您可以根据实际业务场景中的指标需求,通过定义说明指标计算规则的查询语句、指标度量单位等参数,创建适于不同数据类型(支持指标数据(Metric)、链路数据(Trace)、日志数据(Log)及事件数据(Event))的指标模型,同时支持配置指标数据的持久化任务。具体如下:
► 创建指标模型
• 手动创建指标模型
配置步骤:
进入数据管理>数据模型>指标模型配置页面,点击【+新建】,进入“新建指标模型”的配置页面,如下所示:
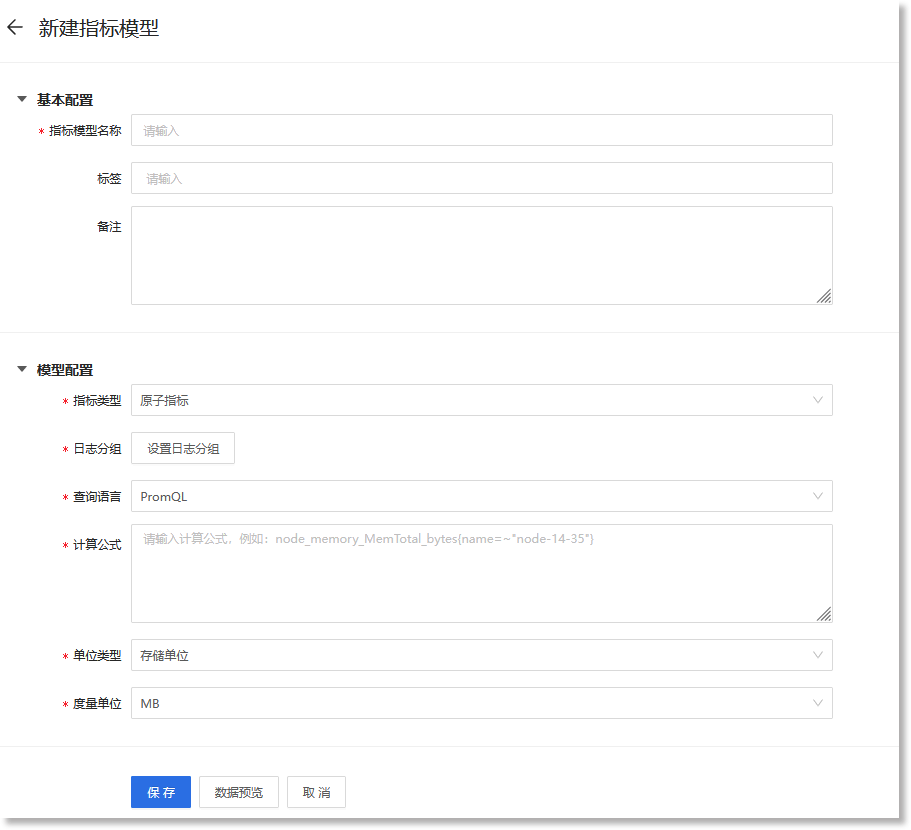
配置参数说明如下:
| 配置参数 | 参数说明 | 限制条件 |
| *指标模型名称 |
填写指标模型的名称 |
• 指标模型名称不能重复,且不能为空; • ≤40个字符 |
| 标签 |
根据实际需求设置指标模型的标签信息,用于业务标识。可通过回车键添加多个标签。 |
• 最多支持创建5个标签 |
| 备注 | 根据实际需求填写指标模型的其他属性信息 |
• ≤255个字符 |
在“模型配置”区域,配置指标模型的参数信息,如下所示:
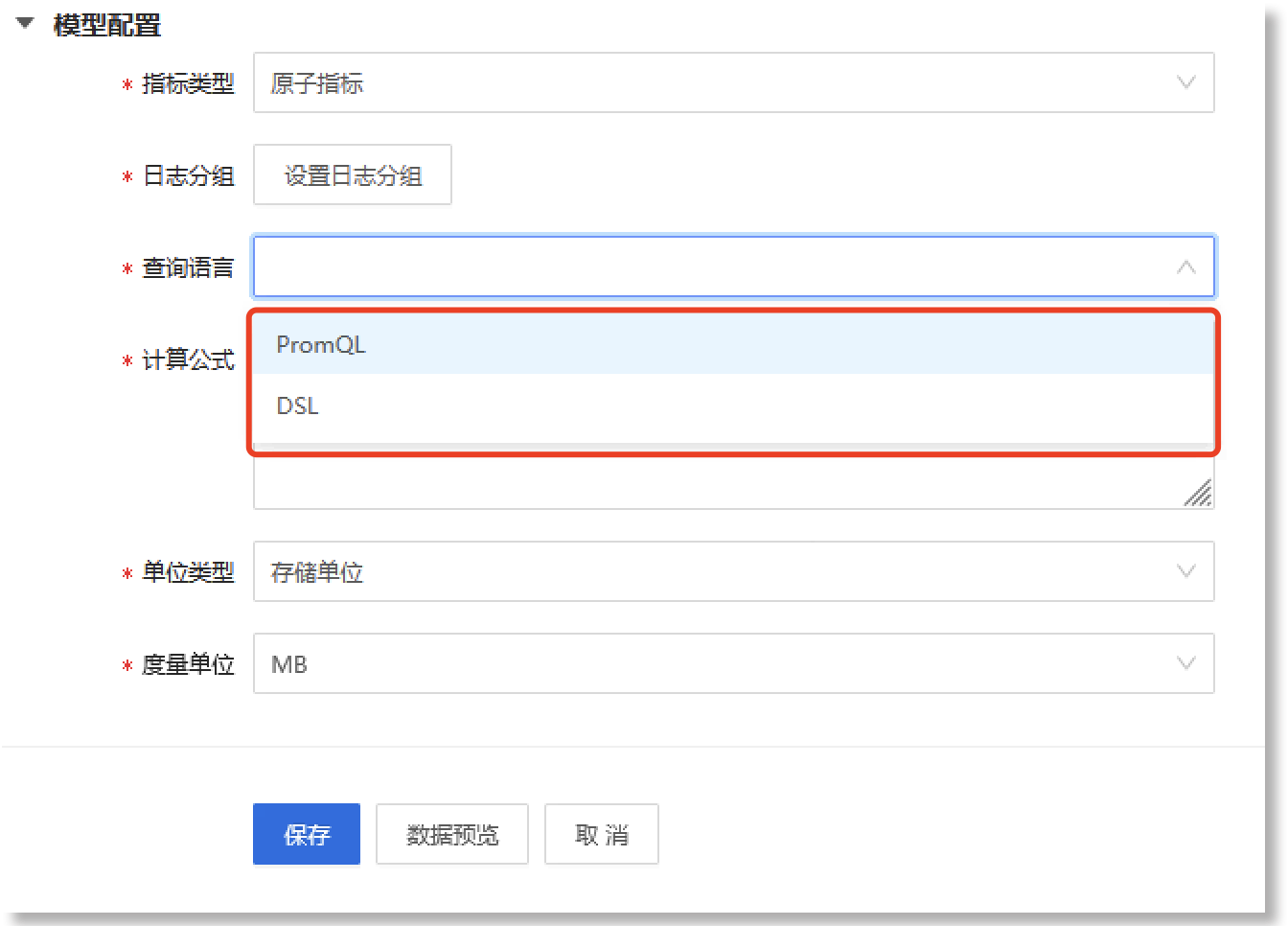
配置参数说明如下:
• *指标类型:在下拉框中选择指标的类型,默认为“原子指标”。原子指标可以理解为是对指标计算逻辑、具体算法的第一层抽象,皆在从根源上规范指标的定义,以保证指标的一致性。
_61.png) 说明:指标类型为必选项,当前仅支持配置“原子指标”。
说明:指标类型为必选项,当前仅支持配置“原子指标”。
• *日志分组:点击【设置日志分组】后,在弹出的"选择日志分组"抽屉中配置数据来源所属的日志分组。
说明:1. 日志分组为必填项。配置时,仅支持选择日志分组中的根分组,且仅支持配置1个分组;
2. 若找不到需要的日志分组,可点击抽屉最下方的“新建日志分组”进行创建。
• *查询语言:您需根据数据源的数据类别(category)选择适用的查询语言,可选项:PromQL、DSL。具体如下:
说明:查询语言为必选项。
• *计算公式:根据上方已配置的*查询语言,填写用于说明指标计算规则的对应查询语句。配置生效后,系统会根据此处定义的计算公式进行指标计算,得到对应指标数据(请参见 预览指标数据了解详情)。
说明:计算公式为必填项。
1)当*查询语言选择“PromQL”时,需填写用于说明指标计算规则的PromQL查询语句,具体书写规范请参见《AnyRobot Eyes 5 UniQuery 开发者指南》2.3PromQL查询语言>2.3.1-2.3.4 章节,若获取此文档失败请联系相关技术支持人员。
2)当*查询语言选择“DSL”时,配置框中默认提供了DSL语句的预输入框架,您可参照下图中的简要提示,修改可自定义的字段或默认字段,快速配置所需公式。您也可以详细了解预输入计算公式(DSL语句)结构的说明后,再根据实际需求配置所需的公式。
提示:预输入计算公式(DSL语句)中尖括号"<>"内为自定义字段,可根据实际需求进行修改;"(默认)”标识部分为默认字段,可直接应用,也可根据实际需求修改。

指标模型通过此处配置的DSL语句实现对指定数据集的聚合查询操作,进而提取所需的指标数据。配置框中提供的预输入DSL语句为嵌套的聚合结构(如上图所示),包括过滤查询部分、聚合查询部分。
• 过滤查询部分
| 键 | 含义 |
size |
size需设置为0。表示查询结果只返回聚合结果,不返回文档数据。 |
query |
表示这是一个查询操作。 |
bool |
布尔查询部分 |
filter |
查询的过滤条件。此处filter为空数组,表示此查询没有筛选条件,即查询时会匹配所有文档。可根据实际需求自行定义查询必要的匹配条件,以筛选指定数据,书写格式可参见OpenSearch官网文档>Filter context的相关内容。 |
• 聚合查询部分
“aggs”部分具体定义了需执行的聚合查询操作,包括三层嵌套的聚合:terms(词条)聚合、date_histogram(日期直方图)聚合、value_count(计数)聚合。terms聚合将按照<terms-field-name>.keyword字段的值对所选数据集分组。每个分组内再执行date_histogram聚合,具体按照@timestamp字段的值进行时间分组,时间分组的具体时间间隔由${{__interval}}的具体参数决定。最后,每个时间间隔内再进行value_count值聚合,用于统计每个间隔内@timestamp字段值对应的文档数量,生成指标数据。此默认嵌套聚合结构,可用于实现根据指定时间间隔(按天/周/月)对指定对象类别下某一指标的统计分析,帮助进行时间趋势相关的数据分析及可视化。
提示:您可根据实际指标需求自行定义所需的聚合方式,详情请参见支持的聚合方式。
三层嵌套聚合的详细说明如下:
| 键 | 含义 |
aggs |
聚合查询部分 |
<terms-aggs-name> |
terms(词条)聚合结果的名称,用于标识此聚合的结果,您可根据实际需求自定义命名。 |
terms |
terms(词条)聚合部分。分桶聚合类型,用于根据指定字段的值对数据进行分组,并统计每个不同值对应的文档数量或计算其他度量指标。 |
field |
terms(词条)聚合的分组字段。此处field:<terms-field-name>.keyword表示聚合将根据<terms-field-name>.keyword字段值对数据集进行分组,您可根据实际需求定义分组字段,书写格式可参见OpenSearch官网文档>AGGREGATIONS>Terms aggregations的相关内容。 |
size |
terms(词条)聚合返回的分组数量。此处size:10000表示最多返回10000个不同值对应的分组。
提示: |
| 键 | 含义 |
aggs |
嵌套的date_histogram聚合查询部分。表示将在terms聚合的每个分组中进行的date_histogram聚合。 |
<date-histogram-name> |
date_histogram(日期直方图)聚合结果的名称,用于标识聚合操作的结果,您可根据需求自定义命名。 |
date_histogram |
date_histogram(日期直方图)聚合部分。分桶聚合类型,用于根据指定日期字段的值对数据进行分组,并统计指定的时间间隔内的文档数量或计算其他度量指标。 |
field |
date_histogram(日期直方图)聚合的分组字段。您可根据实际需求自定义分组所需的日期字段,书写格式可参见OpenSearch官网文档>AGGREGATIONS>Date histogram aggregation 的相关内容。 |
fixed_interval |
date_histogram分桶聚合下,支持使用fixed_interval(固定时间间隔)以及calendar_interval(日历感知时间间隔)定义时间分桶的间隔。
需注意,在date_histogram聚合方式中 |
calendar_interval |
date_histogram分桶聚合下,支持使用fixed_interval(固定时间间隔)以及calendar_interval(日历感知时间间隔)定义时间分桶的间隔。
• 当选择按照日历感知时间间隔进行分桶时,不支持配置为变量,当前支持的日历间隔如下:
• 当选择按照日历感知时间间隔进行分桶时,可指定时区(默认为
|
min_doc_count |
时间间隔内最少文档数。如:"min_doc_count":1 表示若某个时间间隔内文档数<1,则该时间间隔不会被包含在聚合结果中。 |
order |
表示将对分组结果进行排序。 |
_key |
分组结果的具体排序方式。如 |
| 键 | 含义 |
aggs |
嵌套的value_count(计数)聚合部分。 |
<metric-aggs-name> |
value_count(计数)聚合结果的名称,用于标识聚合操作的结果,您可根据需求自定义命名。 |
value_count |
value_count(计数)聚合部分。值聚合类型,用于统计指定字段中非空值的数量。 |
field |
value_count(计数)聚合需要统计的字段。如"field": "@timestamp"表示要统计的字段是@timestamp。 |
▶︎ 计算公式(DSL语句)基本规范说明
上文仅对预输入框架中示意的聚合方式进行了配置说明,若实际场景中需要使用其他聚合方式,请参考OpenSearch官网文档>Aggregations章节中对应聚合方式的示例结构书写。DSL计算公式的书写需遵循DSL语句的基本语法结构(具体请参见OpenSearch官网文档)及以下特有约束。
1)分桶聚合:date_histogram(日期直方图)、terms(词条)、filters(过滤)、range(范围)、date_range(日期范围);
2)值聚合:value_count(计数)、cardinality(去重计数)、sum(求和)、avg(均值)、max(最大值)、min(最小值)、top_hits(桶内排序取 Top N)。
-
-
支持配置的分桶聚合层数需≤7,值聚合层数需=1,各层聚合的聚合名称不能重复。
-
-
子聚合约束
-
date_histogram(日期直方图)
-
计算公式中必须包含date_histogram,且只能有一个;
-
date_histogram 分桶聚合下的子聚合类型需为值聚合。
-
-
-
-
top_hits(桶内排序取 Top N)
-
top_hits 需满足如下结构:
-
-
"size": <number>,"sort": [ { "<sort_field_name>": { "order": "desc | asc" } }],"_source": { "includes": [ "<field_name1>", "<field_name2>", ...... ]}
校验说明:1. 完成指标模型的配置后,点击【数据预览】/【保存】按钮,系统将对计算公式(PromQL语句/DSL语句)的合法性进行校验,校验通过后,方可预览指标数据/成功创建指标模型;2. 当前暂不支持对查询语句中字段的权限进行校验,若查询了日志分组中不存在的字段,数据查询结果则为空。
注意:当前版本仅支持DSL的时序分析。
*度量字段:仅当*查询语言选择“DSL”时,此项可配置且为必填项,配置说明如下:
• 当计算公式中的值聚合方式为top_hits时,此处配置的度量字段应为top_hits中_source所包含的字段名称,且此字段名称对应的字段类型应为数值字段,不兼容日期。
• 当计算公式中的值聚合方式为其他类型时,此处配置的度量字段应为公式中的值聚合名称,若配置的度量字段与值聚合名称不匹配,系统将会报错。
说明:度量字段为必填项。
*单位类型:根据实际指标需求设置输出指标(即“度量值”)的度量单位类型,可选项包括:数值单位、存储单位、时间单位、传输速率。
*度量单位:根据实际指标需求设置输出指标(即“度量值”)的度量单位,不同单位类型下可选择的具体度量单位如下:
• 数值单位:无, 千, 百万, 十亿, 万亿,%
• 存储单位:bit(s), Byte(s), KB, MB, GB, TB, PB
• 时间单位:微秒,毫秒, 秒, 分, 时, 天, 周, 月, 年
• 传输速率:bps, Kbps, Mbps
• 批量导入创建指标模型
进入指标模型配置页面,点击列表上方的【导入】按钮,在弹出的窗口中选中包含指标模型配置信息的文件,点击【打开】后即可批量导入并创建指标模型。
注意:
1. 仅支持导入json格式的文件;
2. 支持导入多个指标模型:导入时,若指标模型的日志分组名称不存在,则导入操作失败。您需在完成对应日志分组的创建后,再进行导入操作;若AnyRobot中存有重名的指标模型对象,则导入动作将会停止,导入操作失败;
3. 批量导入失败后,您可在审计日志中查看对应的“失败”记录。
在指标模型列表中勾选某一指标模型后,点击列表上方的【导出】按钮,可将已创建的指标模型以“.json”格式导出,如下所示:

提示:支持导出多个指标模型。
指标模型创建成功后,您可以在AnyRobot其他数据模型模块和可视化分析模块引用此指标数据资源,进一步丰富数据基础,对模型定义的指标数据实现多维度、多场景的可视化指标分析、指标告警。详情请参见 指标模型应用 章节。