场景背景
云计算时代,云服务提供方和使用方之间都会签订服务的SLA协议。SLA是服务提供商与客户之间定义的正式承诺,也是服务提供方对服务可用性的一个保证。但是,客户和服务提供方怎么确定服务是否满足SLA呢?所以,有必要对服务进行SLO建模,通过SLI指标来衡量服务质量水平,基于此来判断服务质量是否满足SLA要求。
爱数IT运维团队负责提供网络服务、海量服务、机房服务,在提供服务期间,他们需要保证各个服务质量满足SLA协议,即服务可用性满足SLA预定目标。根据海量服务层级组织关系。主要分为一级组织和二级组织:一级组织分别为:服务线,产品线,销售线,数字化线,研发线,二级组织:由研发线的一级组织管理各个二级组织分别为:AnyRobot研发线,AnyBackup研发线,AnyShare研发线,AnyDATA研发线,技术研究院。
场景方案
► 云基础设施场景设计方案
面向应用系统建模,按照关键IT服务进行拆分建模,如下所示: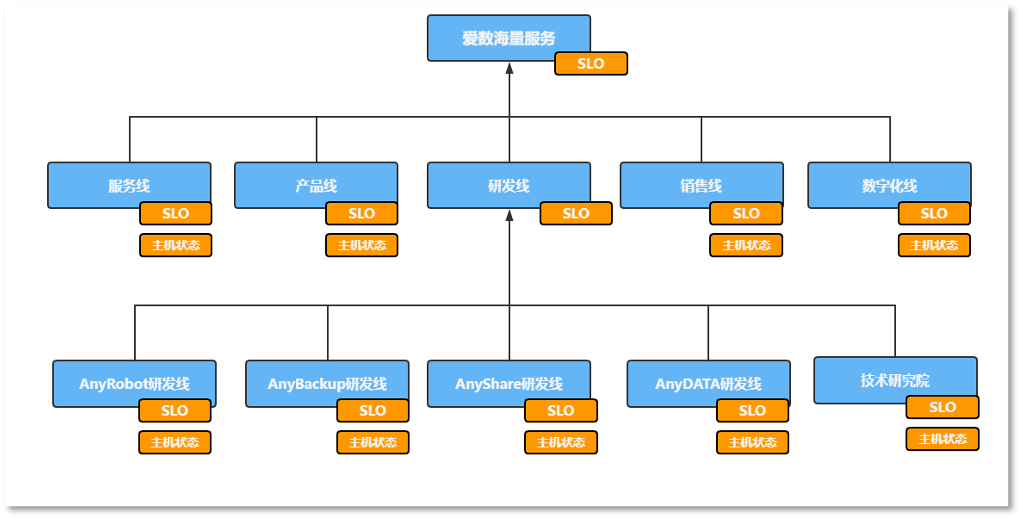
► 云基础设施场景实施方案
- 通过采集器采集不同一级组织与二级组织的主机运行日志
- 每个主机通过其SSH端口状态数据判断是否可用
- 通过场景设计模型建立起组织之间的依赖关系
场景价值
1)对于服务提供方,当服务剩余错误预算足够多时,就可以通过发布新功能以提高产品的竞争力,当错剩余误预算不足时,就需要考虑放慢或者暂停新功能的开发,重新稳定系统以提升服务质量。
2)对于运维人员,当服务质量不能达成工作目标时(SLO未达成),可快速定位影响服务质量的源头(子服务),及时排除故障以免造成更大损失。
3)对于服务使用方,可实时监控服务质量好坏,一旦发现服务质量不满足SLA要求,则可要求服务提供方进行整改。
场景建模
► 概念术语
|
概念 |
英文 |
说明 |
|
服务质量协议 |
SLA(service-level agreement) |
服务质量协议,指服务与用户之间的一个明确的或者不明确的协议,描述了在达到或者没有达到SLO之后的后果。这些后果可以是财务方面的退款或者惩罚,也可能是其他类型的。SLA用一个简单的公式来描述:SLA=违反SLO+后果。 |
|
服务健康分数 |
Service Health Score |
反映服务健康状况的好坏,数值越大说明服务健康状况越好。服务健康分数由KPI可用性、依赖服务的健康分数加权计算得到。 |
|
服务质量指标 |
SLI(service-level indicator) |
服务质量指标,衡量服务在一段时间内的服务健康状况。如:服务在一周内有30分钟服务健康分数为严重,则SLI=1 - (30min/10080min)=99.7% |
|
服务质量目标 |
SLO(service-level objective) |
服务质量目标,服务某个SLI的目标值或者目标范围,SLO定义的是SLI≥目标值。 |
|
服务 |
Service |
服务是IT基础设施的逻辑映射,服务的定义很广泛,如: 一个应用程序或一组应用程序 基础架构层(例如Web,数据库或网络层) 单个进程,例如在主机上运行的应用程序的一个实例 具体来说是由服务对应的数据组成。 |
|
剩余错误预算 |
Left Error Budget |
为了达到SLO目标最大能容忍的出错程度,单位和SLI指标单位一致 剩余错误预算=(100%-SLO) - (100%-SLI) = SLI -SLO 可以为负值(超过了最大容忍错误预算,即未达成SLO目标) |
|
服务 |
Service |
服务是基础设施、IT系统等应用程序的逻辑映射。 |
|
实体 |
Entity |
实体是基础设施、IT系统等应用程序的抽象最小单元,可对服务进行更加细粒度地描述。 如多节点AnyRobot集群是一个服务,则可定义每个主机节点就是组成该服务的实体。 |
|
KPI |
KPI (key performance indicator) |
关键绩效指标(Key Performance Indicator),反映服务健康状况的指标,如CPU利用率、内存使用率、响应时间等。 |
|
KPI可用性 |
KPI Availability |
KPI可设置阈值条件来计算KPI的可用性,可设置三个阈值条件, 对应可用性为正常(100分)、警告(60分)和严重(0分) |
|
依赖配置 |
Dependencies |
服务由KPI和依赖项组成,依赖项包括实体依赖和服务依赖,两者二选一 |
|
静态阈值 |
Static Threshold |
KPI可设定阈值区间,以衡量其严重性。 静态阈值:阈值区间为常量,配置好后不会变化。 |
|
动态阈值 |
Dynamic Threshold |
KPI可设定阈值区间,以衡量其严重性。 动态阈值:阈值区间基于历史数据规律动态调整,适合业务数据正常波动的情况。 |
► 服务健康度与SLO建模
服务健康度是通过对影响报表系统的各项服务进行健康程度评估,在报表系统出现业务故障时,管理员可以通过观察服务的健康度评分,初步判断故障原因。也可以通过服务的SLO(服务质量目标,服务某个SLI的目标值或者目标范围,SLO的定义是SLI≥目标值。)来判断服务在某一时间内是否满足服务质量的目标。
通过采集各服务相关的日志,包括服务的运行日志,服务运行状态,服务所在服务器的性能日志等,提取判断该服务运行状态的关键指标,并根据这些关键指标值是否处于正常范围阈值内,判断服务是否处于健康状态。
|
监控对象 |
服务健康度与SLO明细 |
|
爱数海量服务 |
爱数海量服务的正常运行,主要是依赖服务线,产品线,研发线,销售线,数字化线等服务的健康状态。任意健康度为0,则整个服务的健康度在某一时间内会有所下降。同时SLO也会有所下降 |
|
服务线 |
服务线服务依赖主机,SLO由健康度的状态定义,其健康度由以下关键指标组成:主机状态 |
|
产品线 |
服务线服务依赖主机,SLO由健康度的状态定义,其健康度由以下关键指标组成:主机状态 |
|
销售线 |
服务线服务依赖主机,SLO由健康度的状态定义,其健康度由以下关键指标组成:主机状态 |
|
数字化线 |
服务线服务依赖主机,SLO由健康度的状态定义,其健康度由以下关键指标组成:主机状态 |
|
研发线 |
研发线线服务依赖AnyRobot研发线,AnyBackup研发线,AnyShare研发线,AnyDATA研发线,技术研究院等子服务的健康状态。任意健康度为0,则整个服务的健康度在某一时间内会有所下降。同时SLO也会有所下降。 |
|
AnyRobot研发线 |
AnyRobot研发线服务依赖主机,SLO由健康度的状态定义,其健康度由以下关键指标组成:主机状态 |
|
AnyBackup研发线 |
AnyBackup研发线服务依赖主机,SLO由健康度的状态定义,其健康度由以下关键指标组成:主机状态 |
|
AnyShare研发线 |
AnyShare研发线服务依赖主机,SLO由健康度的状态定义,其健康度由以下关键指标组成:主机状态 |
|
AnyDATA研发线 |
AnyDATA研发线服务依赖主机,SLO由健康度的状态定义,其健康度由以下关键指标组成:主机状态 |
|
技术研究院 |
技术研究院服务依赖主机,SLO由健康度的状态定义,其健康度由以下关键指标组成:主机状态 |
场景实施
► 数据准备
_61.png) 说明:您可自行准备您关注的数据文件进行导入,也可联系相关技术支持人员获取“日志样例”文件进行上传。需注意日志文件的导入时间需要根据实际情况进行修改,如您在2022/11/22导入此文件,需将其时间修改为2022/11/22。
说明:您可自行准备您关注的数据文件进行导入,也可联系相关技术支持人员获取“日志样例”文件进行上传。需注意日志文件的导入时间需要根据实际情况进行修改,如您在2022/11/22导入此文件,需将其时间修改为2022/11/22。
进入数据管理>数据源>本地上传,点击新建,选择已准备好的数据文件,本文以获取到的日志样例为例,上传样例后,选择日志类型anyrobot_slo_vm。
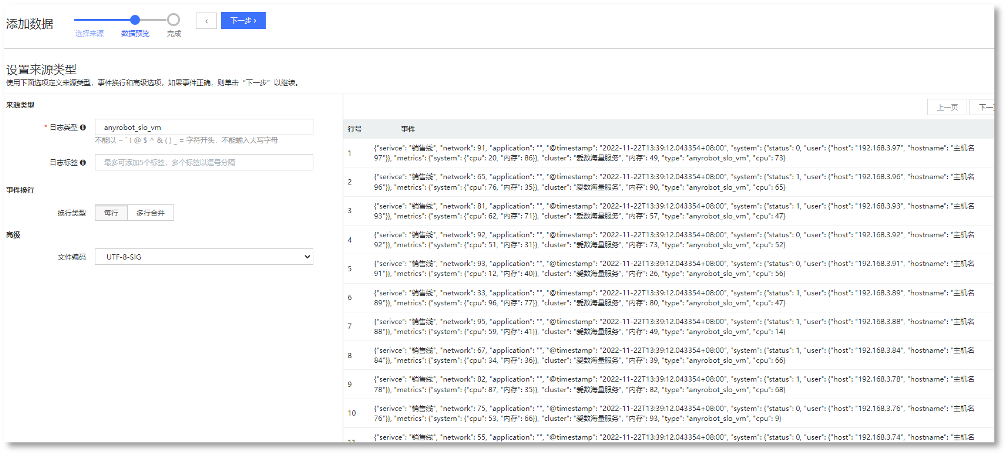
► 日志规划
VM云基础设施场景业务日志根据日志类型划分:anyrobot_slo_vm。
► 服务健康度配置
|
监控对象 |
健康度定义 |
关键指标 |
严重性定义 |
权重分数 |
可用性配置 |
|
爱数海量服务 |
健康分数:服务线、产品线、研发线、销售线、数字化线 |
各个服务的健康度分数 |
无 |
25% |
严重:min-30 |
|
服务线 |
健康分数:主机可用状态 |
最近5分钟主机的可用状态 |
严重:0-0.6 |
100% |
严重:min-30 |
|
产品线 |
健康分数:主机可用状态 |
最近5分钟主机的可用状态 |
严重:0-0.6 |
100% |
严重:min-30 |
|
销售线 |
健康分数:主机可用状态 |
最近5分钟主机的可用状态 |
严重:0-0.6 |
100% |
严重:min-30 |
|
数字化线 |
健康分数:主机可用状态 |
最近5分钟主机的可用状态 |
严重:0-0.6 |
100% |
严重:min-30 |
|
研发线 |
健康分数: |
各个子服务的健康度分数 |
无 |
25% |
严重:min-30 |
|
AnyRobot研发线 |
健康分数:主机可用状态 |
最近5分钟主机的可用状态 |
严重:0-0.6 |
100% |
严重:min-30 |
|
AnyBackup研发线 |
健康分数:主机可用状态 |
最近5分钟主机的可用状态 |
严重:0-0.6 |
100% |
严重:min-30 |
|
AnyShare研发线 |
健康分数:主机可用状态 |
最近5分钟主机的可用状态 |
严重:0-0.6 |
100% |
严重:min-30 |
|
AnyDATA研发线 |
健康分数:主机可用状态 |
最近5分钟主机的可用状态 |
严重:0-0.6 |
100% |
严重:min-30 |
|
技术研究院 |
健康分数:主机可用状态 |
最近5分钟主机的可用状态 |
严重:0-0.6 |
100% |
严重:min-30 |
► SLO配置
|
监控对象 |
SLO目标配置 |
错误预算阈值 |
|
爱数海量服务 |
7天:99.90% |
严重:0-30% |
|
服务线 |
7天:99.90% |
严重:0-30% |
|
产品线 |
7天:99.90% |
严重:0-30% |
|
销售线 |
7天:99.90% |
严重:0-30% |
|
数字化线 |
7天:99.90% |
严重:0-30% |
|
研发线 |
7天:99.90% |
严重:0-30% |
|
AnyRobot研发线 |
7天:99.90% |
严重:0-30% |
|
AnyBackup研发线 |
7天:99.90% |
严重:0-30% |
|
AnyShare研发线 |
7天:99.90% |
严重:0-30% |
|
AnyDATA研发线 |
7天:99.90% |
严重:0-30% |
|
技术研究院 |
7天:99.90% |
严重:0-30% |
► 服务配置
由于该场景是由VM组织架构来分为一级组织和二级组织,创建的先后顺序为二级组织再到一级组织。这里由二级组织【AnyDATA研发线】为例,其它的二级组织以此类推。
1. 定义SLO
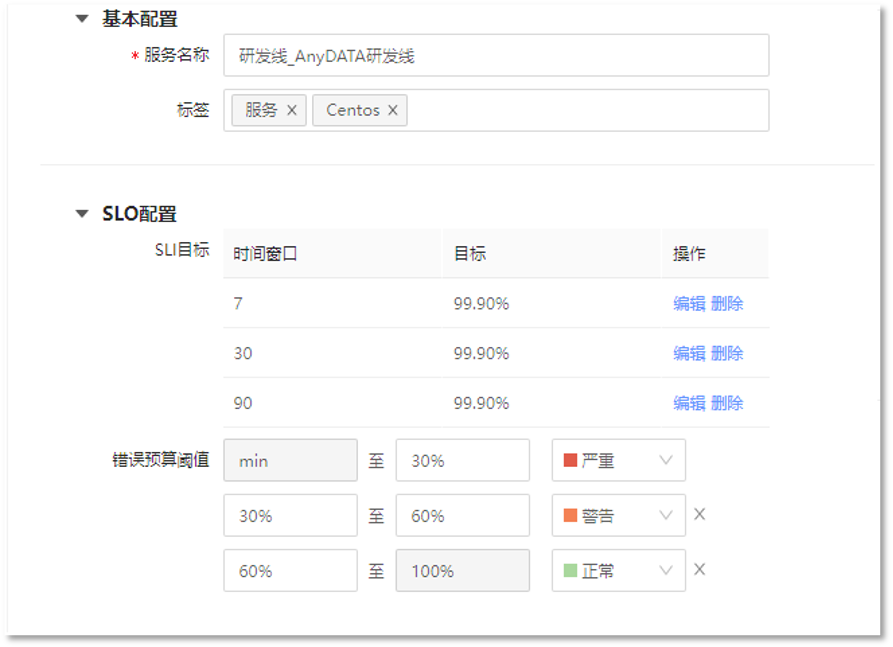
2. 定义依赖类型,选择拆分字段与实体显示名称,如下所示:
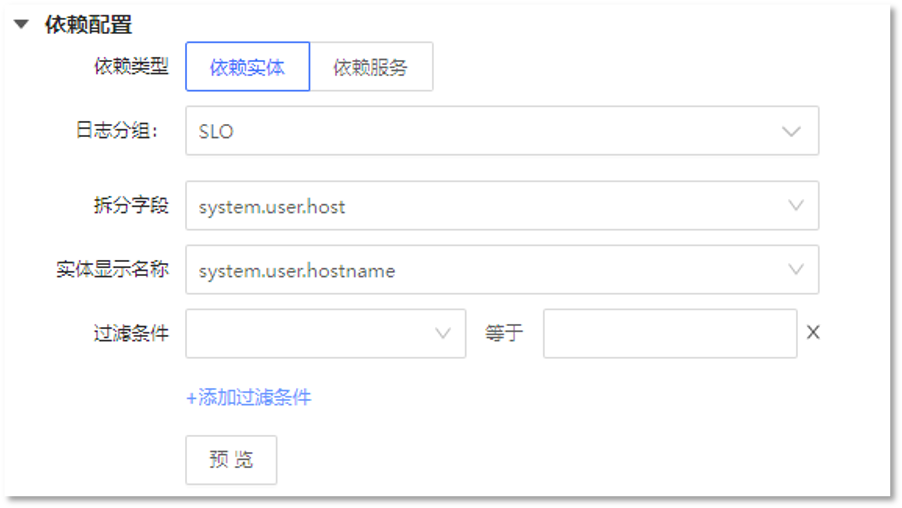
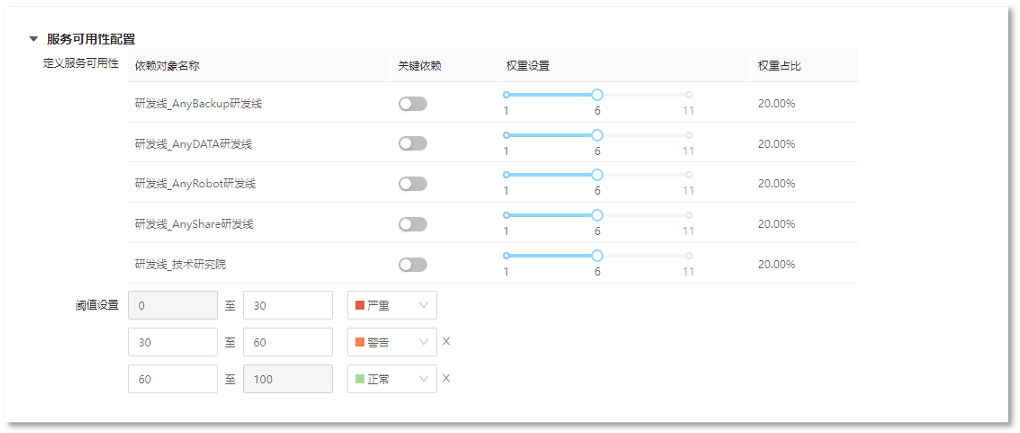
3. 定义服务可用性配置 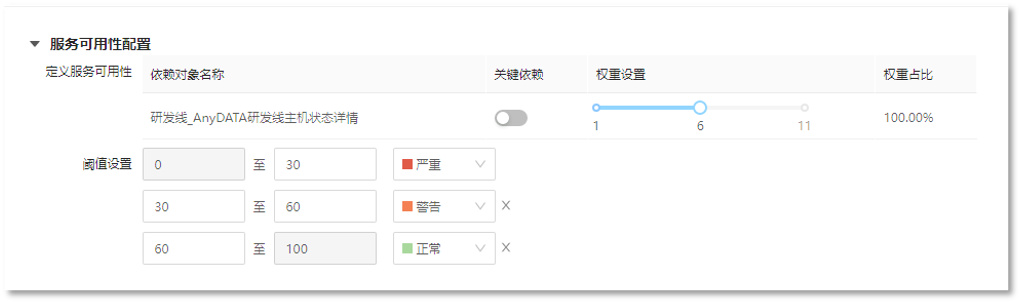
4. KPI对监控对象的指标监控
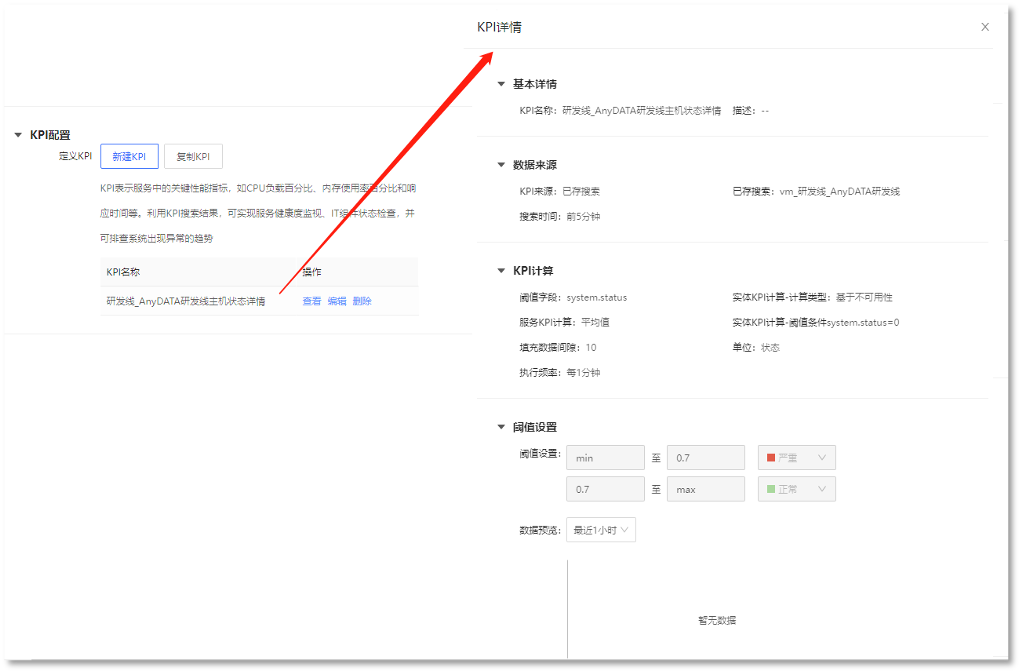
一级级组织【研发线】为例,其它的一级组织创建与二级组织一样以此类推
5. 定义SLO
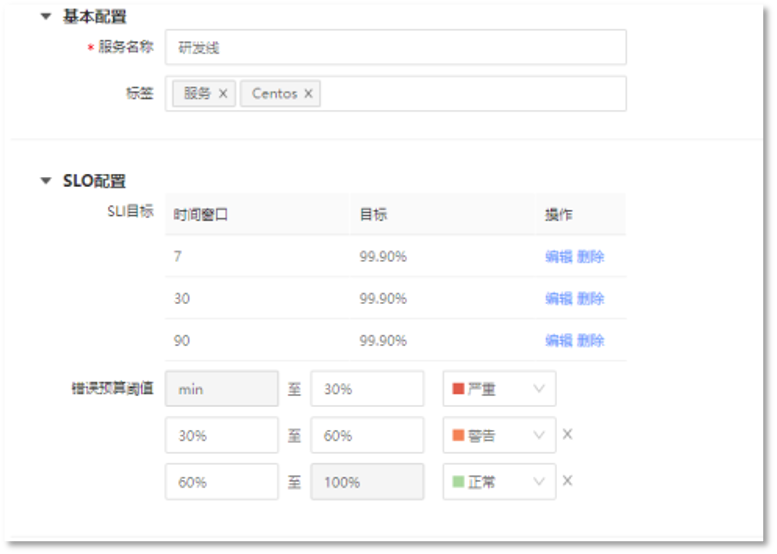
6. 定义依赖类型,选择依赖服务

7. 定义服务可用性配置
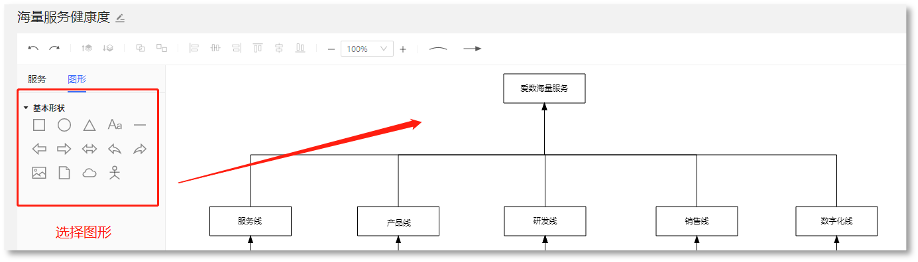
► 业务全景图配置
1. 定义业务流程
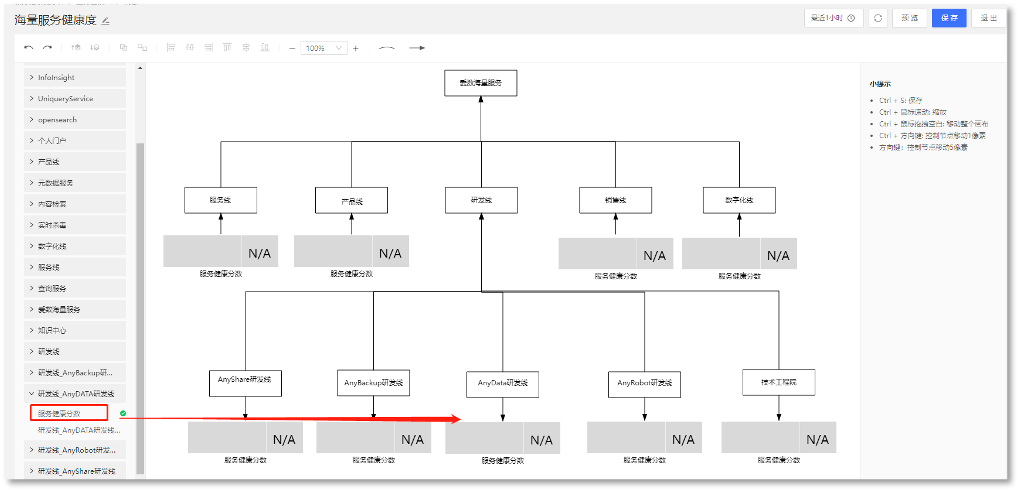
2. 关联业务的健康度,选择KPI,如下所示:
场景分析
► 服务健康度分析
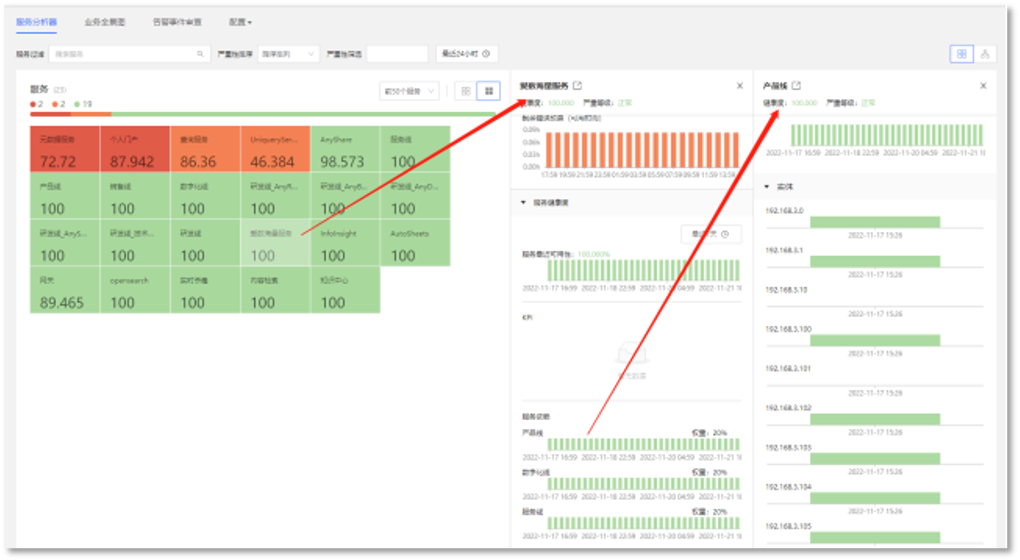
VMware虚拟化平台在爱数统称为“海量平台”。“海量平台”的VMware vSphere由运维部统一管理,各个研发线根据需要申请使用。可以理解为,运维部向各个研发线提供云主机服务。运维部作为云主机服务的提供者,需要向各个研发线保证云主机服务的可用性。同时,运维部作为云主机服务的维护者,当VMware出现故障时,也需要第一时间知晓,并评估出故障影响范围。下面将展示如何使用“服务健康度”功能对VMware集群进行云主机服务的SLO监控和服务健康度分析。
► SLO分析
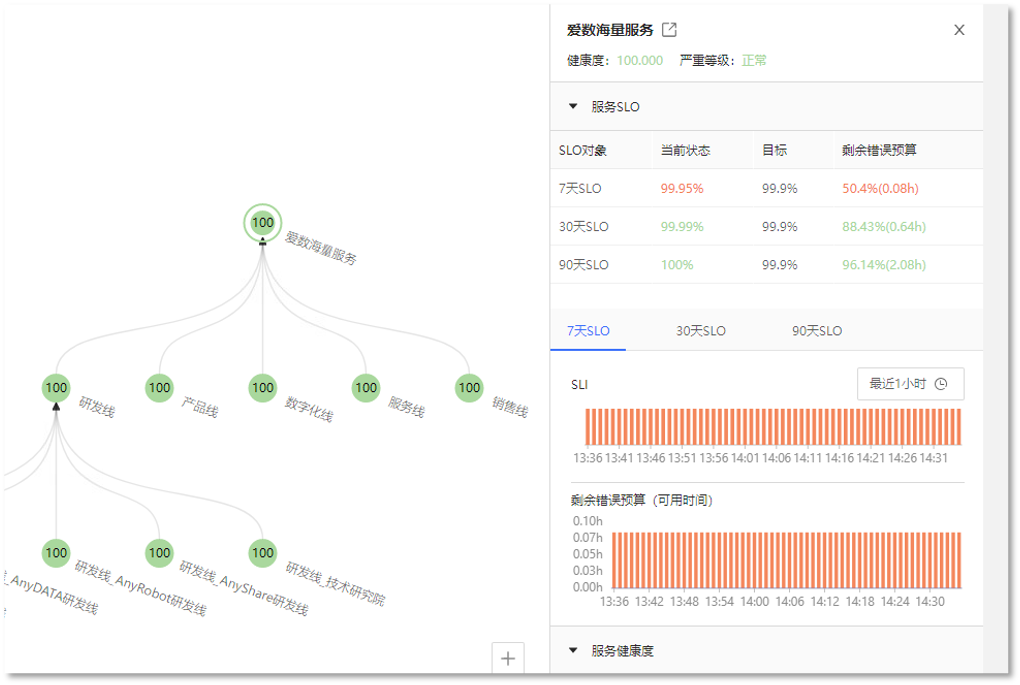
服务健康度分析功能模块中除了可以对VMware虚拟化平台的服务健康度分析,还可以分析展示服务的SLO。当我们想要查看某个服务的SLO时,可以直接在服务分析器中选择对应服务的节点。比如现在我们想要查看“爱数海量服务”整体的SLO,我们可以在服务分析器中点击“爱数海量服务”这个节点,右侧服务SLO这一栏就可以“爱数海量服务”的SLO监控。在上面这个列表中,我们可以看到“爱数海量服务”的7天、30天、90天的SLO目标、当前状态,以及剩余错误预算。下面的三个选项卡,可以分别展示7天、30天、90天SLO的SLI和剩余错误预算的历史值。类似的,当我们想要了解某一个研发线海量服务的SLO情况时,只需要点击这个服务节点,就可以再右侧清晰的看到具体信息。基于不同研发线海量服务的SLO分析,我们就可以很好的评估运维部向各个研发线提供的云主机服务是否达到了预定的SLO目标。
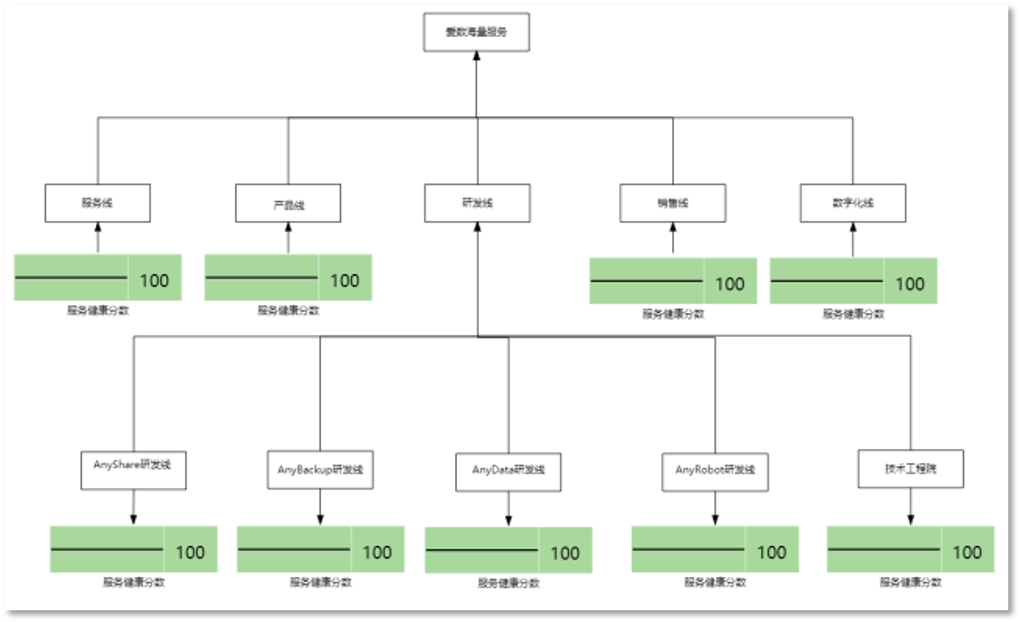
► 业务全景图分析
我们打开服务健康度分析里面的“海量服务SLO”业务全景图。业务全景图是一个业务对象的全局服务视图,可以帮助用户从全局化的角度了解业务系统全貌和各业务服务之间的依赖关系。在“海量服务健康度”业务全景图中,我们是把组织单位作为服务对象进行分析。比如第二层,服务线、产品线、研发线、销售线、数字化线,都是一级组织;AnyShare研发线、AnyBackup研发线、AnyData研发线、AnyRobot研发线、技术工程院属于研发线下面的二级组织单位。
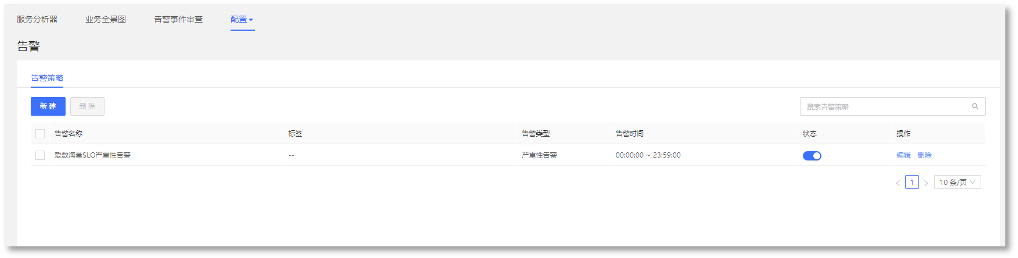
► 告警分析
1. SLO告警配置,设置告警触发条件和告警执行计划,可对指定严重性的SLO进行告警:
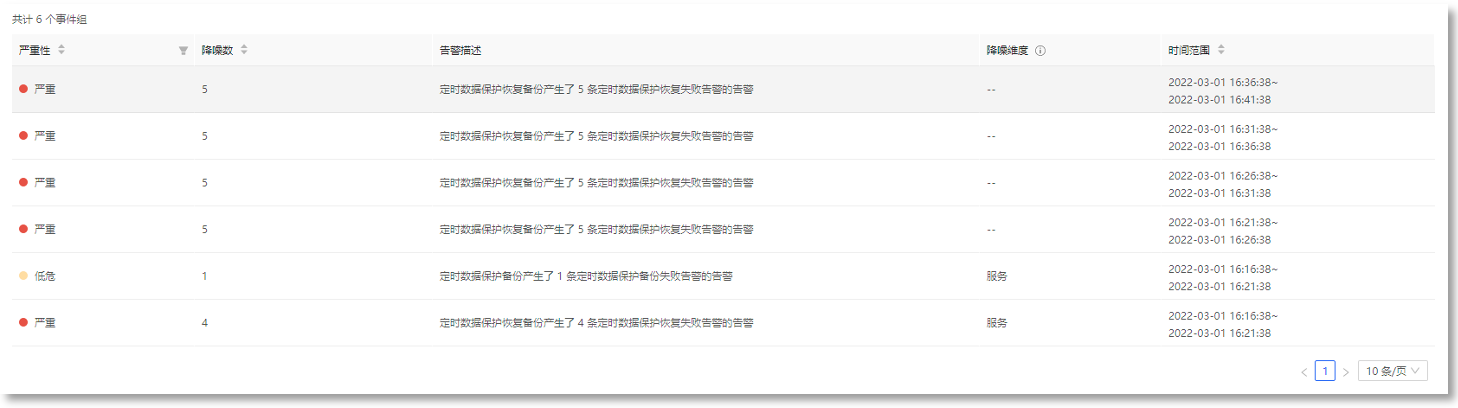
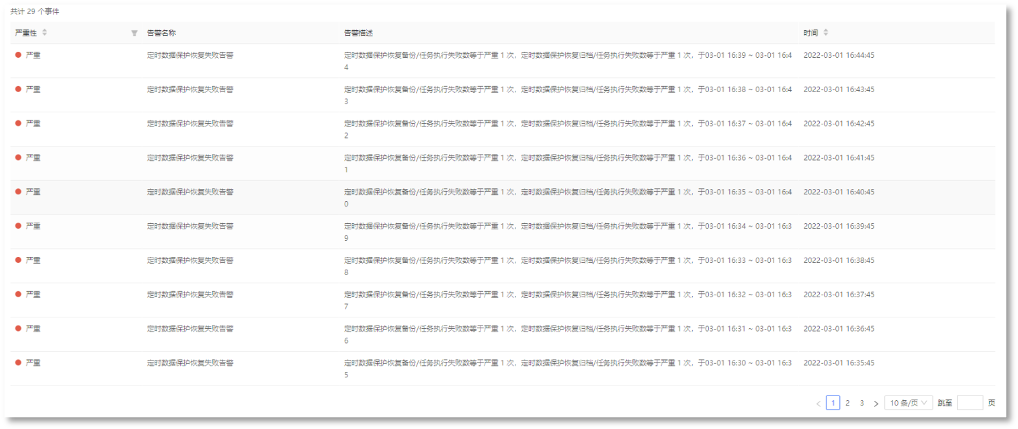
2. SLO告警记录,可查看告警事件详情,快速定位问题,如下所示:
3. KPI告警配置,设置告警触发条件和告警执行计划,可对指定严重性的KPI进行告警:
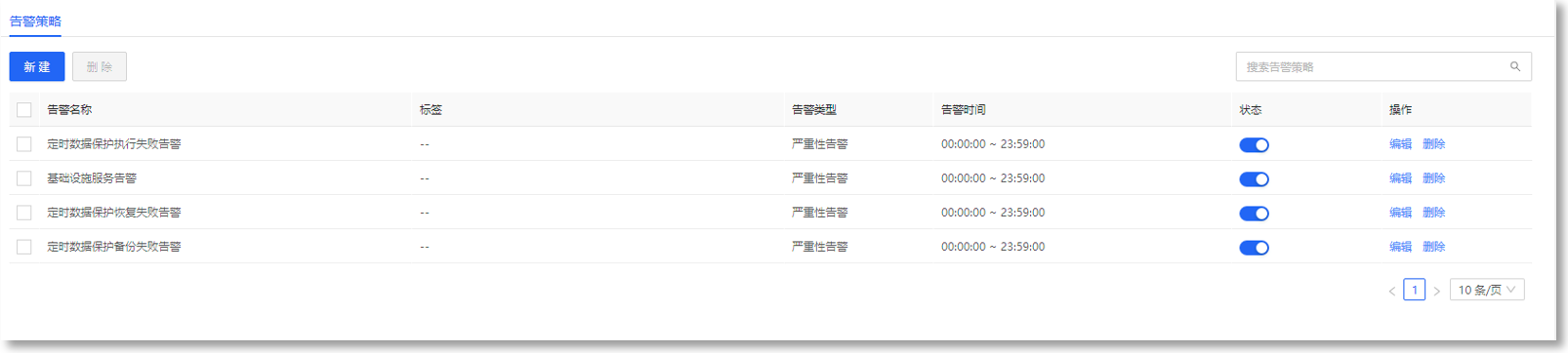
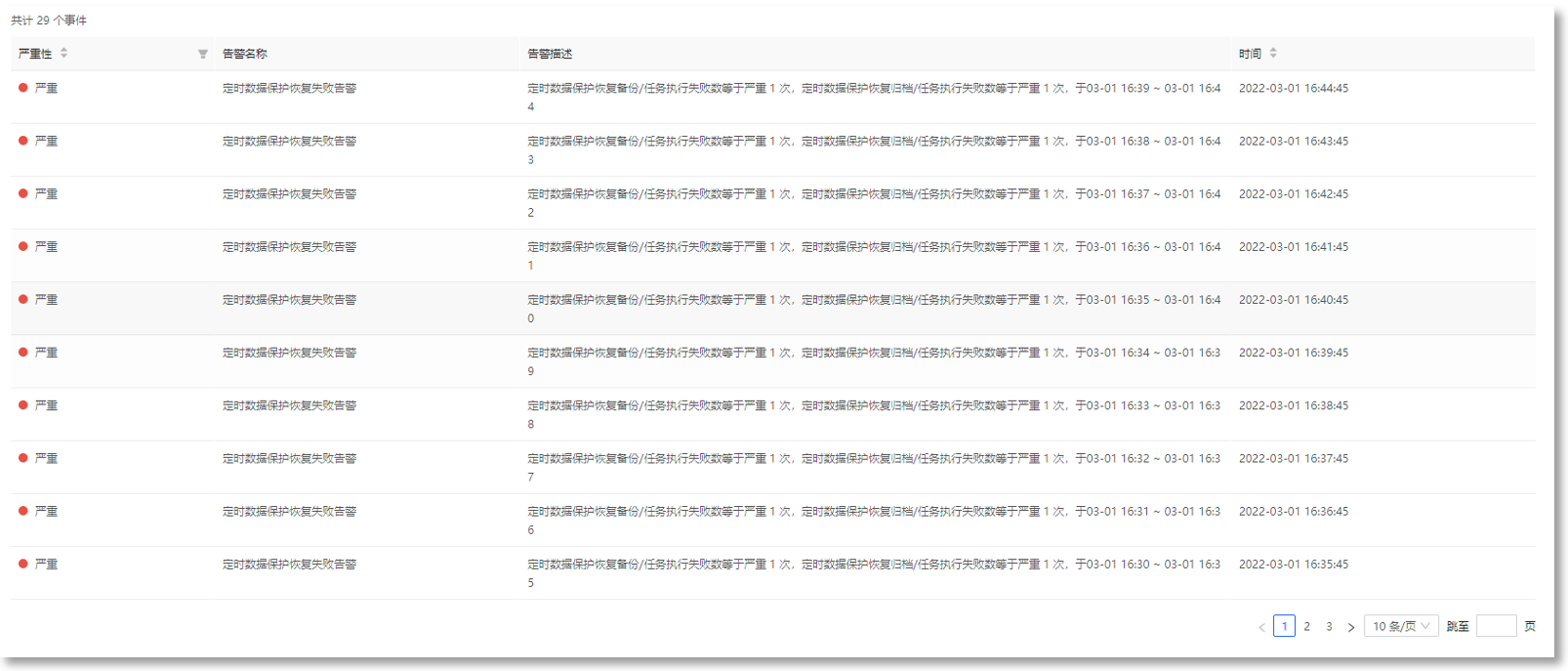
4. KPI告警记录,可查看告警事件详情,快速定位问题:
5. KPI告警降噪,解决无法从大量的告警中提取有价值的信息,实现精准告警: