合层数需≤7,值聚合层数需=1,各层聚合的聚合名称不能重复。
• 子聚合约束
• date_histogram(日期直方图)
• 计算公式中必须包含date_histogram,且只能有一个;
• date_histogram 分桶聚合下的子聚合类型需为值聚合。
• top_hits(桶内排序取 Top N)
• top_hits 需满足如下结构:
"size": <number>,"sort": [ { "<sort_field_name>": { "order": "desc | asc" } }],"_source": { "includes": [ "<field_name1>", "<field_name2>", ...... ]}
校验说明:
1. 完成指标模型的配置后,点击【数据预览】/【保存】按钮,系统将对计算公式(PromQL语句/DSL语句)的合法性进行校验,校验通过后,方可预览指标数据/成功创建指标模型;
2. 当前暂不支持对查询语句中字段的权限进行校验,若查询了数据视图中不存在的字段,数据查询结果则为空。
- 度量字段:仅当查询语言选择“DSL”时,此项可配置且为必填项,配置说明如下:
- 当计算公式中的值聚合方式为top_hits时,此处配置的度量字段应为top_hits中_source所包含的字段名称,且此字段名称对应的字段类型应为数值字段,不兼容日期。
- 当计算公式中的值聚合方式为其他类型时,此处配置的度量字段应为公式中的值聚合名称,若配置的度量字段与值聚合名称不匹配,系统将会报错。
- *指标单位:根据指标性质选择合适的数值单位。
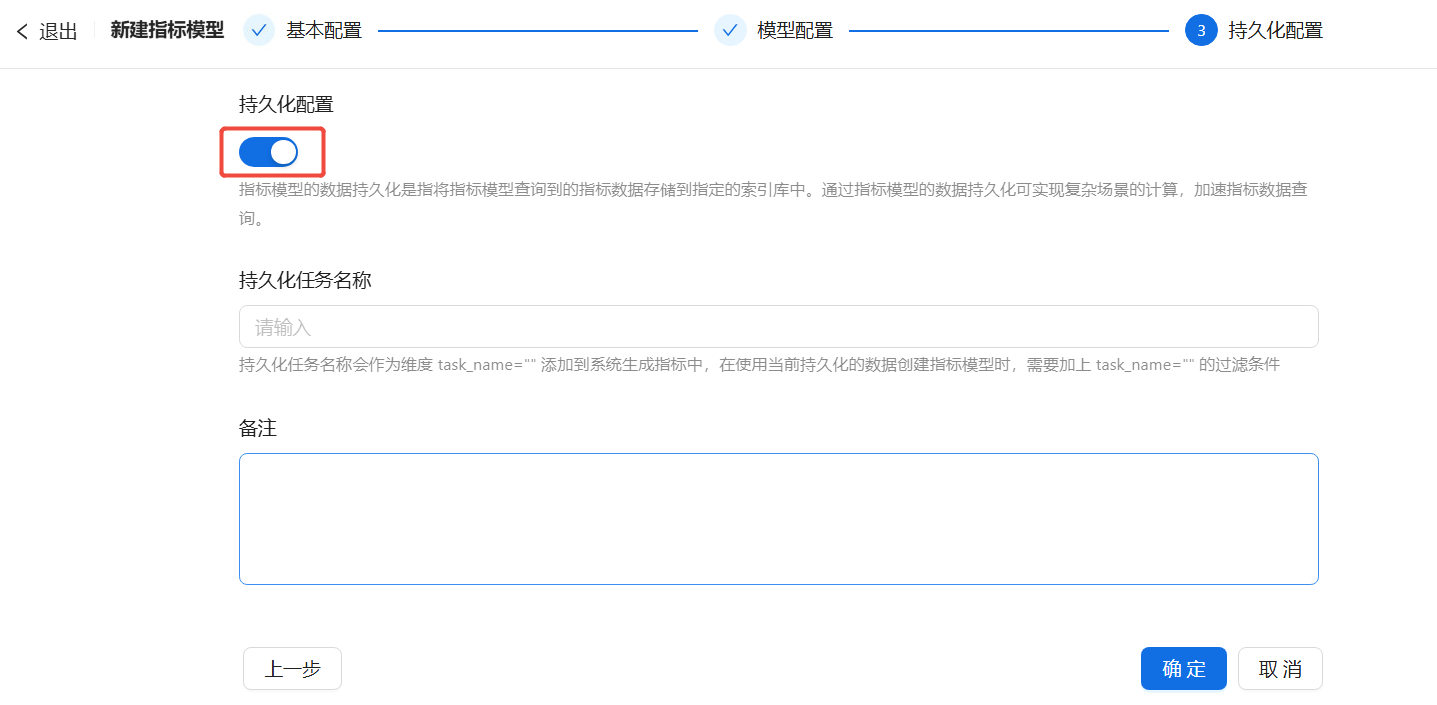
第3步 持久化配置:若开启开关,可以将指标模型查询到的指标数据存储到指定的索引库中,通过指标模型的数据持久化可实现复杂场景的计算,加快指标数据查询的速度。用户可根据页面提示进行配置。
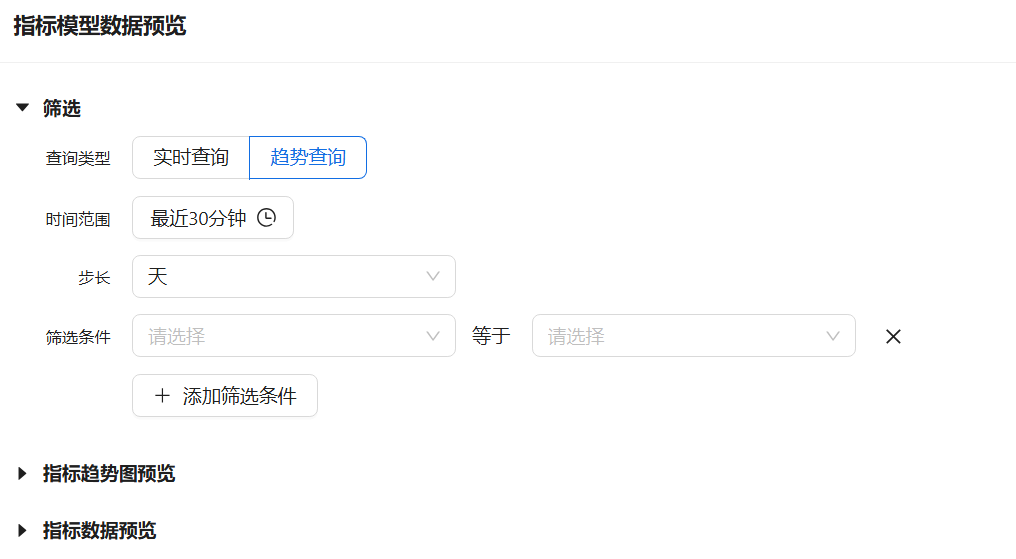
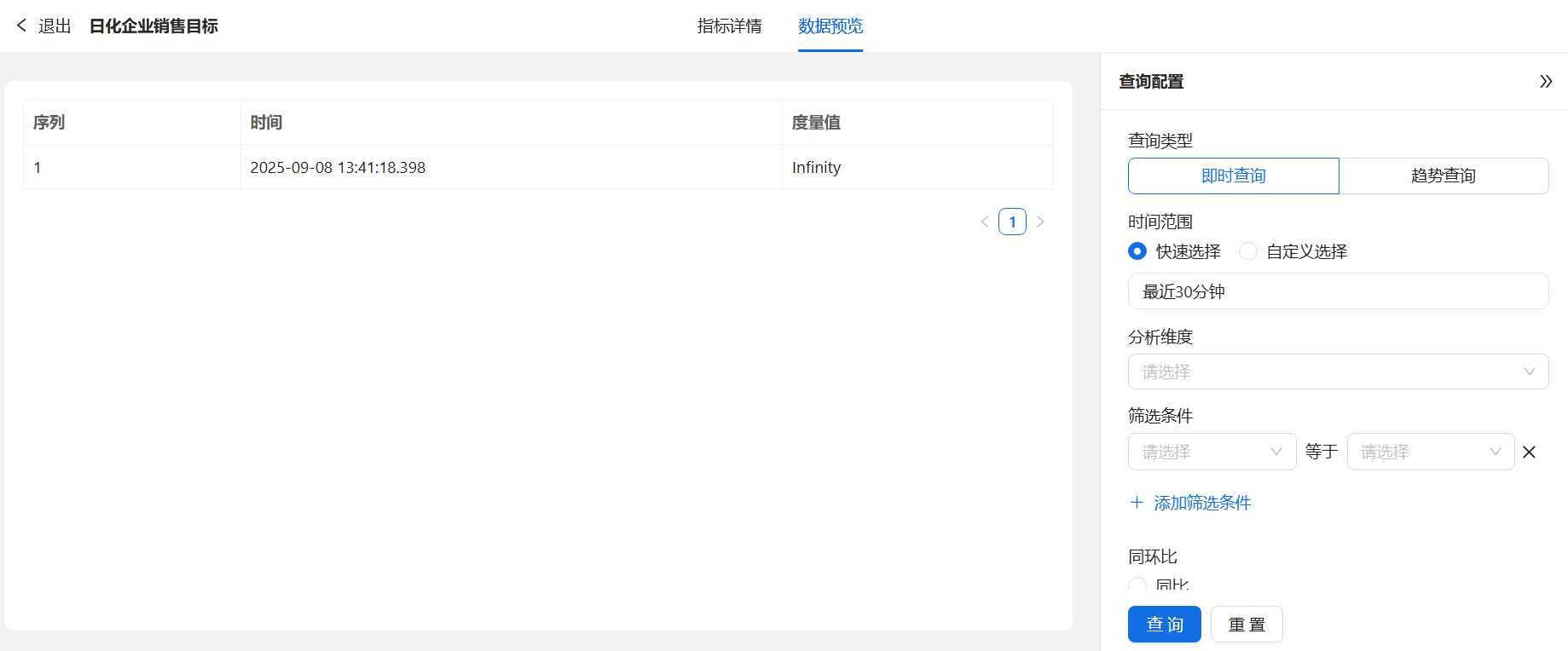
第4步 配置完成后点击【确定】。用户可以点击已创建的指标操作栏【数据预览】,通过筛选条件查看数据趋势。
衍生指标
衍生指标必须根据已创建的原子指标进行配置,点击【新建】,选择衍生指标。
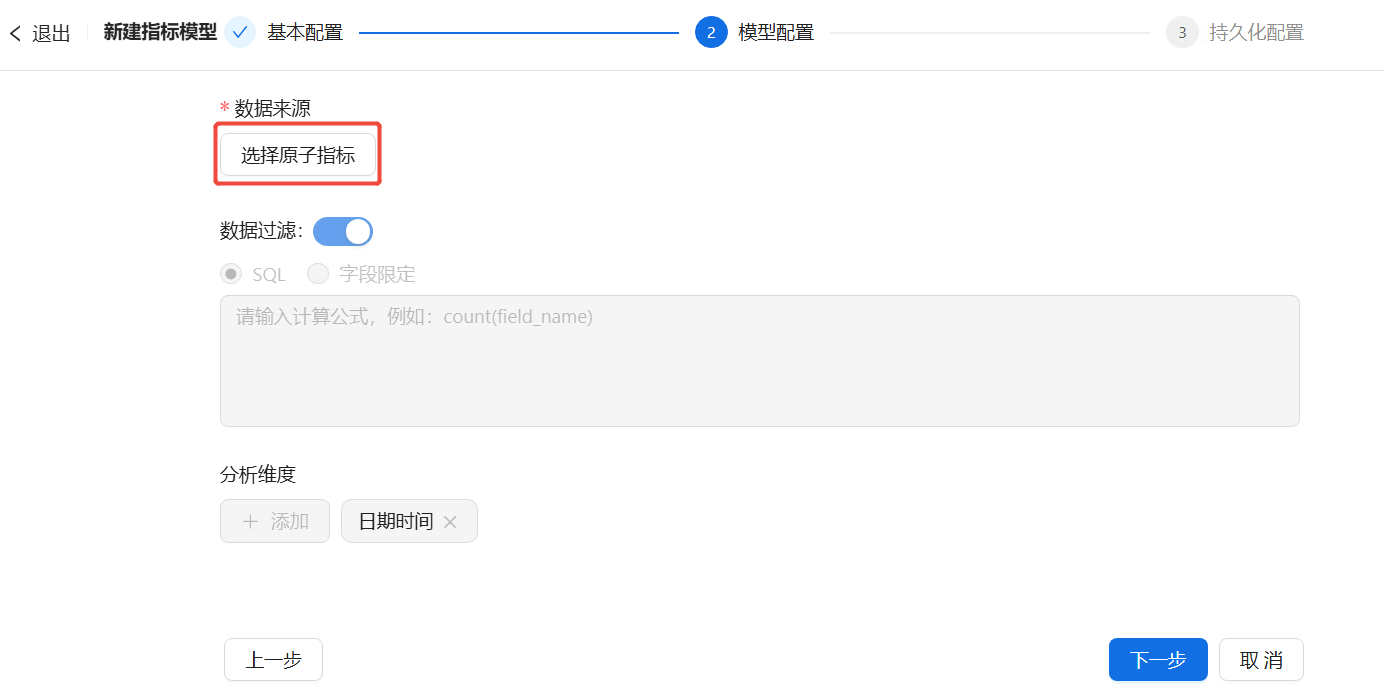
第1步 基本配置:输入指标名称,按需填写ID、分组、标签和备注信息,然后点击【下一步】。
第2步 数据来源:首先选择该衍生指标基于哪个原子指标创建,选择完成后,才能进一步配置。
- 数据过滤:打开开关后,可以在SQL计算公式或字段限定中选择一种过滤方式。若用户选择SQL配置方式,需要在右侧编辑器中输入SQL语句;若选择字段限定配置方式,用户可根据需要增加时间限定和业务限定条件,例如:当用户想要查看华东片区过去一季度的销量数据时,可以进行如下图所示的设置。
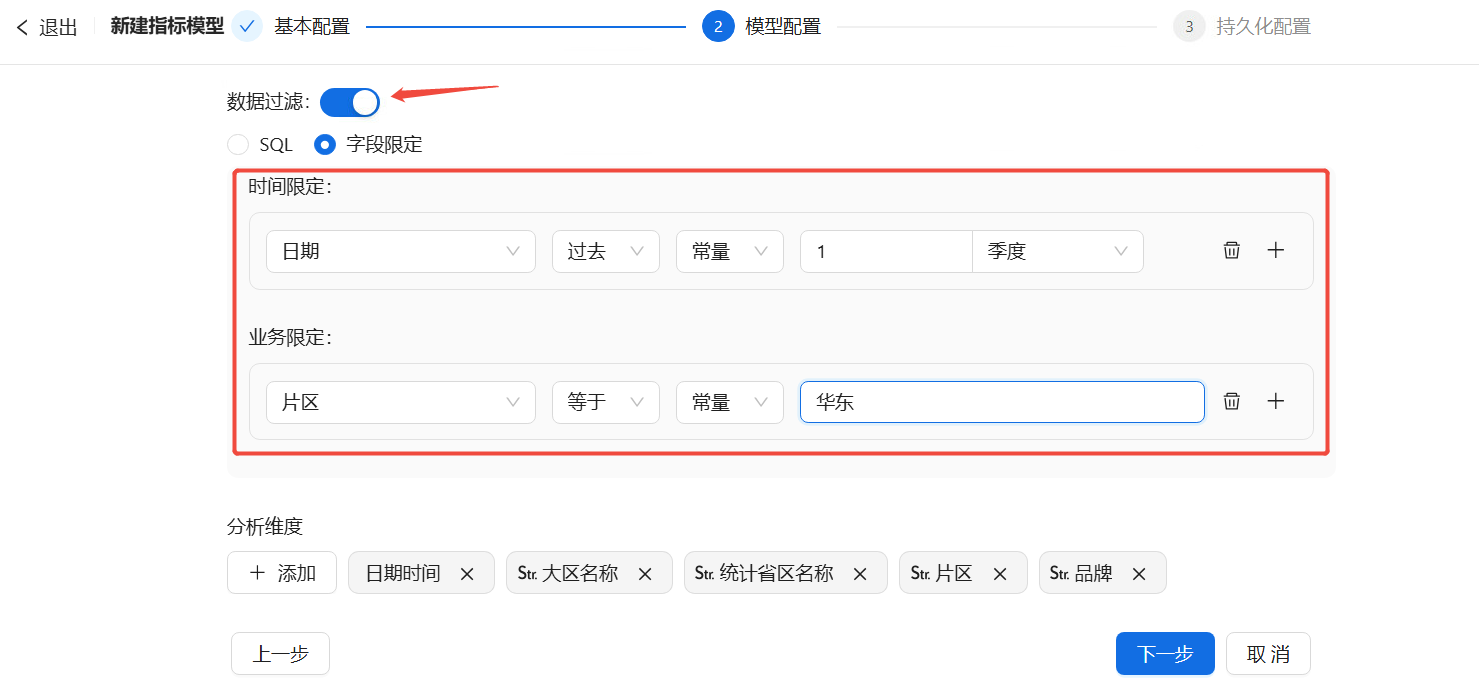
- 分析维度:继承原子指标的分析维度,用户可自行添加或删除其他维度标签。
- 指标单位:根据指标性质选择合适的数值单位。
第3步 衍生指标不支持持久化配置,其他配置项完成后点击【确定】。
第4步 配置完成后点击【确定】。用户可以点击已创建的指标操作栏【数据预览】,通过筛选条件查看数据趋势。
复合指标
复合指标必须根据已创建的其他指标进行配置,点击【新建】,选择衍生指标。
第1步 基本配置:输入指标名称,按需填写ID、分组、标签和备注信息,然后点击【下一步】。
第2步 模型配置:可以点击左侧原子指标、衍生指标及复合指标,将其引用至表达式中,被引用的指标将以标签的形式置入右侧的表达式编辑器中。

- 数据过滤:打开开关后,可以在SQL计算公式或字段限定中选择一种过滤方式。若用户选择SQL配置方式,需要在右侧编辑器中输入SQL语句;若选择字段限定配置方式,用户可根据需要增加时间限定和业务限定条件,例如:当用户想要查看华东片区过去一季度的销量数据时,可以进行如下图所示的设置。
- 分析维度:继承原子指标的分析维度,用户可自行添加或删除其他维度标签。
- 指标单位:根据指标性质选择合适的数值单位。
第3步 复合指标不支持持久化配置,其他配置项完成后点击【确定】。
第4步 配置完成后点击【确定】。用户可以点击已创建的指标操作栏【数据预览】,通过筛选条件查看数据趋势。
导入导出指标模型
支持导入json格式的指标,同时也可以导出已创建的指标模型。