1 地址修改说明
1.1 AnyShare & ECeph 融合部署组网说明
AnyShare & ECeph融合部署一般有2个网段:
- 业务IP:AnyShare各个组件所使用的网段,包括K8S集群。
- 内部IP:OSSgateway & ECeph使用,为存储内部使用网段。它可能是部署服务自动生成的带ip标签的IP,也可能是手动配置的IP。
有时为了部署方便,内部IP会复用业务IP,也就是说单节点仅使用1个网段,但该方案有严重的性能及稳定性隐患,不推荐该部署方式。
另外,多节点情况下,AnyShare建议配置高可用(业务VIP),在启用OSSgateway的情况下,ECeph建议配置内部高可用IP(内部VIP),即用户通过业务VIP连接AnyShare,而AnyShare使用内部VIP连接存储。
未启用OSSgateway的情况下,ECeph建议配置外部IP高可用(业务VIP2),即用户通过业务VIP连接AnyShare,而用户和AnyShare使用业务VIP2连接存储,这种情况下,业务VIP2一般会复用业务VIP1。
因此,集群中每个节点至少需要2个IP,另外可根据需要配置VIP。
1.2 AnyShare & ECeph IP地址修改说明
存在以下几种IP地址修改情景:
| 已部署环境 | 修改场景 | 涉及操作 |
|---|---|---|
| 采用推荐组网方案:业务IP与内部IP不同网段 | 仅修改业务IP | 修改K8S 集群IP 修改ECeph管理程序IP 修改OSSGateway相关配置 |
| 仅修改内部IP | 修改ECeph内部IP 修改OSSGateway相关配置 |
|
| 修改业务IP及内部IP | 综上 | |
| 未采用推荐的组网方案:业务IP与内部IP相同 | 修改业务IP,同时新增内部IP | 修改K8S集群IP 修改ECeph管理程序IP 修改OSSGateway相关配置 修改ECeph内部IP |
该文档针对上述场景进行了说明,操作前注意如下限制:
- 该文档仅适用于AnyShare 与Proton ECeph融合部署场景。Proton ECeph独立部署场景请参考《ECeph集群(独立部署)IP地址修改指导手册》。
- 更换IP地址期间,业务中断,需停机操作。
- 所有新节点IP需要保持同一网段。
- 若需要修改高可用IP,请确保高可用VIP与节点IP保持同一网段。
2 两个网段部署,修改业务IP
2.1 修改前IP地址信息收集
为已有集群收集以下信息,并填入下面的表格。
-
节点的hostname及业务IP地址(运行
kubectl get nodes -o wide查看)。 -
对象存储内部地址:
cat /opt/minotaur/config/minotaur.conf, 对应internal_ip。 -
业务IP及内部IP地址对应的网卡名。
-
业务高可用IP地址:
cat /etc/keepalived/keepalived.conf;ECeph VIP对应eceph_vip实例,AnyShare VIP对应SLB_HA实例。 -
apiserver访问地址:
grep server ~/.kube/config获取。 -
etcd数据目录地址:
grep data-dir /etc/kubernetes/manifests/etcd.yaml获取。 -
确保新业务IP未被占用。
| hostname | 角色 | 业务IP | 内部IP | 节点IP对应网卡名 | 内部IP地址对应网卡名 | 新业务IP |
|---|---|---|---|---|---|---|
| node-224-13 | master | 192.168.224.13 | 1.3.5.38 | bond1 | bond0 | 192.168.224.44 |
| node-224-17 | master | 192.168.224.17 | 1.3.5.36 | bond1 | bond0 | 192.168.224.45 |
| node-224-18 | master | 192.168.224.18 | 1.3.5.37 | bond1 | bond0 | 192.168.224.46 |
| AnyShare VIP地址 | 192.168.224.222 | 192.168.224.48 | ||||
| ECeph VIP地址 | 192.168.224.35 | 192.168.224.47 | ||||
| apiserver 访问地址 | proton-cs.lb.aishu.cn:16643 | |||||
| etcd数据目录地址 | /var/lib/etcd |
2.2 K8S网段修改
第1步 备份etcd
在kubernetes etcd能正常运行时,比如换IP前集群正常工作时,一定要做备份,否则无法恢复。
注意:备份只需要在一个master节点执行,但每个节点都需要安装etcdctl,后续恢复需要使用。若备份失败不要往下执行。
- 安装etcdctl
如果执行 etcdctl version 能够正常输出,则跳过安装etcdctl,若无法执行etcdctl命令则需要安装etcdctl(每个master节点都需要安装),执行命令(请根据实际环境选择安装x86或arm版本):
rpm -ivh proton-cs-etcdctl-3.5.7-1.el7.proton.x86_64.rpm
- 备份kubernetes etcd
执行如下命令:
alias etcdctl="etcdctl --cacert=/etc/kubernetes/pki/etcd/ca.crt --cert=/etc/kubernetes/pki/etcd/peer.crt --key=/etc/kubernetes/pki/etcd/peer.key --endpoints=https://127.0.0.1:2379"
etcdctl snapshot save /root/etcd-backup.db

第2步 停止kubelet和containerd服务
注意:需要在所有节点执行,包括master节点和worker节点
执行命令:
systemctl stop kubelet containerd
第3步 更换IP地址
注意:该章节需要在所有节点执行,包括master节点和worker节点。由于修改IP,当前SSH连接会断开,为方便排查网络连接问题,需提前准备BMC远程。
- 修改节点ip
编辑文件:vi /etc/sysconfig/network-scripts/ifcfg-<网卡名>
- 重启网络服务
RHEL/CentOS 8及OpenEuler 22以上系统使用nmcli命令:
nmcli connection reload && nmcli connection down <网卡名> && nmcli connection up <网卡名>
RHEL/CentOS 7使用命令:
systemctl restart network
- 确认新的IP配置成功,且相互之间能够通信。
- /etc/hosts IP地址修改
/etc/hosts中包含业务IP相关配置,改为新的业务IP地址信息。worker节点的IP也要更新。
单节点集群命令示例:
sed -i "s/原master IP/新master IP/g" /etc/hosts
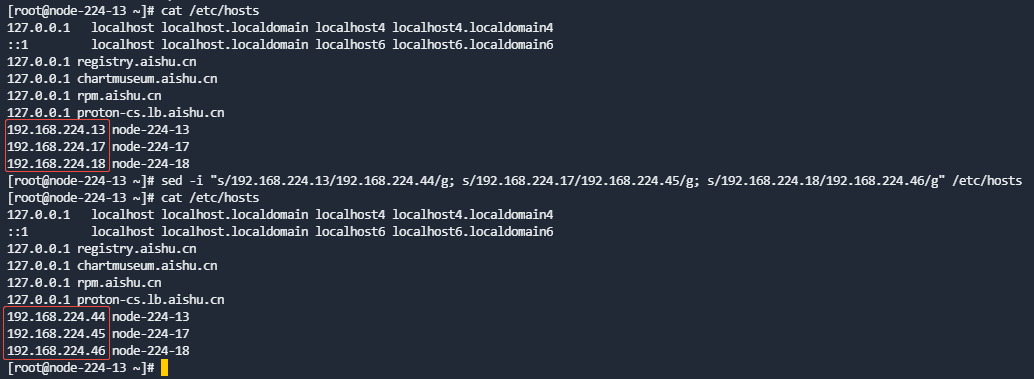
多节点集群命令示例:
sed -i "s/192.168.224.13/192.168.224.44/g; s/192.168.224.17/192.168.224.45/g; s/192.168.224.18/192.168.224.46/g" /etc/hosts
第4步 替换新IP并生成新证书
在所有master节点执行
- 备份kubernetes 配置,执行:
cp -Rf /etc/kubernetes /etc/kubernetes.bak
- 替换IP地址,执行
ip地址请根据实际环境进行替换
cd /etc/kubernetes
find . -type f | xargs sed -i " s/原master IP/新master IP/g "
多节点集群命令示例:
find . -type f | xargs sed -i "s/192.168.224.13/192.168.224.44/g; s/192.168.224.17/192.168.224.45/g; s/192.168.224.18/192.168.224.46/g"
- 修改完成后可以通过搜索原masterIP来确认是否替换完成。
find . -type f | xargs grep 192.168.224.13(原masterIP)

- 替换
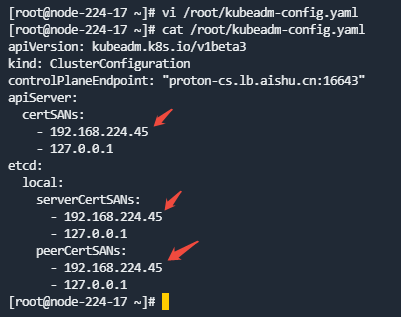
/root/kubeadm-config.yaml配置文件内容
rm -f /root/kubeadm-config.yaml
新增如下配置:vi /root/kubeadm-config.yaml, IP地址根据实际环境进行替换(即各master节点填写各自ip),如果有IPv6地址也需要填进去。
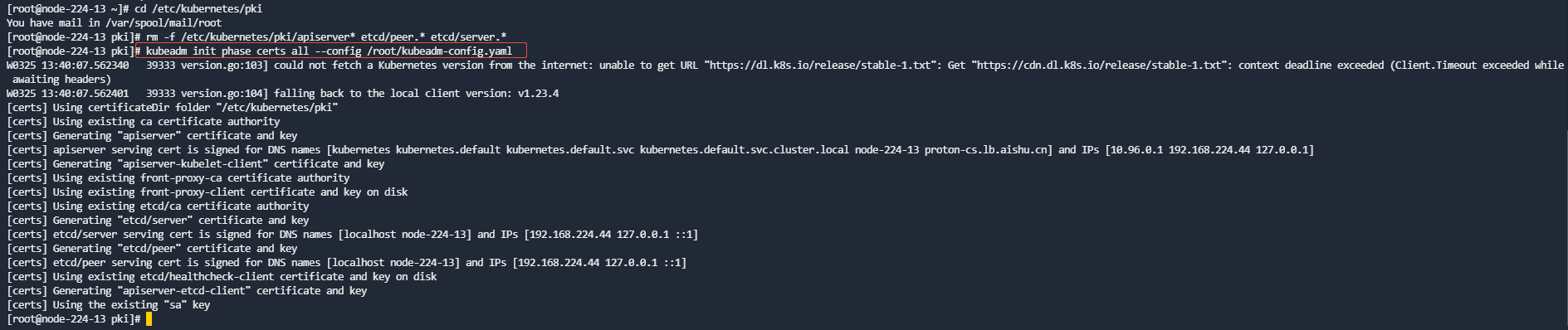
- 重新生成证书,执行:
cd /etc/kubernetes/pki
rm -f /etc/kubernetes/pki/apiserver* etcd/peer.* etcd/server.*
kubeadm init phase certs all --config /root/kubeadm-config.yaml
第5步 恢复etcd
- 复制etcd快照到各个master节点,执行如下命令:
cp /root/etcd-backup.db /tmp/
scp /root/etcd-backup.db 192.168.224.45:/tmp
scp /root/etcd-backup.db 192.168.224.46:/tmp
- 恢复etcd
注意: 恢复时不会改变主机名,因此主机名还是复用原来的,下列命令执行时需要在对应master节点上执行,不能错乱。注意下述命令中的主机名、IP及etcd数据目录地址需要填写实际环境信息。
node-224-13 节点执行:
mv /var/lib/etcd /var/lib/etcd.bak
mkdir /var/lib/etcd
etcdctl snapshot restore /tmp/etcd-backup.db --name node-224-13 --initial-cluster node-224-13=https://192.168.224.44:2380,node-224-17=https://192.168.224.45:2380,node-224-18=https://192.168.224.46:2380 --initial-advertise-peer-urls=https://192.168.224.44:2380 --data-dir=/var/lib/etcd
node-224-17 节点执行:
mv /var/lib/etcd /var/lib/etcd.bak
mkdir /var/lib/etcd
etcdctl snapshot restore /tmp/etcd-backup.db --name node-224-17 --initial-cluster node-224-13=https://192.168.224.44:2380,node-224-17=https://192.168.224.45:2380,node-224-18=https://192.168.224.46:2380 --initial-advertise-peer-urls=https://192.168.224.45:2380 --data-dir=/var/lib/etcd
node-224-18 节点执行:
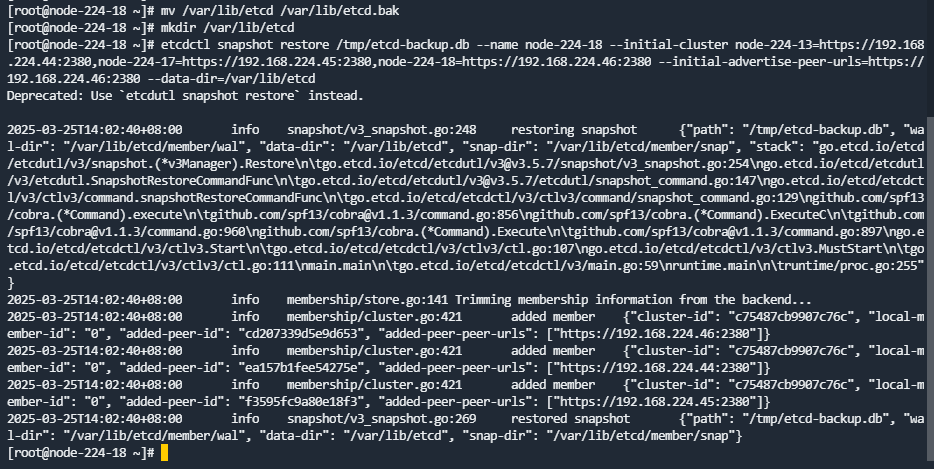
mv /var/lib/etcd /var/lib/etcd.bak
mkdir /var/lib/etcd
etcdctl snapshot restore /tmp/etcd-backup.db --name node-224-18 --initial-cluster node-224-13=https://192.168.224.44:2380,node-224-17=https://192.168.224.45:2380,node-224-18=https://192.168.224.46:2380 --initial-advertise-peer-urls=https://192.168.224.46:2380 --data-dir=/var/lib/etcd
第6步 更新haproxy、kubelet、hosts、firewalld对应地址
注意:该步骤需要在所有节点上执行,包括master节点和worker节点。下述举例只有3个IP,当有worker节点时,对应的IP也要做更新操作。
- 更新haproxy
每个节点上的haproxy.cfg配置都一样,改完一个节点后可直接覆盖其他节点。
修改/usr/local/haproxy/haproxy.cfg配置文件:
sed -i " s/原master IP/新master IP/g " /usr/local/haproxy/haproxy.cfg
多节点集群命令示例:
sed -i "s/192.168.224.13/192.168.224.44/g; s/192.168.224.17/192.168.224.45/g; s/192.168.224.18/192.168.224.46/g" /usr/local/haproxy/haproxy.cfg
修改完成后使用命令cat /usr/local/haproxy/haproxy.cfg|grep 原master IP, 确认是否替换完成。
更新后重启服务:
systemctl restart haproxy
- 更新kubelet上报心跳节点IP,各节点分别执行。
node-224-13执行:
sed -i "s/192.168.224.13/192.168.224.44/" /var/lib/kubelet/kubeadm-flags.env
node-224-17执行:
sed -i "s/192.168.224.17/192.168.224.45/" /var/lib/kubelet/kubeadm-flags.env
node-224-18执行
sed -i "s/192.168.224.18/192.168.224.46/" /var/lib/kubelet/kubeadm-flags.env

- 更新firewalld
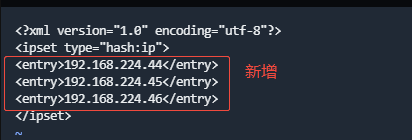
编辑文件:vi /etc/firewalld/ipsets/proton-cs-host.xml,新增下面行(IP需要根据实际的替换):
<entry>10.4.14.205</entry>
<entry>10.4.14.206</entry>
<entry>10.4.14.207</entry>
第7步 设置防火墙
每个节点的防火墙根据需要对新的业务IP地址放行。
firewall-cmd --add-rich-rule="rule family="ipv4" source address=${ip} accept";firewall-cmd --permanent --add-rich-rule="rule family="ipv4" source address=${ip} accept"
注意:若有VIP,此处防火墙也需要添加VIP地址,可以使用for循环批量添加
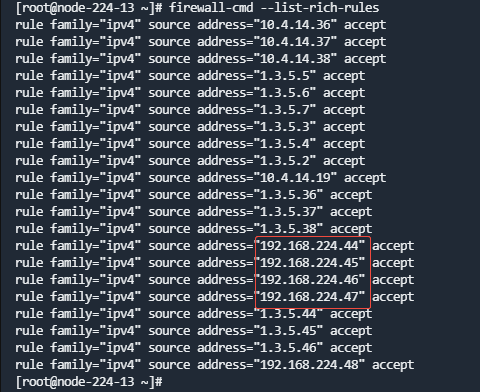
for i in 192.168.224.44 192.168.224.45 192.168.224.46 192.168.224.47 192.168.224.48;do firewall-cmd --add-rich-rule="rule family="ipv4" source address=$i accept";firewall-cmd --permanent --add-rich-rule="rule family="ipv4" source address=$i accept";done
firewall-cmd --list-rich-rules查看添加后的结果
第8步 删除旧容器、旧路由表,并重启firewalld、kubelet、containerd
注意:该章节需要在所有节点执行,包括master节点和worker节点
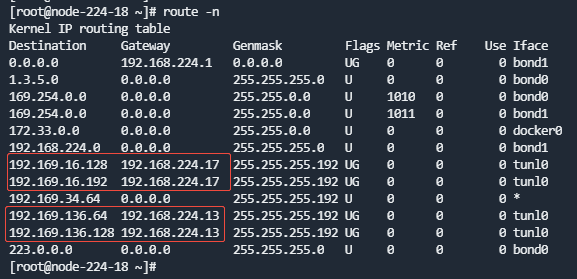
- 查看所有路由表:
route -n
找到Gateway为集群中其他节点业务IP的路由。
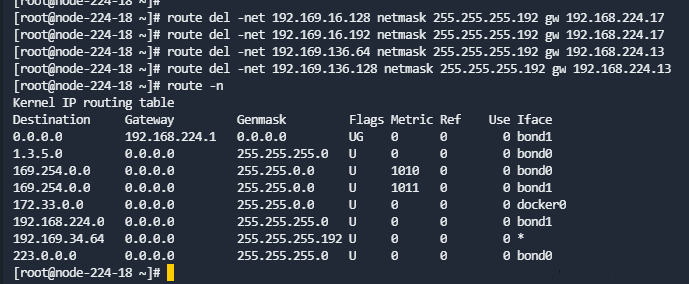
- 删除旧路由(192.168.224.1x是旧IP):
route del -net 192.169.x.x netmask 255.255.255.192 gw 192.168.224.1x
- 删除旧容器:
docker container prune
- 重启服务:
systemctl restart firewalld containerd kubelet
第9步 检查容器是否启动
运行kubectl get pods -n kube-system以及kubectl get pods -A查看容器是否启动。
运行kubectl get nodes -o wide -A查看IP是否为新IP。

如果网络不通,再检查一次路由表,如果未更新,或未出现跨节点的网关路由,需要把calico-node-xxx 的pod delete,重建出来路由表后网络可恢复正常。如果存在pod为0/1 running状态,查看该pod是否还是使用的旧的IP,重启该pod。此时proton-eceph-config-manager服务可能起不来,先忽略。
第10步 更新proton-cli-config的节点所对应ip
注意:该步骤可在任意一个master节点执行
-
进入proton依赖安装包的解压目录proton-packages目录下
-
获取集群配置:
proton-cli get conf > cluster.yaml
- 编辑配置,修改 cluster.yaml里面 nodes 所对应的节点ip地址以及eceph对应的外部VIP地址(如果配置了外部VIP地址的话)。
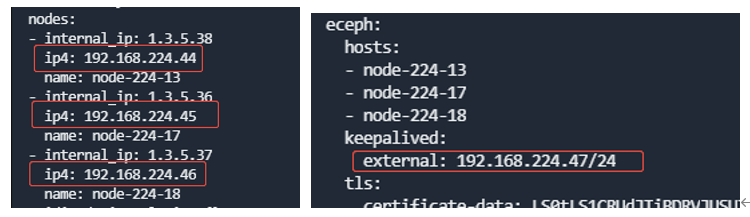
- 执行更新配置
proton-cli apply -f cluster.yaml
第11步 修改AS高可用IP
AS高可用及节点IP在数据库中有记录,需要修改数据库。
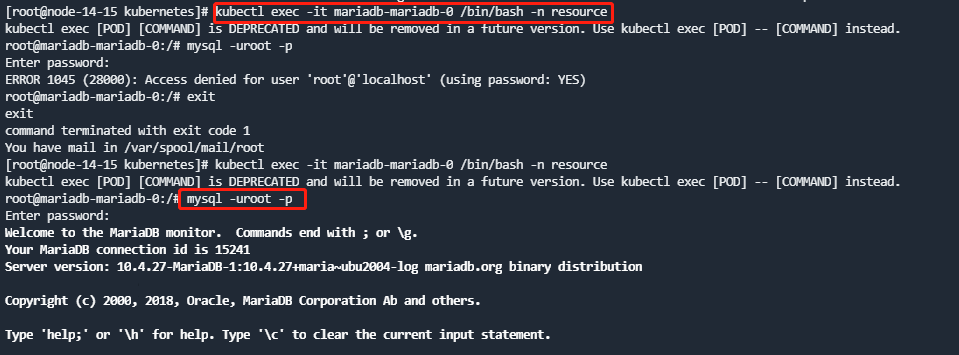
- 连接数据库,并执行如下sql修改nodemgnt库中node表中的节点IP:
update node set f_node_ip="{new_ip}" where id={id};

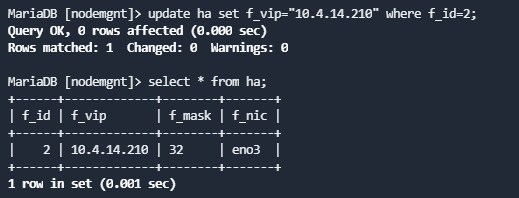
- 执行如下sql修改nodemgnt库中ha表中的节点VIP。
update ha set f_vip="{new_vip}" where f_id={id};
- 执行如下命令keepalived.conf。
注意:每个高可用节点都需要执行。
sed -i "s/192.168.224.13/192.168.224.44/" /etc/keepalived/keepalived.conf
sed -i "s/192.168.224.17/192.168.224.45/" /etc/keepalived/keepalived.conf
sed -i "s/192.168.224.18/192.168.224.46/" /etc/keepalived/keepalived.conf
sed -i "s/192.168.224.222/192.168.224.48/" /etc/keepalived/keepalived.conf
- 所有高可用节点,运行如下命令重启keepalived。
systemctl restart keepalived
然后检查vip配置,注意只有一个节点上运行ov标记的VIP。

第12步 修改AS访问地址
- 执行如下命令修改AS访问地址,注意:host为新的VIP地址:
curl `kubectl get svc -n anyshare deploy-service -ojsonpath={.spec.clusterIP}:{.spec.ports[0].port}`/api/deploy-manager/v1/access-addr/app -XPUT -d'{"host":"192.168.224.48","port": "443","type":"external"}'

- 进入部署控制台更新证书。
点击配置证书,生成新的证书。

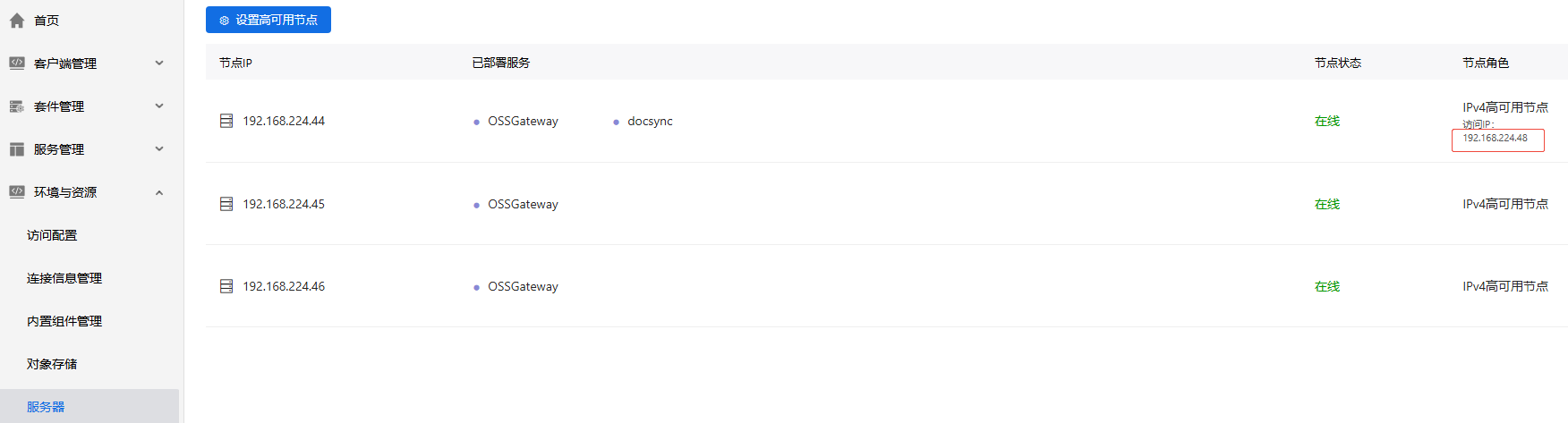
- 在部署控制台【服务器】页签,检测高可用状态是否准确。
2.3 ECeph管理程序网段修改
第1步 配置文件备份
集群中所有节点的/etc/ceph/ceph.conf和/opt/minotaur/config/minotaur.conf配置文件都需备份。执行命令如下:
cp /etc/ceph/ceph.conf /etc/ceph/ceph.conf.bak
cp /opt/minotaur/config/minotaur.conf /opt/minotaur/config/minotaur.conf.bak1

第2步 修改/opt/minotaur/config/minotaur.conf
ECeph集群中所有节点的/opt/minotaur/config/minotaur.conf文件中的node_ip及object_ip修改为新IP,并重启eceph-config-agent服务(systemctl restart eceph-config-agent)。

第3步 修改/etc/ceph/ceph.conf
ECeph集群中所有节点的/etc/ceph/ceph.conf文件中[infomon]模块下的节点IP改为新IP。
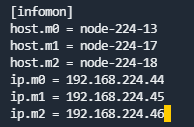
第4步 修改数据库
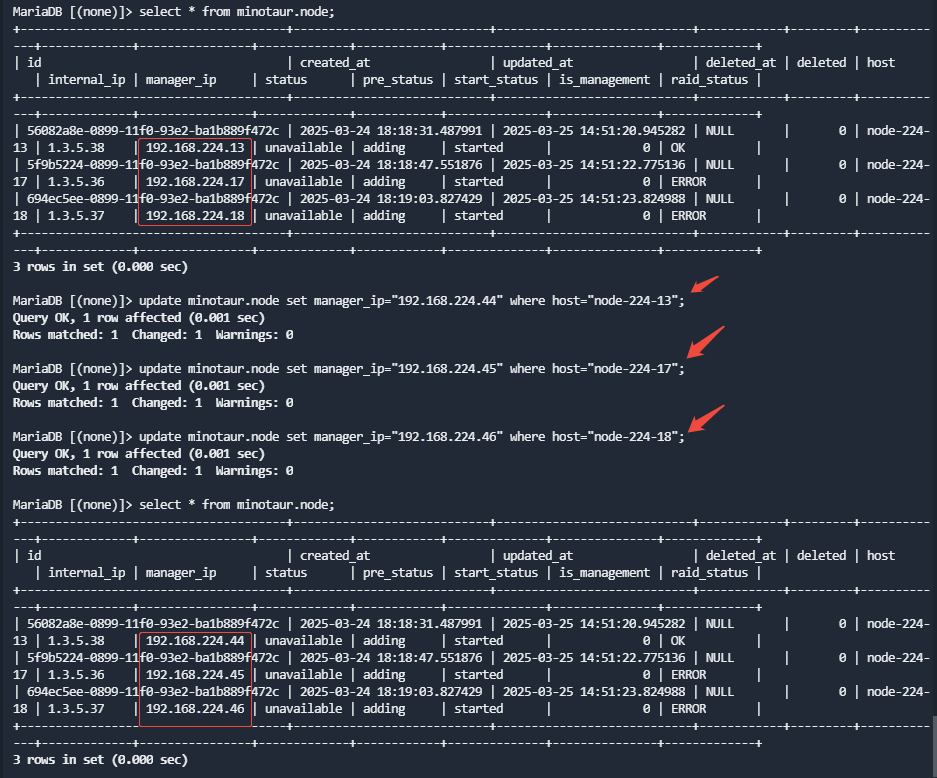
在任意一个master节点执行
进入minotaur数据库,使用如下sql更新node表:
update minotaur.node set manager_ip="{new_ip}" where host="{hostname}";
修改完成后通过select * from minotaur.node; 确认是否替换完成。
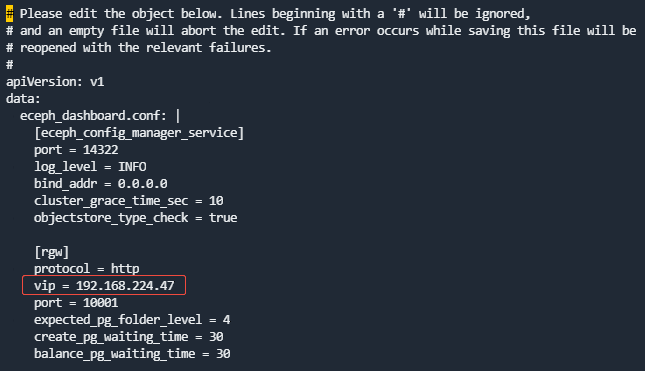
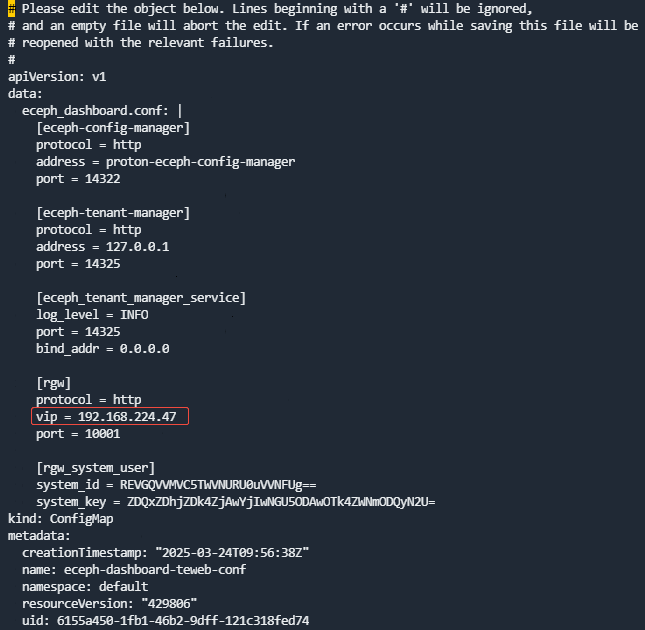
第5步 修改管理服务cm
在任一master节点修改eceph-config-manager和eceph-tenant-web容器的cm:
kubectl edit cm eceph-dashboard-confmanager-conf
kubectl edit cm eceph-dashboard-teweb-conf
将[rgw]块下的vip修改为对应的新IP。此处可能是VIP,也可能是节点IP(如果没有设置VIP)。
无论是否修改,都重启管理服务的pod
kubectl get pods | grep -E 'proton-eceph-config-manager|proton-eceph-tenant-web' | awk '{print $1}' | xargs -i kubectl delete pod {}

第6步 查看ECeph集群管理页面显示
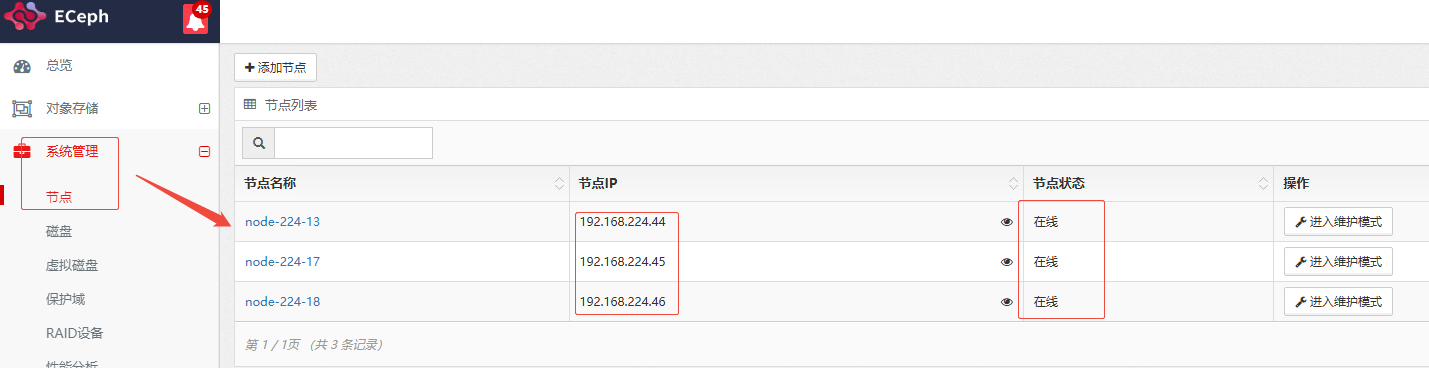
使用新的IP地址登录WEB管理页面,进入【系统管理】-【节点】中查看节点IP和节点状态,此时节点IP应是新的IP且节点应该都在线。
第7步 修改外部VIP(可选)
如果在2.2的第10步中更新过eceph_vip,该步骤可跳过。
所有节点进行/etc/keepalived/keepalived.conf中eceph_vip部分的节点IP和VIP进行修改。
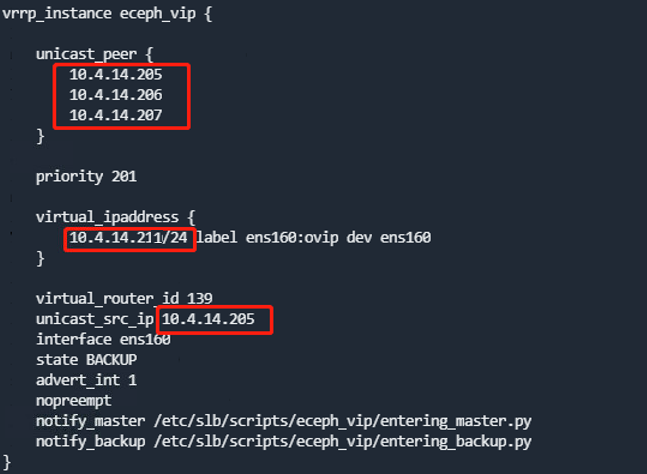
运行如下命令重启keepalived,然后检查vip配置,注意只有一个节点上运行了ovip标签的vip。
systemctl restart keepalived

第8步 检查SLB-Nginx转发配置
ECeph通过SLB-Nginx对外提供对象存储访问接口:10001和10002。当融合部署有两个网段时,此处使用的是内部IP。如果是内部IP则不需要进行修改,若使用的是业务IP,修改为新业务IP(未启用OSSGateway的情况下)或者内部IP(启用OSSGateway的情况下)。
- 进入集群每个节点
/usr/local/slb-nginx/conf.d/http/目录下,查看eceph_10001.conf和eceph_10002.conf配置文件。

- 重新加载SLB-Nginx配置,修改了配置的每个节点运行如下命令:
systemctl reload slb-nginx
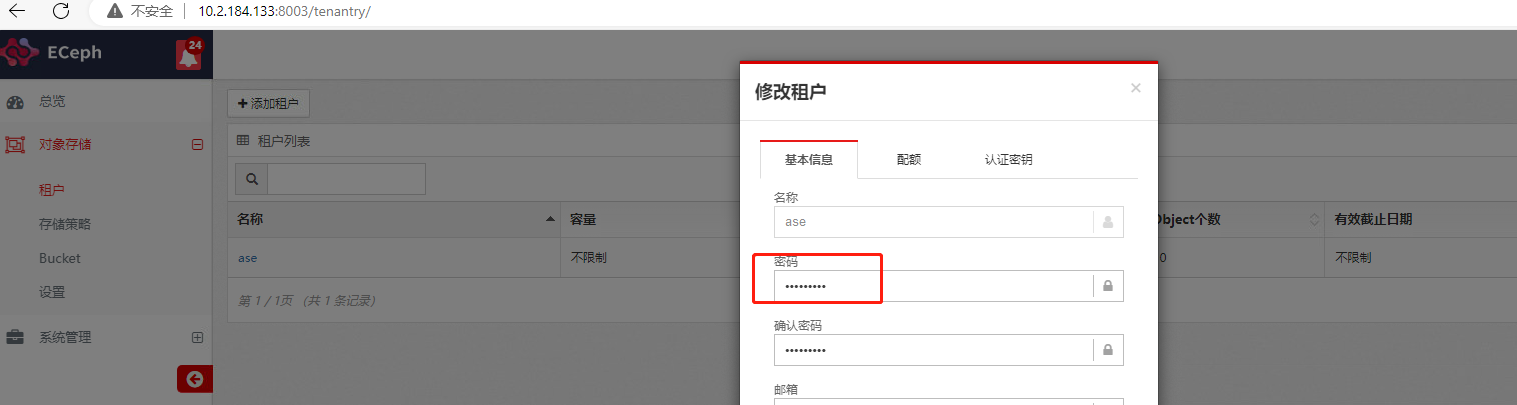
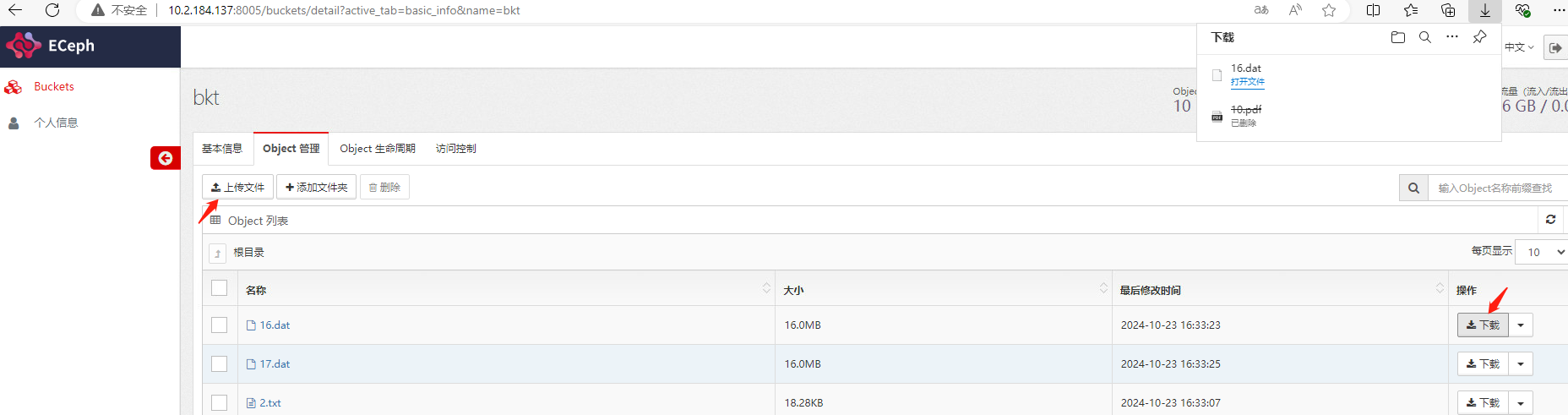
- 测试对象上传下载,登陆ECeph租户管理页面
http://{ip}:8005,使用租户登陆,进入对象管理页面。测试上传下载文件。其中用户名为租户名称,密码为创建租户时设置的密码。
2.4 存储配置相关修改
第1步 cms-release-config-ossgateway配置修改
其一master节点执行:
- 执行命令查询:
kubectl -nanyshare get secret cms-release-config-ossgateway -o yaml
- 执行命令将上一步查询返回的default.yaml部分进行base64解码并重定向到一个文件:
echo "xxxxx" |base64 -d > default.yaml
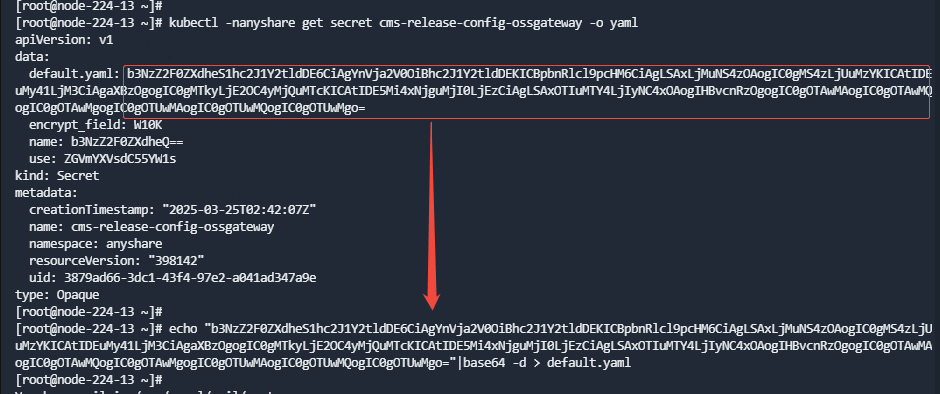
- 修改default.yaml,将所有ips中的IP修改为新的业务IP。
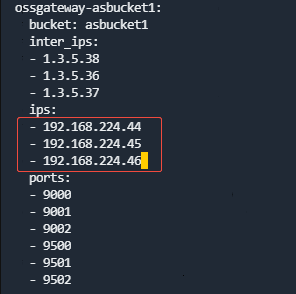
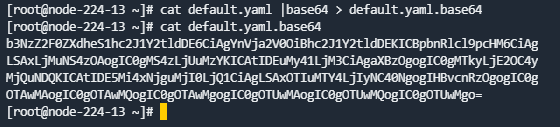
- 将default.yaml重新base64编码:
cat default.yaml | base64 > default.yaml.base64
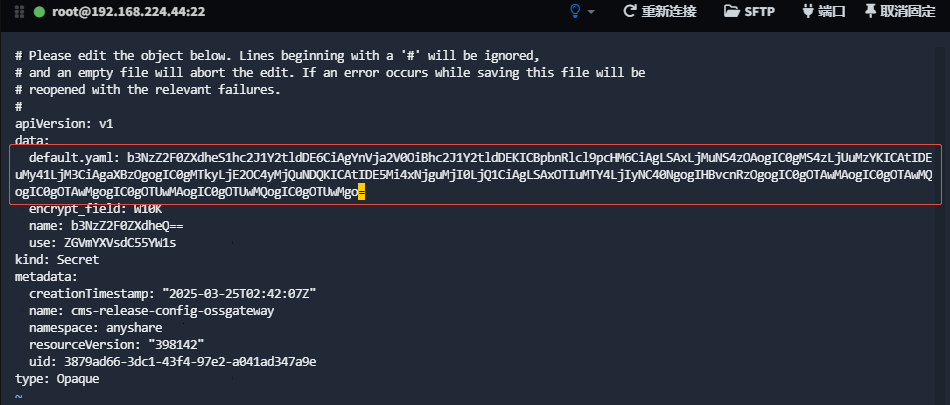
- 将再次Base64编码的结果替换至secret cms-release-config-ossgateway中原始部分(手动重组,注意中间不要有换行):
kubectl -nanyshare edit secret cms-release-config-ossgateway
第2步 OSSGateway ep配置检查
运行kubectl get ep -A|grep ossgateway-查看ep是不是用的内部IP,如果不是,手动修改为内部IP。修改命令为:
kubectl edit ep ossgateway-{bucket} -n anyshare

第3步 修改存储连接配置
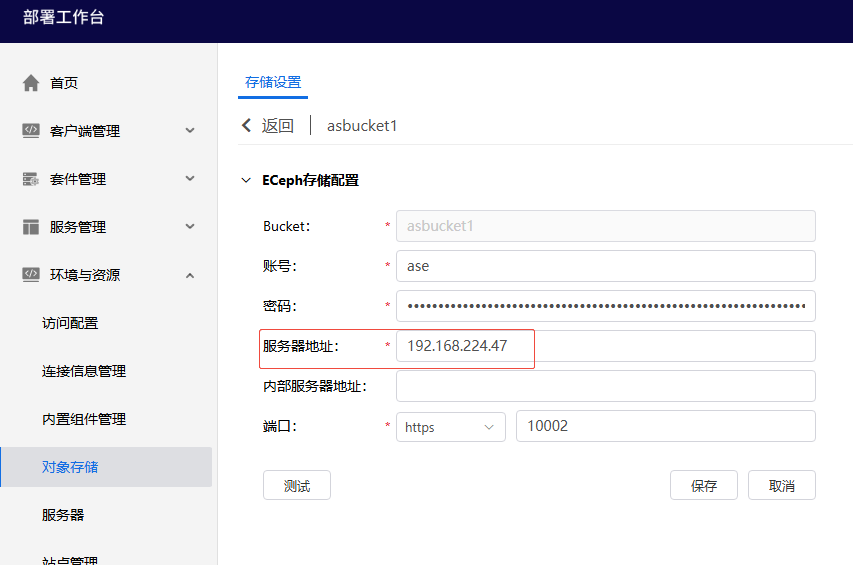
进入部署控制台,对象存储页面,修改存储连接配置。若服务器地址使用的是AnyShare原VIP,此处需要改为AnyShare 新VIP,或者ECeph的ovip。** 即使此处不需要修改,也需要保存一下** ,保证mongodb中的配置更新。保存后进行文件上传下载测试。
3 两个网段部署,修改内部地址
说明:建议先通读步骤,理解每一步的含义。执行时,需严格按照顺序执行,否则可能造成集群不可用。有任何疑问请联系爱数工程师。
3.1 修改前IP地址信息收集
为已有集群收集以下信息,并填入下面的表格。
-
节点列表信息:hostname及业务IP地址。运行
kubectl get nodes -o wide查看 -
对象存储内部地址:
cat /opt/minotaur/config/minotaur.conf, 对应internal_ip。 -
业务IP及内部IP地址对应的网卡名。
-
ceph的每个mon节点信息,以及mon名称(例如m0,m1)从/etc/ceph/ceph.conf中获取。
-
确保新内部IP未被占用。
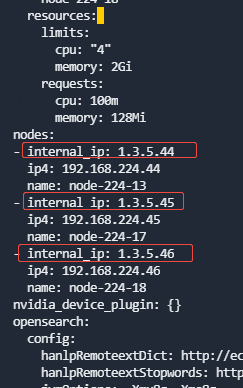
主机名 业务IP 内部IP 节点IP对应网卡名 内部IP地址对应网卡名 新内部IP Mon名称 node-224-13 192.168.224.44 1.3.5.38 bond1 bond0 1.3.5.44 m0 node-224-17 192.168.224.45 1.3.5.36 bond1 bond0 1.3.5.45 m1 node-224-18 192.168.224.46 1.3.5.37 bond1 bond0 1.3.5.46 m2 ECeph VIP地址 无 无
3.2 新增内部IP
融合部署的的内部可能有其他服务使用(如数据库),因此不修改已有内部IP,而是通过新增网卡配置文件来新增IP。
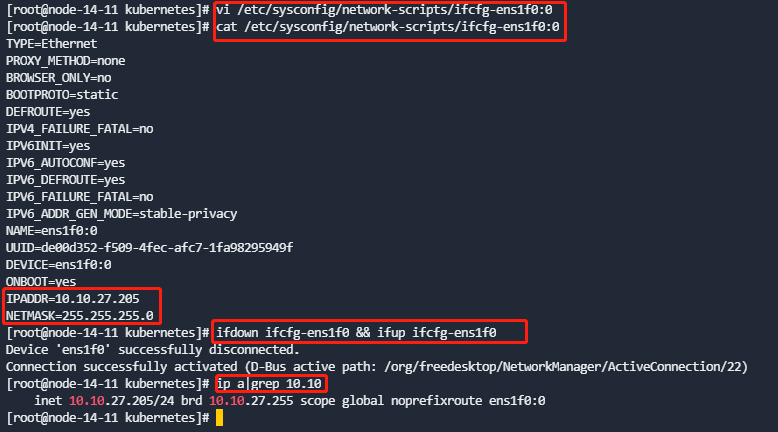
第1步 新增内部IP
-
进入
/etc/sysconfig/network-scripts/目录,复制/etc/sysconfig/network-scripts/ifcfg-XXXX为一个子设备名,并设置新的IP地址。注意配置文件中的NAME及DEVICE需要改为对应的子设备名。每个节点上操作。 -
修改后重启对应网卡,确认新的IP配置成功,且相互之间能够通信。
CentOS使用ifdown <网卡名> && ifup <网卡名>
OpenEuler使用nmcli connection reload && nmcli connection down <网卡名> && nmcli connection up <网卡名>

第2步 检查/etc/hosts
若其中包含内部IP相关配置,改为新的内部IP地址信息。
第3步 设置防火墙
每个节点的防火墙根据需要对新的业务IP地址放行。
for i in 1.3.5.44 1.3.5.45 1.3.5.46;do firewall-cmd --add-rich-rule="rule family="ipv4" source address=$i accept";firewall-cmd --permanent --add-rich-rule="rule family="ipv4" source address=$i accept";done
3.3 更新proton-cli-config的节点所对应的internal_ip
注意:该章节可在任意一个master节点执行
-
进入proton依赖安装包的解压目录proton-packages目录下。
-
获取集群配置:
proton-cli get conf > cluster.yaml
- 编辑配置,修改cluster.yaml里面nodes所对应的internal_ip地址以及eceph对应的内部VIP地址(如果配置了内部VIP地址的话)。
- 执行更新配置:
proton-cli apply -f cluster.yaml
3.4 ECeph网段修改
第1步 Ceph mon配置修改
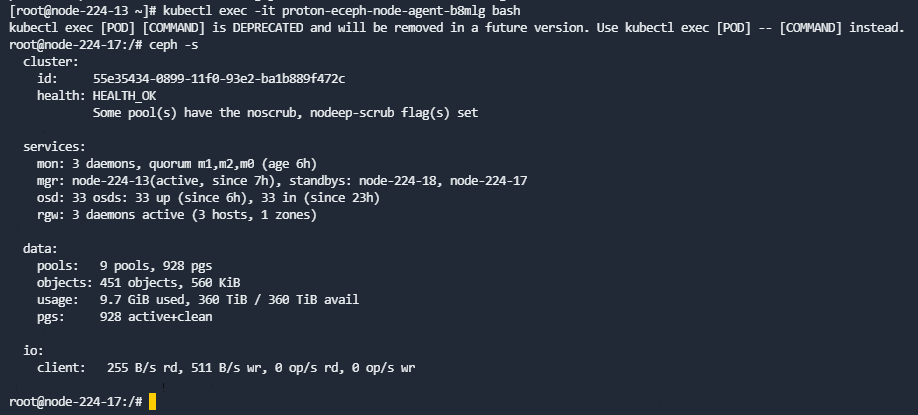
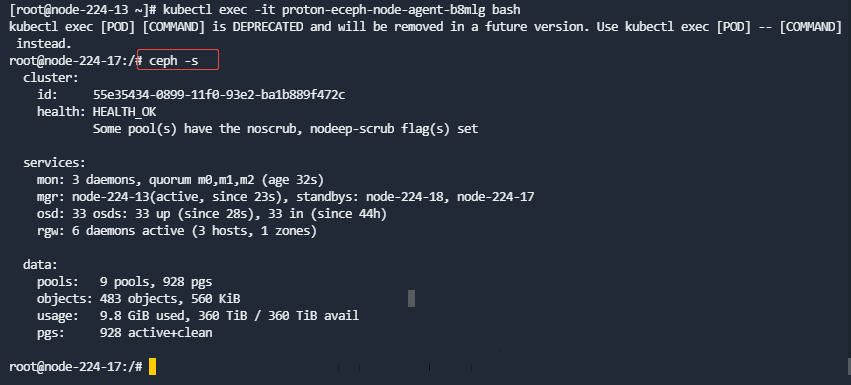
- 查看集群状态
ECeph7.10.0之前的版本在主机运行ceph -s,ECeph 7.10.0及之后版本需要进入eceph-node-agent的容器运行(所有ceph相关的命令都需要在该容器运行),查看输出,确保集群状态健康、所有的服务都正常(包括3个mon,3个mgr,所有osd),且数据都正常(所有pg都是active + clean)。
- 导出mon配置
选择任一ceph-mon节点的mon配置,运行如下命令(容器里执行):
ceph mon getmap -o /var/log/monmap.bin

- 查看导出的mon配置
运行如下命令查看当前的mon配置信息(容器里执行):
monmaptool --print /var/log/monmap.bin
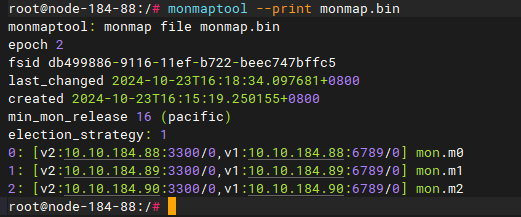
注意:ECeph 7.30.0之前的版本(L版本)只有v1协议,ECeph 7.30.0及之后的版本(P版本)新增了v2协议。
ECeph7.30.0之前的版本打印查看原来的mon配置:
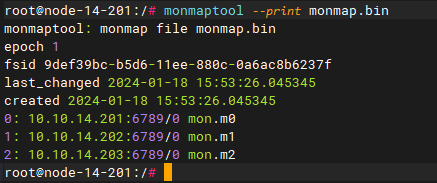
ECeph7.30.0及之后的版本查看原来的mon配置:
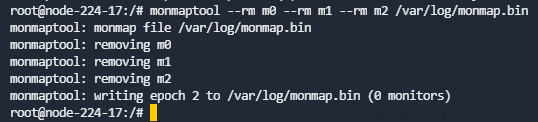
- 删除已有的mon配置
运行如下命令删除所有的mon信息,多个节点直接在后面加--rm {monid}即可。
monmaptool --rm {monid名称:例如m0} /var/log/monmap.bin
如:monmaptool --rm m0 --rm m1 --rm m2 /var/log/monmap.bin
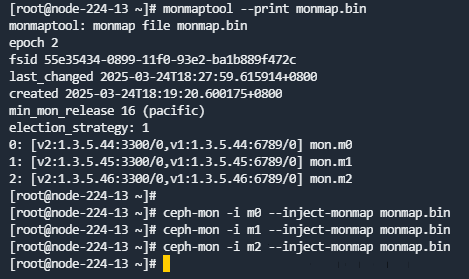
- 添加新的mon配置
运行如下命令添加新的mon信息(使用对应新的内部IP),添加多个,可多次使用--add {monid} {内部IP}:6789。然后查看配置是否准确。
ECeph 7.30.0之前的版本使用--add {monid} {内部IP}:6789:
monmaptool --add {monid名称:例如m0} {新的IP地址}:6789 /var/log/monmap.bin

ECeph 7.30.0及之后的版本使用--addv {monid} [v2:{内部IP}:3300, v1:{内部IP}:6789}]:
monmaptool --addv {monid名称:例如m0} [v2:{新的IP地址}:3300,v1:{新的IP地址}:6789] /var/log/monmap.bin
如:monmaptool --addv m0 [v2:1.3.5.44:3300,v1:1.3.5.44:6789] --addv m1 [v2:1.3.5.45:3300,v1:1.3.5.45:6789] --addv m2 [v2:1.3.5.46:3300,v1:1.3.5.46:6789] /var/log/monmap.bin

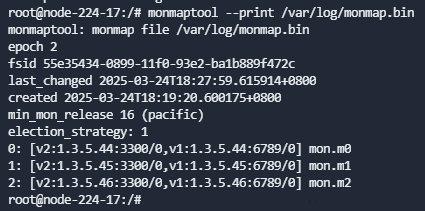
- 查看新配置是否准确:
monmaptool --print /var/log/monmap.bin
- 将新的mon配置复制到其他ceph-mon节点下。
如果是在容器中操作上述步骤,需要将/var/log/monmap.bin从容器中复制到主机:
kubectl cp {pod}:{path of monmap.bin} /root/monmap.bin
scp /root/monmap.bin 192.168.224.45:/root
scp /root/monmap.bin 192.168.224.46:/root

单节点环境不需要复制monmap到主机上,但要注意后续导入新monmap时要在容器中执行。
- 停止ceph集群的服务
集群中每个ceph节点,运行如下命令,停止ceph服务。
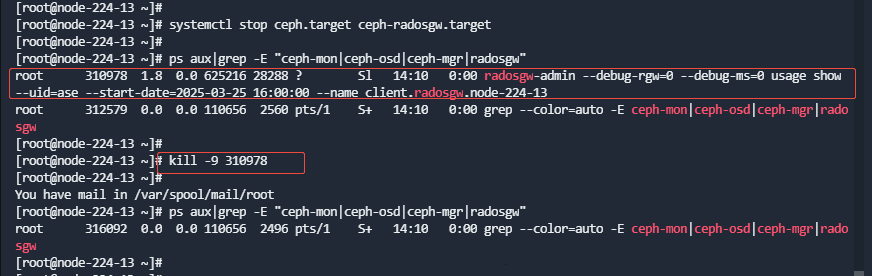
systemctl stop ceph.target ceph-radosgw.target
使用命令如下命令检查是否还有ceph进程未结束:
ps aux|grep -E "ceph-mon|ceph-osd|ceph-mgr|radosgw"
如果有未结束的ceph进程,执行kill -9,强制结束。
- 修改ceph配置文件
- 修改每个节点
/etc/ceph/ceph.conf配置文件,将原来的内部IP改为新的内部IP地址。
sed -i "s/原内部IP/新内部IP/g" /etc/ceph/ceph.conf
多节点集群命令示例:
sed -i "s/1.3.5.38/1.3.5.44/g; s/1.3.5.36/1.3.5.45/g; s/1.3.5.37/1.3.5.46/g" /etc/ceph/ceph.conf
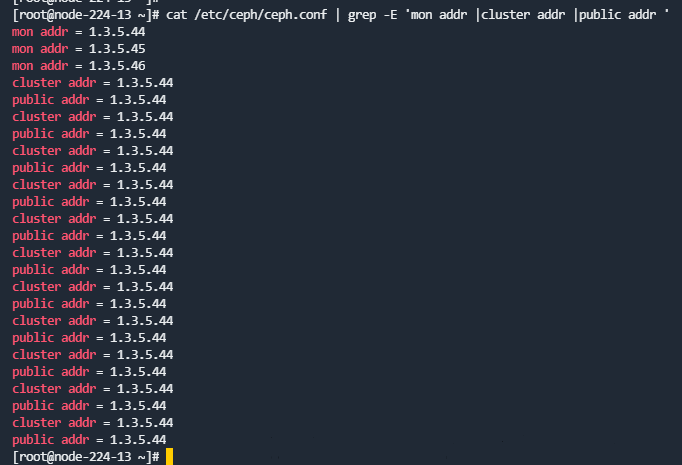
修改完成后使用命令cat /etc/ceph/ceph.conf |grep 原内部IP, 确认是否替换完成。

- 确认字段修改完全
IP修改主要涉及如下字段:
- mon.mX的mon addr
- osd.X的cluster addr和public addr
运行如下命令检查:
cat /etc/ceph/ceph.conf | grep -E 'mon addr |cluster addr |public addr'
- ceph-mon节点导入新的配置
在每个ceph-mon节点为所有mon导入新的monmap.bin配置,多个mon需分多次导入,一次只能导入一个mon。
注意:ceph-mon命令在主机上也可以执行,如果monmap.bin已经在各个主机上,可以在主机上运行,如果还在容器里(单节点环境),需要去容器里面执行。
ceph-mon -i {monid名称} --inject-monmap monmap.bin
- 启动ceph集群的服务
每个节点执行如下命令启动ceph集群的服务。
systemctl start ceph.target ceph-radosgw.target
运行如下命令查看是否启动:
systemctl status ceph.target ceph-radosgw.target

- 检查集群状态
在proton-eceph-node-agent容器中运行ceph -s查看集群状态,3节点集群约需要等待一分钟左右恢复健康。
若ceph -s报错,请检查网络配置是否正确,ceph.conf配置文件,ceph相关服务进程是否启动。
第2步 修改数据库
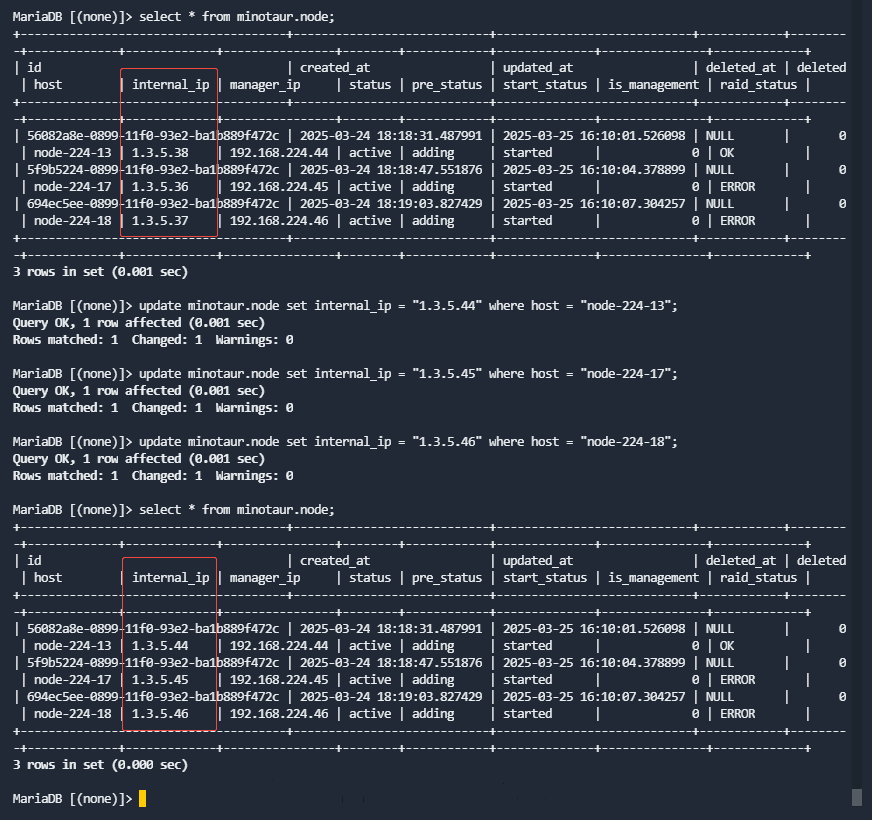
进入minotaur数据库,将node表中internal_ip修改为新的内部IP地址,SQL命令如下:
update minotaur.node set internal_ip = "新的IP地址" where host = "对应hostname";
运行如下SQL命令确认已经修改正确:
select * from minotaur.node;
第3步 修改minotaur.conf配置文件
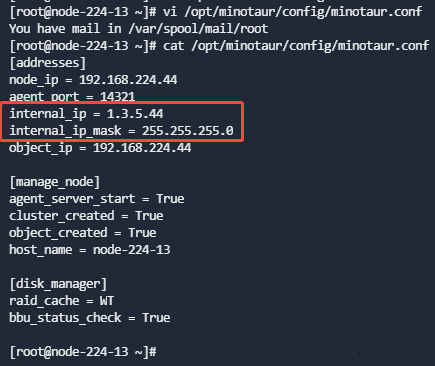
- 每个节点修改
/opt/minotaur/config/minotaur.conf配置文件,将internal_ip 和 internal_ip_mask修改成新的内部IP地址和子网掩码。
说明:ECeph 7.13.0及之后的版本去除了子网掩码设置。
- 运行如下命令,重启每个节点的eceph-config-agent服务。
systemctl restart eceph-config-agent
第4步 重启容器服务
运行如下命令重启proton-eceph相关容器服务。
kubectl get po -A | grep proton-eceph | awk '{print$2}' |xargs -i kubectl delete po/{} -ndefault

第5步 修改内部VIP(可选)
如果在3.3中更新过eceph_ivip或集群中没有eceph_ivip,该步骤可跳过。
所有节点进行/etc/keepalived/keepalived.conf中eceph_ivip部分的内部IP和VIP进行修改。
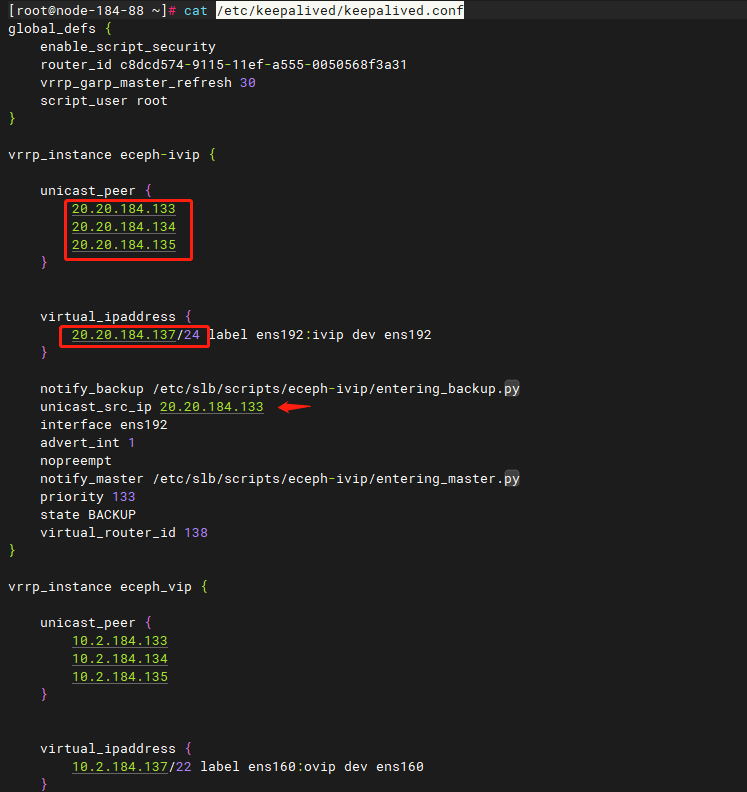
修改后,运行systemctl restart keepalived重启keepalived,然后检查vip配置,注意只有一个节点上运行了ivip标签的vip。
第6步 修改SLB-Nginx转发配置
ECeph通过SLB-Nginx对外提供对象存储访问接口:10001和10002。当融合部署有两个网段时,此处使用的是内部IP。
- 进入集群每个节点
/usr/local/slb-nginx/conf.d/http/目录下,查看eceph_10001.conf和eceph_10002.conf配置文件。
- 重新加载SLB-Nginx配置,在修改了配置的每个节点运行如下命令:
systemctl reload slb-nginx
- 测试对象上传下载,登陆ECeph租户管理页面http://{ip}:8005,使用租户登陆,进入对象管理页面。测试上传下载文件。其中用户名为租户名称,密码为创建租户时设置的密码。
3.5 存储配置相关修改
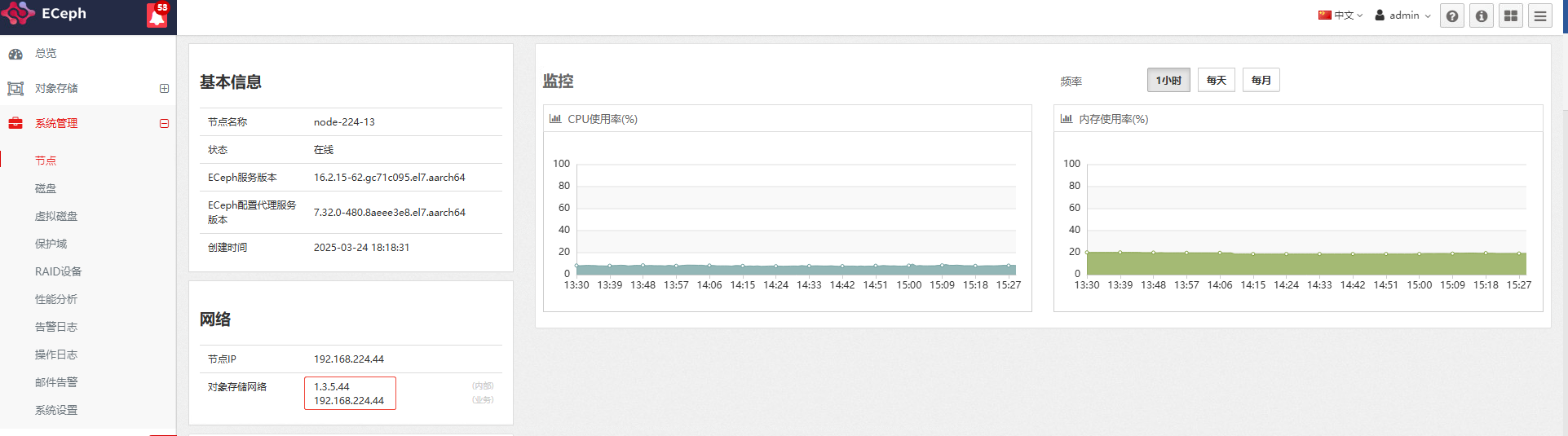
第1步 查看ECeph集群管理页面显示
登录ECeph管理页面http://{ip}:8003,到【系统管理】-【节点】页面中,点击节点名进入详细信息,查看网络中内部IP是否显示正确。
第2步 cms-release-config-ossgateway配置修改
其一master节点执行:
- 执行命令查询:
kubectl -nanyshare get secret cms-release-config-ossgateway -o yaml
- 执行命令将上一步查询返回的default.yaml部分进行base64解码并重定向到一个文件:
echo "xxxxx" |base64 -d > default.yaml
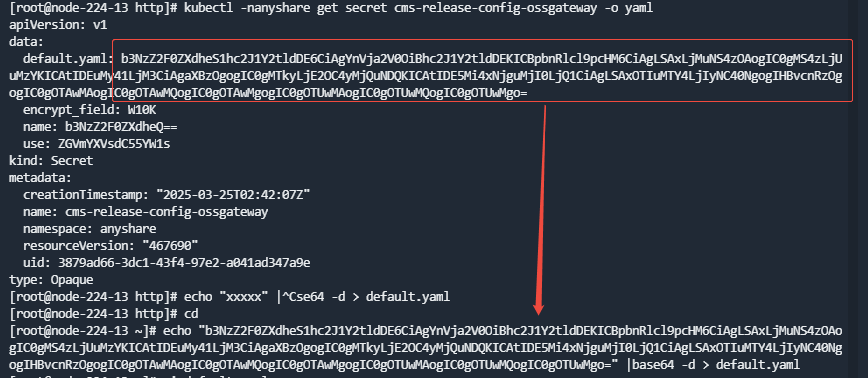
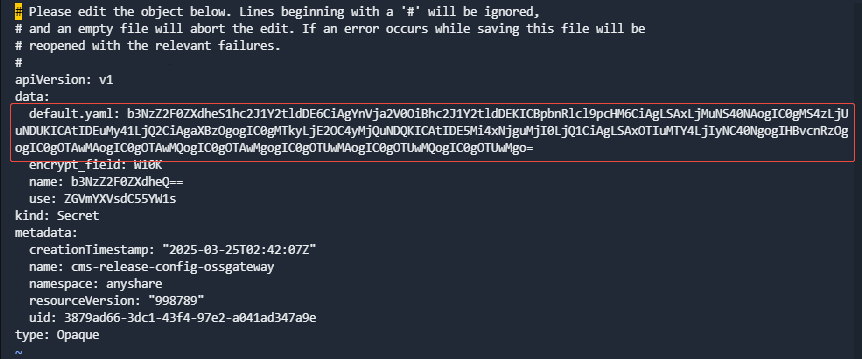
- 修改default.yaml,将所有inter_ips中的IP修改为新的内部IP。

- 将default.yaml重新base64编码:
cat default.yaml | base64 > default.yaml.base64

- 将再次Base64编码的结果替换至secret cms-release-config-ossgateway中原始部分(手动重组,注意中间不要有换行):
kubectl -nanyshare edit secret cms-release-config-ossgateway
第3步 OSSGateway配置更新
- 调用如下接口设置内部IP:
curl -X PUT http://`kubectl get svc -n anyshare|grep deploy-service|awk '{print $3}'`:9703/api/deploy-manager/v1/containerized/upmulti-instance-service/OSSGatewayService/
说明:无论接口是否报错,均进行下一步检测配置是否成功

- 内部IP设置检查
- 查看redis中内部地址配置是否正确。
运行如下命令获取所有存储的key:
kubectl exec -c redis proton-redis-proton-redis-0 -n resource -- redis-cli --user root --pass eisoo.com123 -n 0 keys_new /ossgw/*
逐个查看所有存储key下的具体value:
kubectl exec -c redis proton-redis-proton-redis-0 -n resource -- redis-cli --user root --pass eisoo.com123 -n 0 GET {key}
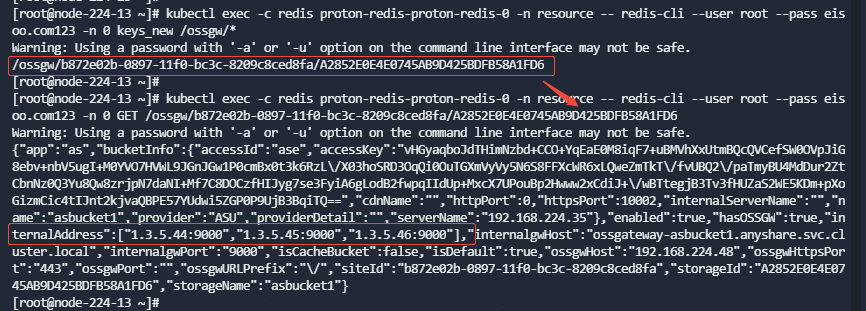
- 查看ossgateway-{bucket}的svc的endpoints配置是否正确。

第4步 修改存储连接配置
进入部署控制台,对象存储页面,查看存储连接配置。若内部服务器地址使用的是原ECeph内部 VIP或内部IP,此处需要改为新内部VIP或内部IP。若未配置内部服务器地址则不需要修改(下图示例为未配置)。
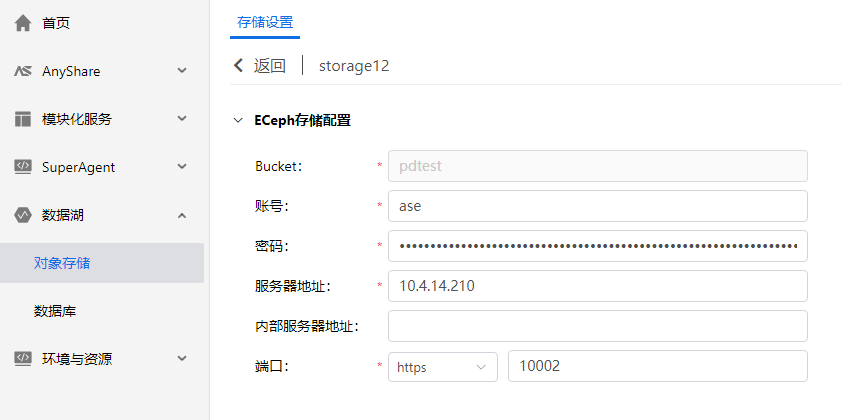
4 1个网段部署,修改业务IP
4.1 修改流程
第1步 按照第2章修改业务IP
第2步 按照第3章修改内部IP