微服务架构特性描述
➢ 可伸缩特性
OpenSearch自身是一个分布式的系统,节点通常分为Master与Data的角色,数据以分片的方式存储在一个或者多个数据节点上。微服务架构中,OpenSearch实例以容器的方式运行,并有Kubernetes将其调度到运行机器上,因此可对一个OpenSearch集群实现节点的快速增添与删除的操作。
OpenSearch具有完备的可伸缩特性,对于固有的OpenSearch集群,当需要接入的数据量需求变大时,此时可通过增加OpenSearch数据节点支撑变大的数据量,这样OpenSearch集群自身接入数据的能力就有一定的提升,以应对海量数据的场景。当OpenSearch集群需要处理的数据量变小后,通过综合评估判断出少量的OpenSearch数据节点,即可完成变小后的数据规模。此时可选择一定的数据节点,将存储在上面的数据迁移至其他节点,然后下线该OpenSearch节点,缩减OpenSearch集群实例。
微服务架构下的OpenSearch集群具备依据需要处理的数据量的变化,动态调整集群节点的能力:数据量变大时,可快速增加OpenSearch实例;数据量变小时,可快速下架OpenSearch实例。
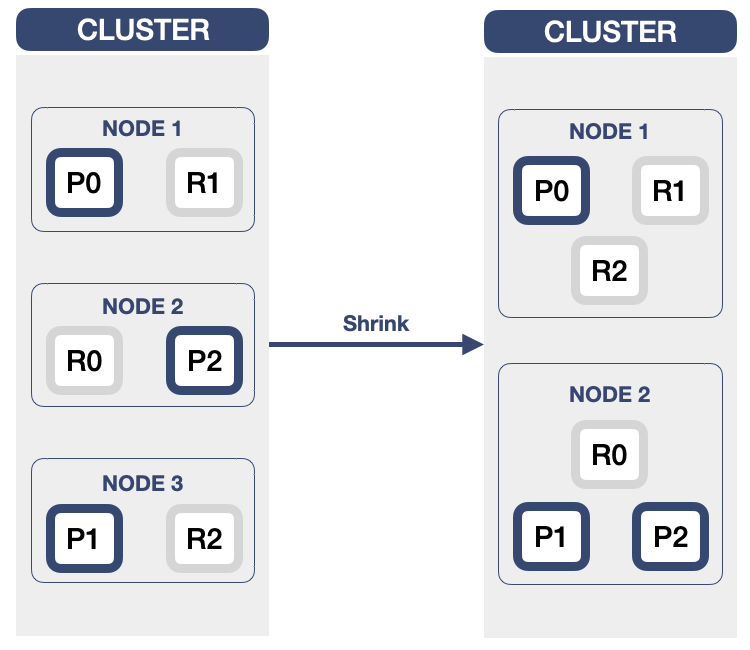
- OpenSearch节点减少:
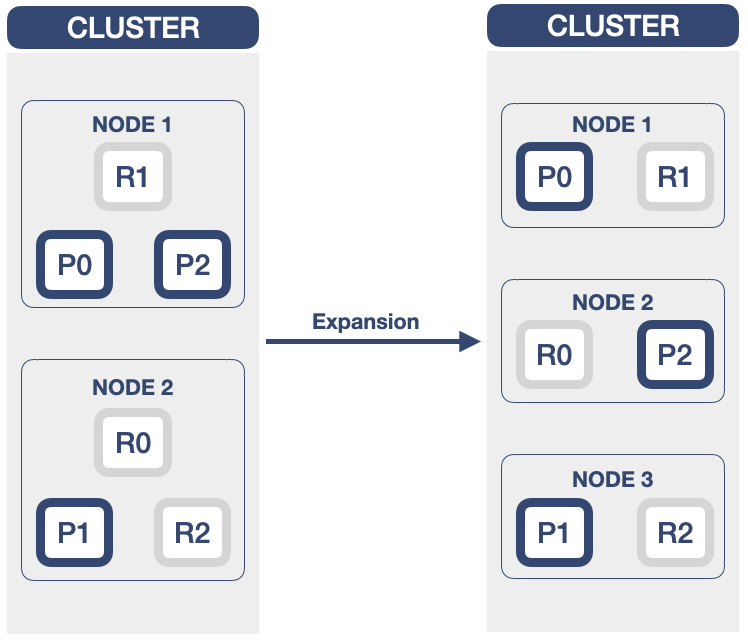
- OpenSearch节点增加:
_61.png) 备注:
备注:
P0~P2:索引的主分片(Primary Shard);
R0~R2:索引的副本分片(Replication Shard)。
➢ 高可用特性
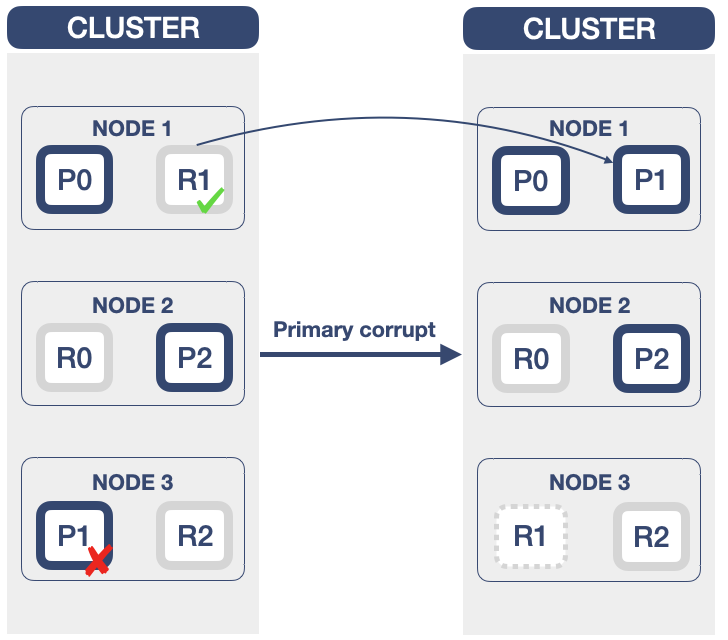
OpenSearch底层存储单元的结构为Index->Shard->Segment,其中最小可执行的存储单位是分片(Shard)。OpenSearch通过引入主分片与副本分片的机制实现高可用特性。OpenSearch集群中当存在数据节点发生故障时,此节点上已存的所有分片包括主分片和副本分片,都将丢失。副本分片丢失时,OpenSearch恢复起来比较容易,本质上直接对此副本分片对应的主分片上执行复制操作即可。但当主分片发生丢失时,索引会变成RED不可用状态,同时OpenSearch集群也会变成RED状态,OpenSearch会从此主分片对应的副本分片中选择一个并将其升级为主分片,然后再复制一个副本分片,这样就确保了整个索引数据的完整性。
因此,OpenSearch设计的主副分片机制实现了稳定的高可用特性,副本数越多OpenSearch集群的容错能力就会越高。
- OpenSearch主分片损坏:
备注:
P0~P2:索引的主分片(Primary Shard);
R0~R2:索引的副本分片(Replication Shard)。
Hot-Warm分层架构描述
➢ Hot-Warm分层架构
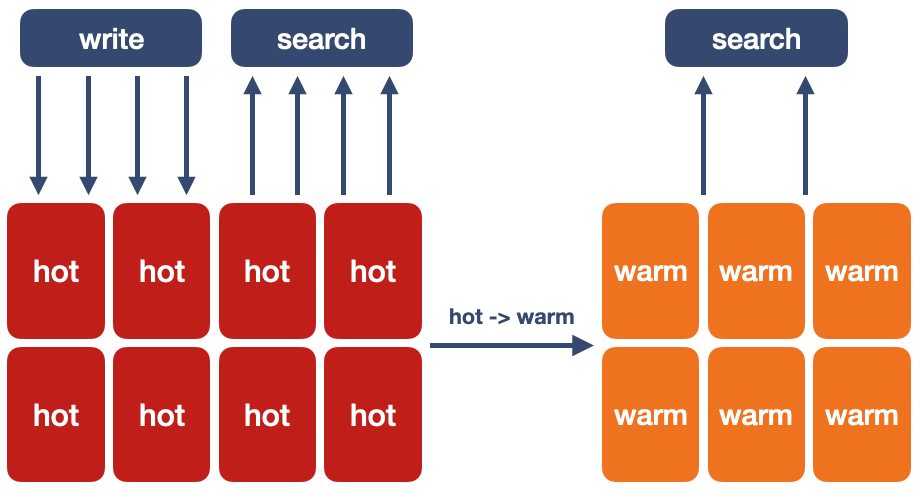
日志数据天生带有时间属性,因此也被称之为时序数据。针对日志大数据的场景,OpenSearch通过引入时间索引与Hot-Warm分层的架构来处理这类时序数据。Hot-Warm分层架构针对的是带有时间属性的数据,抛开时间则毫无意义。
Hot-Warm架构的应用模型为:数据首先写入Hot节点,这类节点支持数据的写入与频繁的查询操作。当对应的索引不再有数据的写入且也不再有频繁的查询操作后,这些索引的数据会被迁移至Warm节点,此时Warm节点只会有低频的查询操作。最后当这类数据没有写入也没有查询操作时,则可对这类数据进行归档处理。
➢ 数据分级存储
- 原理介绍
AnyRobot存储引擎OpenSearch每个数据节点都可以设置自身的属性(attr),比如:Hot、Warm、Cold等;通过属性设置在逻辑上对数据节点做到了分类。因为日志带有明确的时间属性,对数据实行分级存储的依据则主要是根据时间特性。可设置一定的策略,比如:时间范围在1个月以内的叫做Hot数据;超过1个月且在3个月以内的叫做Warm数据;超出3个月的数据可进行归档或删除操作,这类数据也常被称之为Cold数据。数据因为时间特性具备了完备的生命周期概念。
通常在处理日志时,比如:业务应用发生异常,需要根据日志进行排错操作,此时查看发生错误时刻前后时间段的日志往往会有比较大的帮助。因此操作者对于日志的处理明显是有优先级概念的,数据分级存储就对应到这里的优先级概念,把优先级高的数据定位为Hot数据,并使用SSD高性能的存储介质确保足够的写入性能。
- 分级存储
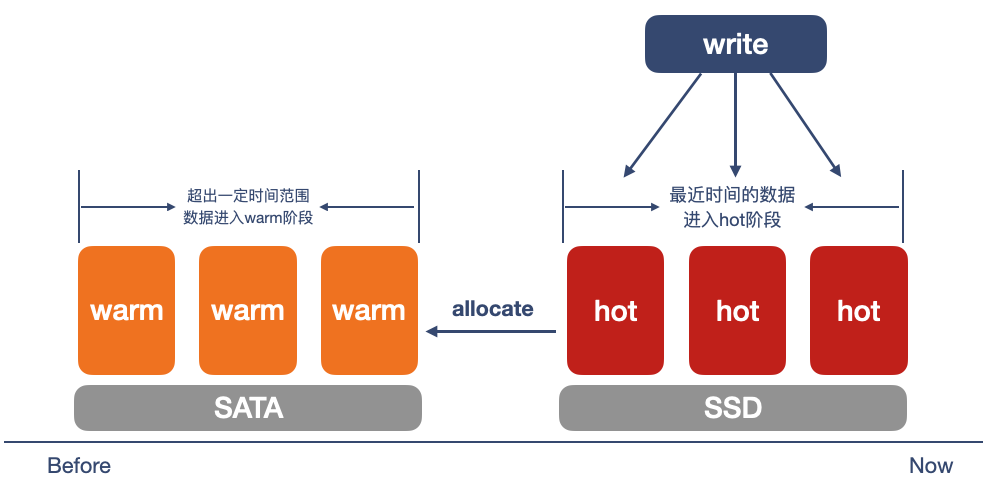
数据实时写入Hot节点,经过一段时间(可配置时间),OpenSearch集群内部会将满足时间条件的数据迁移至Warm节点,从而实现数据的分级存储。
➢ 数据分级搜索
- 原理介绍
数据分级搜索的主要依据依然是日志数据的时间属性。通常最近时间段的数据对于当下问题的处理才是最有帮助的,因此快速高效的检索出最近时间段的数据也是至关重要的。Hot阶段的数据会有比较高频的查询与聚合计算等操作,Warm阶段的数据只会有少量频次的查询,Cold数据(归档数据)几乎不再会有查询操作。
- 分级搜索
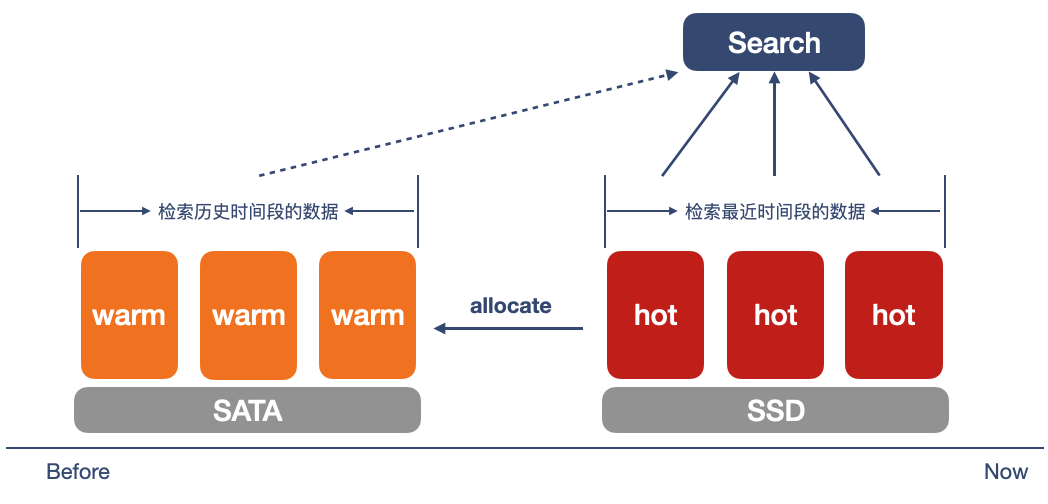
Hot节点支撑频繁且包含大量聚合计算的搜索任务,Warm节点只负责少量的搜索任务。