数据源介绍
平台支持统一数据源管理,是构建「多源数据整合」核心优势的基础功能,支持接入多种不同类型数据源(如:结构化数据、非结构数据等),通过数据处理引擎层,支持多源数据整合,能够从不同系统和渠道中提取数据,并通过智能化的方式将其融合,确保决策依据的全面性和准确性。
目前平台支持采集的数据连接类型包括:
- 结构化数据:
- MySQL
- MariaDB
- Oracle
- PostgreSQL
- SQLServer
- Apache Doris
- Hologres
- openGauss
- Dameng
- GaussDB
- MongoDB
- Apache Hive
- ClickHouse
- TDH Inceptor
- MaxCompute
- 非结构化数据
-
- Excel
- AnyShare 7.0
- 其他:
- 听云
- OpenSearch
数据连接创建
第1步:进入VEGA虚拟化 > 数据连接管理配置页面,点击【+新建数据连接管理】,进入“数据源新建”的配置流程,如下所示:

第2步:选择需要采集的数据源类型,点击下一步。 即可进入具体采集场景的配置。

第3步:配置信息填写完成后,返回数据连接管理页面,选中新建的数据连接,点击![]() ,选择测试连接,连接成功即可完成数据连接的创建。在此管理页面,也可进行数据连接的查看、新建元数据、编辑、测试连接、删除、搜索等操作。
,选择测试连接,连接成功即可完成数据连接的创建。在此管理页面,也可进行数据连接的查看、新建元数据、编辑、测试连接、删除、搜索等操作。


数据连接创建典型场景
结构化数据-MySQL数据源创建
创建基本步骤可参考以上文档内容。创建SQL-MySQL数据源-服务管理系统的具体配置信息示例如下:
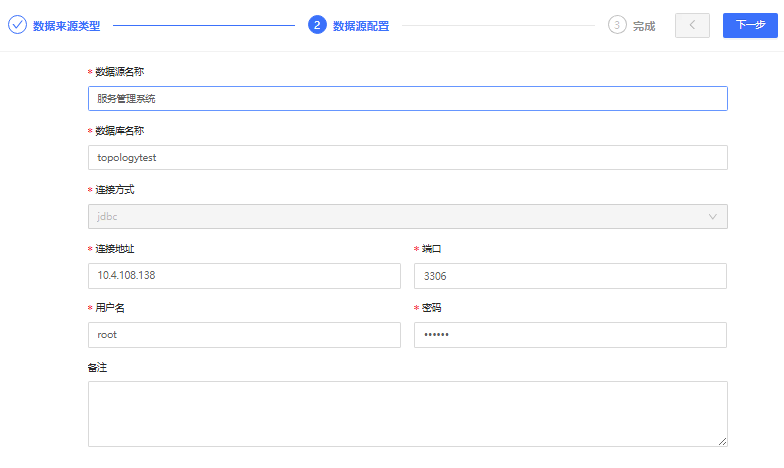
备注:连接方式默认为JDBC
结构化数据-MongoDB数据源创建
单节点部署
创建基本步骤可参考以上文档内容。创建NoSQL-MongoDB数据源-人力资源数据库的具体配置信息示例如下:
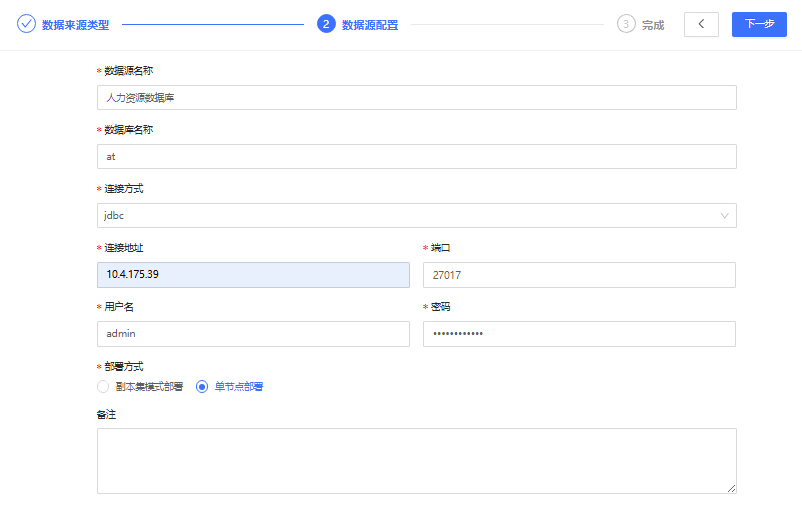
副本集模式部署
创建基本步骤可参考以上文档内容。创建NoSQL-MongoDB数据源-人力资源数据库2的具体配置信息示例如下:
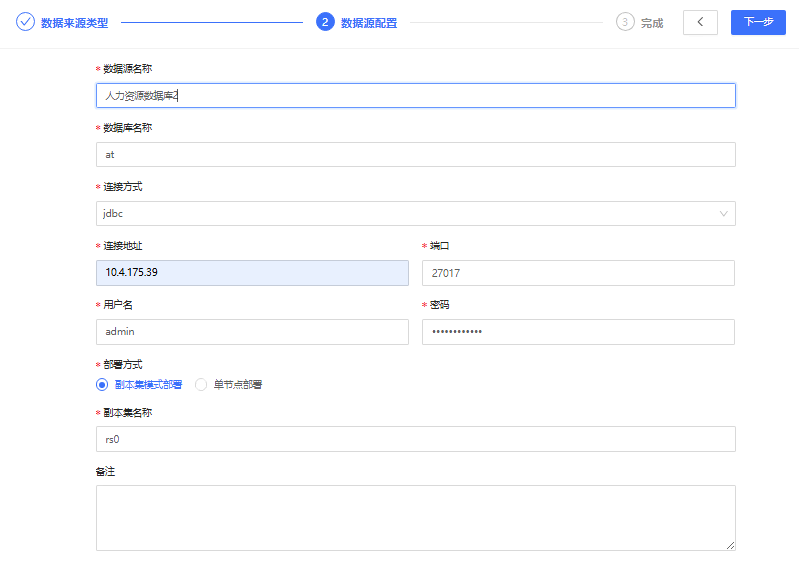
备注:连接方式默认为JDBC
_61.png) 说明:
说明:
- 单节点部署仅单一实例,简单且资源占用少,多用于开发测试或对数据可用性要求低的小型场景
- MongoDB 副本集部署是多节点,主从复制,可自动故障转移,提供高可用与数据冗余,适用于生产等对数据可靠性要求高的场景
结构化数据-ClickHouse数据源创建
创建基本步骤可参考以上文档内容。创建Others-ClickHouse-电商用户行为分析的具体配置信息示例如下:
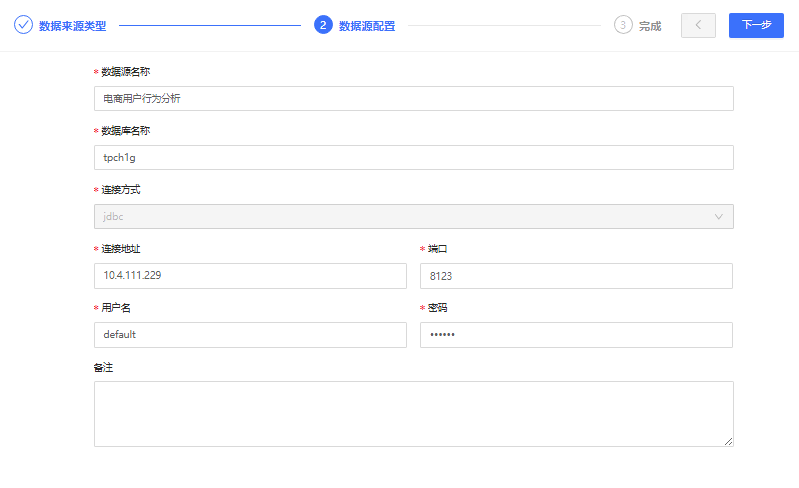
备注:连接方式默认为JDBC
结构化数据-TDH Inceptor数据源创建
创建基本步骤可参考以上文档内容。创建Others-ClickHouse-电商用户行为分析的具体配置信息示例如下:
备注:连接方式默认为JDBC
非结构化数据-Excel数据源创建
- 当数据连接-存储介质选择AnyShare时,创建基本步骤可参考以上文档内容。创建爱数技术资料的数据源具体配置信息示例如下:
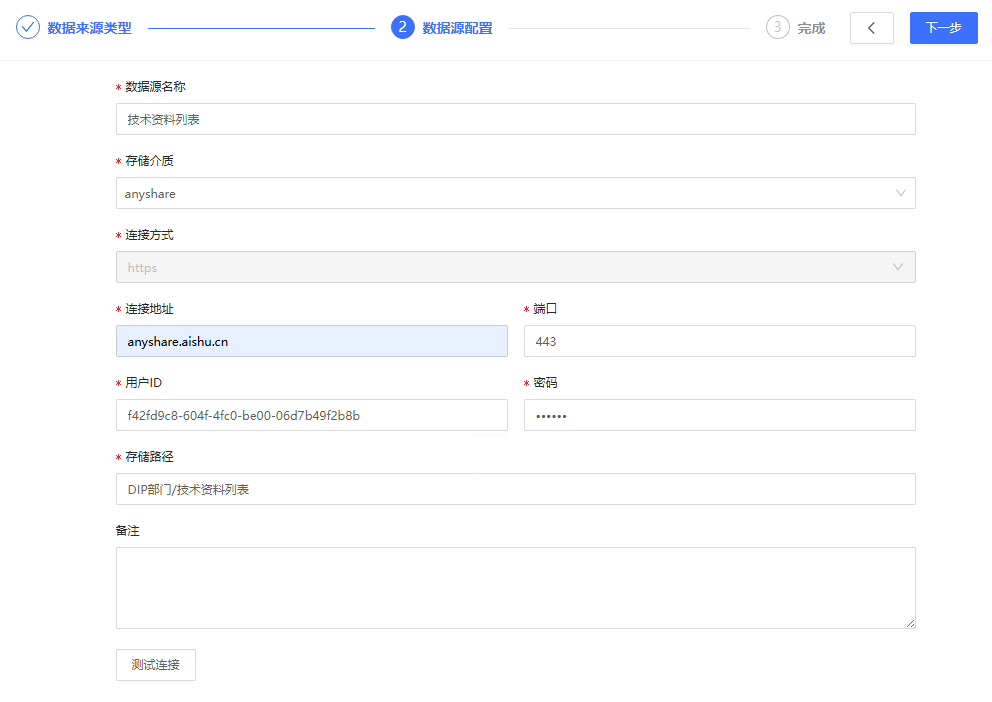
备注:连接方式默认为HTTPS
配置说明:
-
- 连接地址:AnyShare服务的IP或者域名(anyshare.aishu.cn)
- 端口:443
- 用户ID和密码:即为AnyShare的应用账号ID和密码,AnyShare 7在管理控制台可创建应用账号;在文档库管理中需将应用账号添加至文档库管理者,保证应用账号具备文档库路径的访问权限
- 存储路径:仅支持部门文档库或自定义文档库,且路径不需要AnyShare前缀;可以指定单个文件,也可以指定目录,但是只支持.xlsx类型文件。如果指定目录,会接入一级子菜单下的.xlsx文件
注意:仅支持AnyShare 7.0以及之前的版本接入。Proton更新至3.0之后,应用账号对应的创建及授权方式变更,无法指定到部门文档库和自定义文档库。后续方案待定。
- 当数据连接-存储介质选择文档库时,创建基本步骤可参考以上文档内容。创建爱数技术资料的具体配置信息示例如下:
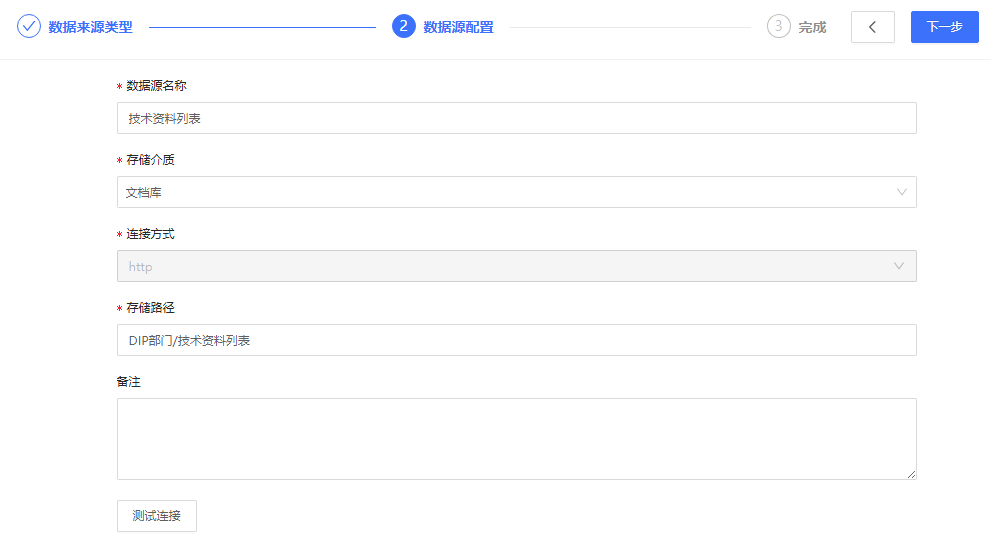
配置说明:
-
- 存储路径:仅支持部门文档库或自定义文档库,且路径不需要AnyShare前缀;可以指定单个文件,也可以指定目录,但是只支持.xlsx类型文件。如果指定目录,会接入一级子菜单下的.xlsx文件
非结构化数据-AnyShare 7.0 数据源创建
创建基本步骤可参考创建Excel数据源,存储介质选择AnyShare时的具体配置信息及相关说明。
备注:连接方式默认为HTTPS
说明:
- 当数据源类型选择Hive时,连接方式可选JDBC、Thrift
查看数据连接详情
点击目标数据连接的操作列的查看,即可查看数据连接详情。
- 表属性

- 字段属性

扫描管理
使用整个数据连接创建
进入VEGA虚拟化 > 扫描管理配置页面,点击【+新建扫描任务】 > 【使用整个数据连接创建】,选择需要扫描的数据源,点击开始扫描,如下所示:

扫描页面展示当前扫描进度(如下图),刷新或关闭页面都会造成扫描终止,将停止扫描还未扫描的数据源,但会保留已扫描的数据源。扫描终止或完成后页面弹窗提示扫描成功的数据源数量。

返回扫描管理,页面右侧展示全部已扫描数据源,及其扫描状态、扫描情况和创建人、创建时间等信息。

使用数据连接中的表创建
进入VEGA虚拟化 > 扫描管理配置页面,点击【+新建扫描任务】 > 【使用数据连接中的表创建】,选择需要扫描的库表,点击开始扫描,如下所示:

说明:使用数据连接中的表创建仅适用于OpenSearch。