集群状态为Yellow
OpenSearch集群状态为Yellow表示集群内所有的主分片可用,但存在一个或者多个副本分片不可用。此时OpenSearch集群还不存在数据丢失,搜索结果仍将完整,但集群的高可用性在某种程度上会受到影响。
➢ 解决方案:
- 查看集群状态
curl -XGET 'http://opensearch_ip:opensearch_port/_cluster/health?pretty=true'
- 查看分片状态
curl -XGET 'http://opensearch_ip:opensearch_port/_cat/shards?v'
- 查看unassigned原因
GET /_cluster/allocation/explain
- 查看集群中不同节点、不同索引的状态(或者通过cerebro工具的web界面查看)
GET /_cat/shards?h=index,shard,prirep,state,unassigned.reason
- 原因排查及解决方案
原因1:OpenSearch默认配置包含1副本,但实际只部署了单节点集群;
方案1:设置集群副本数为0。
PUT /*/_settings
{
"number_of_replicas": 0
}
原因2:OpenSearch分配分片错误;
方案2:reroute,重新路由命令手动更改集群中各个分片的分配。
POST /_cluster/reroute
{
"commands": [
"allocate_replica": {
"index": "xxx" # 出现unassigned状态的索引
"shard": xxx # 重新分配的分片(标记黄色的分片)
"node": "xxx" # 重新路由到的OpenSearch节点
}
]
}
原因3:磁盘使用超过设定百分比85%,即OpenSearch不会将分片分配给磁盘使用超过85%的节点;
方案3:查看磁盘空间使用是否超过85%,如若超过,可删除过期的、不必要的索引以释放更多的磁盘空间。
DELETE indexName # 删除索引,释放空间
集群状态为Red
OpenSearch集群状态为Red表示集群内存在一个或者多个主分片不可用,此时执行查询时部分数据仍然可以查到,但需要尽快修复集群。主分片unassigned是集群Red的主要原因,造成主分片unassigned的可能原因包括:
- INDEX_CREATED:由于创建索引的操作导致分片未分配;
- CLUSTER_RECOVERED:由于集群完全恢复导致分片未分配;
- DANGLING_INDEX_IMPORTED:由于导入dangling索引导致分片未分配;
- NEW_INDEX_RESTORED:由于恢复新索引导致分片未分配;
- EXISTING_INDEX_RESTORED:由于恢复到已关闭的索引导致分片未分配;
- ALLOCATION_FAILED:由于分片分配失败导致分片未分配;
- NODE_LEFT:由于承载该分片的节点离开导致分片未分配;
- REINITIALIZED:由于当分片从开始移动到初始化时导致未分配。
➢ 解决方案:
- 这个分片数据已经不可用,直接删除该分片;
OpenSearch中没有直接删除分片的接口,可执行如下命令直接删除分片对应的索引(需要确认,该索引数据是否可被删除)。
curl -XDELETE opensearch_ip:opensearch_port/index_name
- allocate重新分配分片;
POST /_cluster/reroute
{
"commands": [
{
"allocate_stale_primary": {
"index": "xxx", # 未分配的分片对应的索引
"shard": xxx, # 未分配的分片对应的编号
"node": "xxx" # 将要分配到的节点
}
}
]
}
或者
POST _cluster/reroute (主分片数据损坏严重,无法有效恢复,可采用此方式丢失已经损坏的数据)
{
"commands": [
{
"allocate_empty_primary": {
"index": "xxx", # 未分配的分片对应的索引
"shard": xxx, # 未分配的分片对应的编号
"node": "xxx", # 将要分配到的节点
"accept_data_loss": true # 允许数据丢失
}
}
]
}
# 可结合opensearch官方文档一步步操作
搜索超时错误
AnyRobot系统执行搜索时,倘若选定的时间范围不合理或者没有选择日志分组,往往会出现搜索结果响应时间过长或者搜索结果因为超时无法响应的情况发生。OpenSearch搜索超时通常包含ConnectionTimeout、ReadTimeoutError、RequestTimeout三类异常,三类异常统一的呈现结果为有效的时间范围内Web页面无法渲染出搜索结果。因此,搜索时间过长与搜索超时最本质的问题是OpenSearch有限的算力无法在固定的时间范围内对海量数据实施有效的计算。AnyRobot搜索对依据条件有效过滤索引集合进行了深度优化,所以在使用搜索功能时推荐:
- 选定合理的时间范围(可从小范围逐步扩大,逐步验证);
- 选定日志分组(从日志分组逐步验证到不分组的情况)。
写入拒绝(Bulk Reject)
集群在某些情况下会出现写入拒绝的现象,具体表现为bulk写入时,会有类似如下报错信息:
{"reason":"rejected execution of org.opensearch.action.bulk.TransportBulkAction$1$2@351acad5 on OpenSearchThreadPoolExecutor[bulk, queue capacity = 1024, org.OpenSearch.common.util.concurrent.OpenSearchThreadPoolExecutor@6bd77359[Running, pool size = 12, active threads = 12, queued tasks = 2390, completed tasks = 20018208656]]","type":"rejected_execution_exception"}
通过opensearch/_cat/thread_pool/write接口返回结果中的rejected值可发现写入拒绝的次数统计。引起bulk reject问题的主要原因是shard容量过大或者是shard分配不均所致。
➢ 检查分片(shard)数据量是否过大
分片数据量过大,有可能引起bulk reject,建议单个分片大小控制在30GB~50GB左右。如果过大,可根据生命周期中索引大小的配置进行调整,比如:修改索引轮转策略,如果一个分片大小为50GB,则对应的这个索引大小则为number_of_shards * 50GB。也可增大该索引模板的number_of_shards值,这样同等大小的索引其每个分片的容量则在减小。
➢ 检查分片是否分布均匀
OpenSearch集群中分片分布不均匀,有的节点分配的shard过多,有的节点分配的shard少。分配过多的shard很容易因为写入热点的问题造成bulk reject。可通过以下两种方式调整分片数据不均匀的问题:
- 临时调整集群分片分配,动态调整某个索引的分片的分配设置;
PUT {index_name}/_settings
{
"settings": {
"index": {
"routing": {
"allocation": {
"total_shards_per_node": n //比如该索引有m个分片,集群共有k个数据节点,则n = m / k
}
}
}
}
}
-
调整索引模板,设置其在每个节点上的分片个数。
PUT _template/{template_name}
{
"order": 0,
"template": "xxx", //要调整的index前缀匹配
"settings": {
"index": {
"number_of_shards": "30", //指定index分配的shard数,可以根据一个shard 30 ~ 50GB左右的空间来分配
"routing.allocation.total_shards_per_node": xx //指定一个节点最多容纳的 shards 数
}
}
}
Master OOM Killer
OpenSearch本质上仍然是中心化的分布式架构,整个集群只有一个Active Master。Master负责整个集群的元数据管理,元数据包括全局的配置信息、索引信息和节点信息等,ClusterState对象封装的信息大致如下:
cluster uuid: 8I5JjfqeQiK3FG6DJyMfSw
version: 12
state uuid: gS-McA52S2CR56hWBdsRLQ
from_diff: false
meta data version: 41
[myindex/YfWcSmiLS1icUqt2yeRSKw]: v[5], mv[2], sv[1]
0: p_term [1], isa_ids [v8AO_f-sTVGAwaejrKsciQ]
1: p_term [1], isa_ids [i4GYvMwcQmqXAl2pSKo6lQ]
nodes:
{masterData}{qryMelBeQomAheXeWUhZ7Q}{NUerlsNYSn-A_6f1QO-Fjw}{192.168.2.187}{192.168.2.187:9300}{xpack.installed=true}, local, master
routing_table (version 9):
-- index [[myindex/YfWcSmiLS1icUqt2yeRSKw]]
----shard_id [myindex][0]
--------[myindex][0], node[qryMelBeQomAheXeWUhZ7Q], [P], s[STARTED], a[id=v8AO_f-sTVGAwaejrKsciQ]
----shard_id [myindex][1]
--------[myindex][1], node[qryMelBeQomAheXeWUhZ7Q], [P], s[STARTED], a[id=i4GYvMwcQmqXAl2pSKo6lQ]
routing_nodes:
-----node_id[qryMelBeQomAheXeWUhZ7Q][V]
--------[myindex][1], node[qryMelBeQomAheXeWUhZ7Q], [P], s[STARTED], a[id=i4GYvMwcQmqXAl2pSKo6lQ]
--------[myindex][0], node[qryMelBeQomAheXeWUhZ7Q], [P], s[STARTED], a[id=v8AO_f-sTVGAwaejrKsciQ]
---- unassigned
customs:
snapshot_deletions: SnapshotDeletionsInProgress[] security_tokens: TokenMetaData{ everything is secret } snapshots: SnapshotsInProgress[] restore: RestoreInProgress[[]]
所以当OpenSearch集群存储的数据量变大时(索引数变多、分片数变多),Master持有的ClusterState对象也会变得很大;ClusterState元信息主要存储在Java Heap中,因此集群数据规模变大时,ClusterState给予Master的Heap压力也在同等的变大,此时很容易造成Master节点的Heap空间占满的情况发生,即java.lang.OutOfMemoryError: Java heap space,OOM问题。
因此需要依据接入的数据量作容量规划:对于一些无法预估数据量的场景,需要实时的观察Master节点的Java Heap使用情况,如果Heap空间占用情况在递增,则需要及时增大-Xms -Xmx两个参数的值。可通过修改jvm.options文件或者修改环境变量OPENSEARCH_JAVA_OPTS="-Xms -Xmx",两种方式均可。
集群卡滞
对于OpenSearch集群重启或者数据恢复的场景,分片数据需要逐步的恢复,通常数据恢复的方式包含如下几种:
- EXISTING_STORE:数据在节点本地存在,从本地节点恢复;
- PEER:本地数据不可用或者不存在,从远端节点(源分片,一般是主分片)恢复;
- SNAPSHOT:数据从备份仓库恢复;
- LOCAL_SHARDS:分片合并(shrink)场景,从本地其他的分片进行。
为了提升恢复速度,可主动调整"cluster.routing.allocation.node_concurrent_recoveries"的值用于加快OpenSearch索引分片恢复速度,该值默认值为2。
对比实践发现,同等资源条件下node_concurrent_recoveries值设置为10,其分片数据恢复速度是默认值为2的分片恢复速度的4倍左右。但这个值不能设置过大,过大会导致整个集群卡住。本质原因是一个recovery任务会被封装成一个线程,放置在generic线程池中管理与运行,generic线程池默认大小为处理器核数*4,最大值为512。OpenSearch一些通用的后台任务都会用到该线程池,如果node_concurrent_recoveries的值设置过大,即一端generic线程池被这些请求占满,发出的请求等待对端返回,而发出的这些请求由于对端generic线程池同样的原因被打满,只能在等待队列中等待处理,则此时两端都处于相互等待状态,整个OpenSearch集群会被卡住,进而OpenSearch集群无法影响任何任务,任务请求。因此在实际场景中,这个值不要设置过大,推荐设置为10即可。
集群状态为Yellow
集群在某些情况下会出现查询失败的现象,具体表现为查询时,会有类似如下报错信息:
获取索引失败,异常: RequestError(400,search phaselexecutionexception' u'failed to create query: field expansion for [] matches too many fields, limit: 1024, got: xxx)
引起该错误的主要原因是查询子句数量过多,超过了默认的1024的限制。
➢ 检查查询语句条件是否合理
这个设置限制了Lucene布尔查询可以拥有的子句数量。默认值1024其实是很高的,通常应该足够了。这个限制不仅影响OpenSearch的bool查询,还影响许多其他在内部被重写为Lucene布尔查询的查询。设置这个限制是为了防止搜索变得太大,占用太多的CPU和内存。如果考虑增加此设置,请确保其他优化方法已全部尝尽并无法达成目标。较高的值可能导致性能下降和内存问题,特别是在高负载或资源较少的集群中。
➢ 通过helm 命令调整配置参数
helm upgrade opensearch-master helm_repos/proton-opensearch –reuse-values \
–set settings.”indices\.query\.bool\.max_clause_count”=10240
如果有hot、warm节点,也需要同时修改。
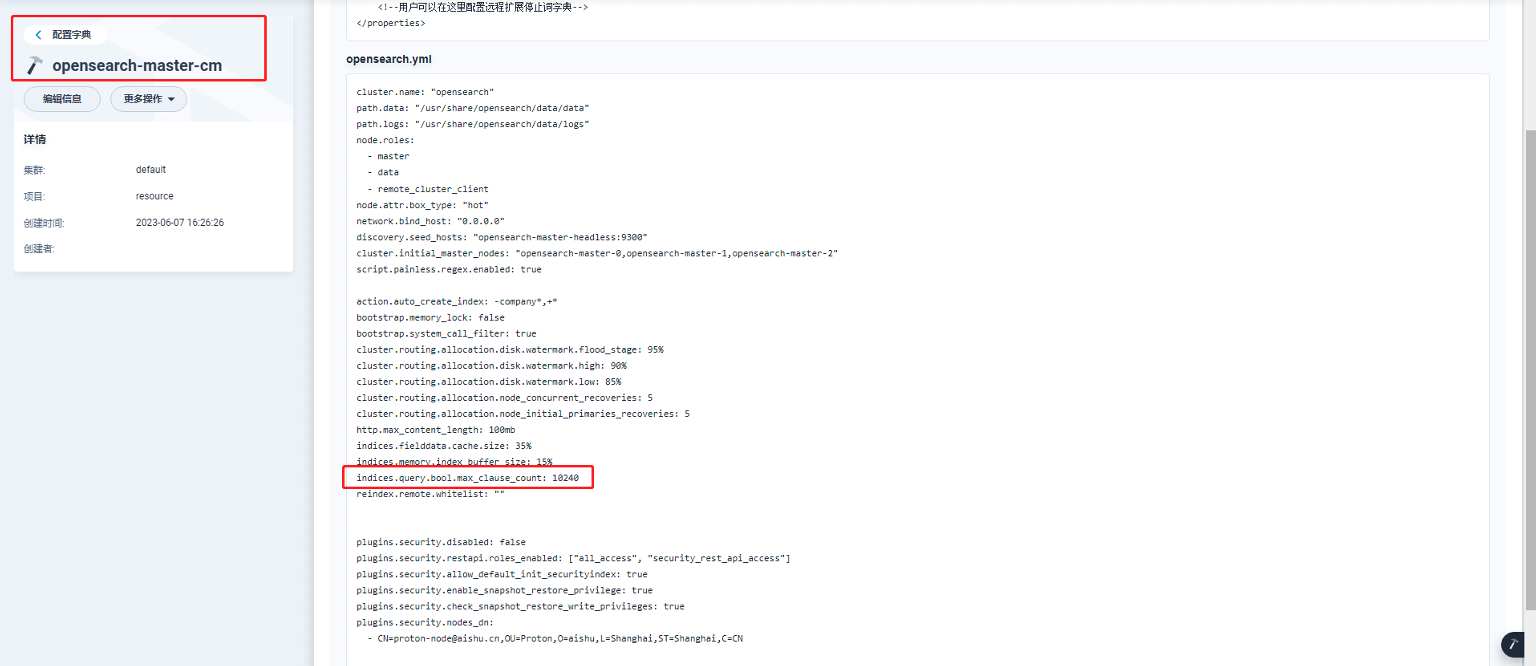
➢ 通过configmap 调整配置参数
如果有hot、warm节点,也需要同时修改对应configmap。