任一大数据处理系统追求的众多核心指标中永远包含快与准这2个指标。AnyRobot系统存储与分析引擎使用的是OpenSearch,OpenSearch内核针对快速且准确的处理数据做了很多深入的开发工作,同时也在依据RoadMap不断优化。同时,OpenSearch也对工业界通用的大数据优化处理技术均有涉猎,比如:异步化的方式提升写入性能、索引与数据分离的方式提升搜索性能、WAL方式确保数据的可靠性、DFS_QUERY_THEN_FETCH(分布式搜索)的方式提升打分的精确度等。
数据写入
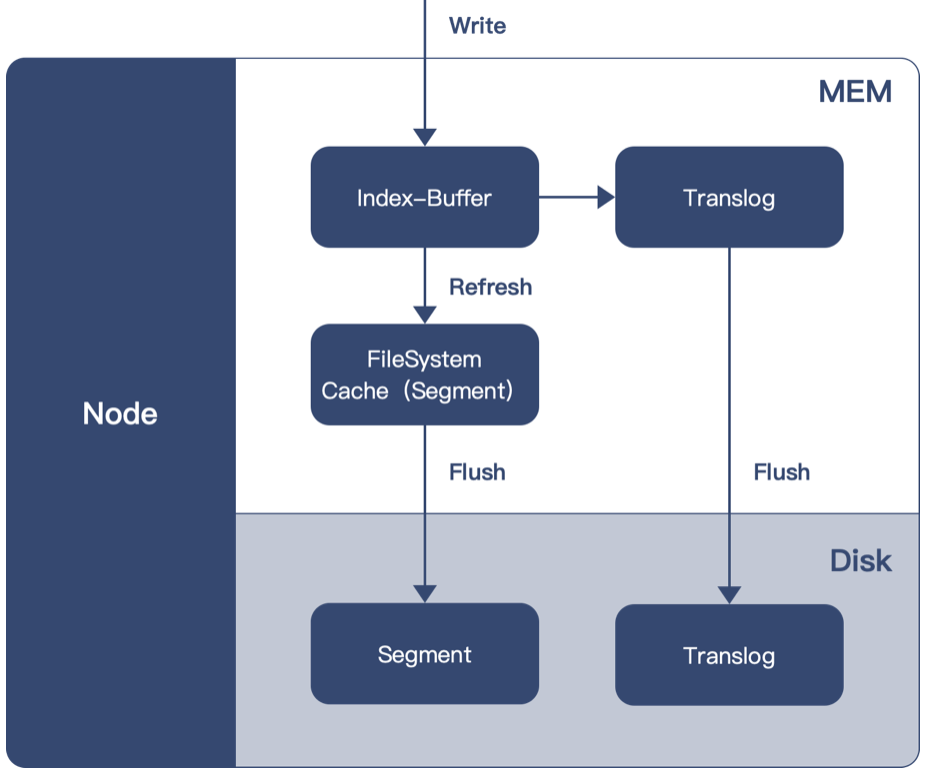
OpenSearch内部写入过程,数据首先会写入到程序内存中,经过一段时间生成段文件(Segment)并将这些段文件写入到OS Cache中,最终再统一写入到磁盘中。另一方面,在数据写入内存的同时接着写入Translog,Translog文件中的数据同样是间歇性刷新至磁盘中。
写入异步化的思想提升了数据的写入能力,同时为了保证数据的可靠性,额外引入了Translog文件即WAL机制确保数据不会因为机器故障发生丢失。OpenSearch数据写入的原理图,如下所示:
➢ 应对高性能写入
应对高性能写入的挑战,AnyRobot系统除了使用OpenSearch自身内核功能之外,同时也结合数据场景与OpenSearch内部原理在使用层面做了大量优化工作,包括:
-
- translog flush间隔调整;
- 索引刷新间隔refresh_interval调整;
- 索引数据缓冲区indexing buffer调整;
- 批处理的方式写入;
- 数据写入使用OpenSearch自身生成的DocID;
- 数据Schema精准建模;
- 分词器选用ik_max
如上是AnyRobot系统依据数据场景分别做的优化工作,写入能力较OpenSearch默认配置有5倍以上的性能提升。
_61.png) 说明:上述优化工作的具体说明详细可参见 OpenSearch性能优化 > 写入优化 章节。
说明:上述优化工作的具体说明详细可参见 OpenSearch性能优化 > 写入优化 章节。
OpenSearch自身是个分布式处理系统,对于每个批处理的写入,OpenSearch会把内部Doc(文档,通常一行日志被称之为一个Doc)级别的写入均匀的分发到集群的多个数据节点中,避免了单个结点写入热点的问题,有效提升了集群整体的写入性能。AnyRobot系统以微服务的方式部署OpenSearch实例,以容器化的方式运行并由K8s(Kubernetes,容器编排工具)平台执行编排工作。当面对数据压力上升时,可快速的对OpenSearch集群进行扩容以应对写入压力。
说明:OpenSearch集群的可伸缩性与高可用特性的阐述详细可参见 OpenSearch介绍 > 微服务架构特性描述 章节。
➢ 应对写入可靠性
应对写入可靠性的挑战,AnyRobot系统依赖的是OpenSearch内核机制Translog,即工业界通用的WAL(预写日志)技术,这里阐述下WAL技术的基本原理:
-
- 程序处理数据时,会先将对数据的修改作为一条记录顺序写入磁盘的log文件作为备份;由于磁盘文件的顺序追加写入效率比较高,因此备份log文件的写入方式均是追加写的方式;
- 数据写入log文件后,备份就成功了;接下来该数据就可以长期驻留在内存中;
- 系统会周期性地检查内存中的数据是否被处理完成(比如:被删除或者写入磁盘),并且生成对应的检查点(Check Point)记录在磁盘中;这样就可以随时删除被处理完成的数据且log文件会有轮询的清理策略;
- 倘若系统崩溃重启,此时只需要从磁盘中读取检查点,就能够知道最后一次成功处理的数据在log文件中的位置;接着从log文件中继续读出未被处理的数据将其加载至内存中即可;
WAL技术确保了高性能写入下的数据可靠性。AnyRobot系统在处理不同的业务数据(数据自身有优先级)时,我们也会适当的调整Translog策略,在写入性能与写入可靠性之间作权衡。
数据搜索
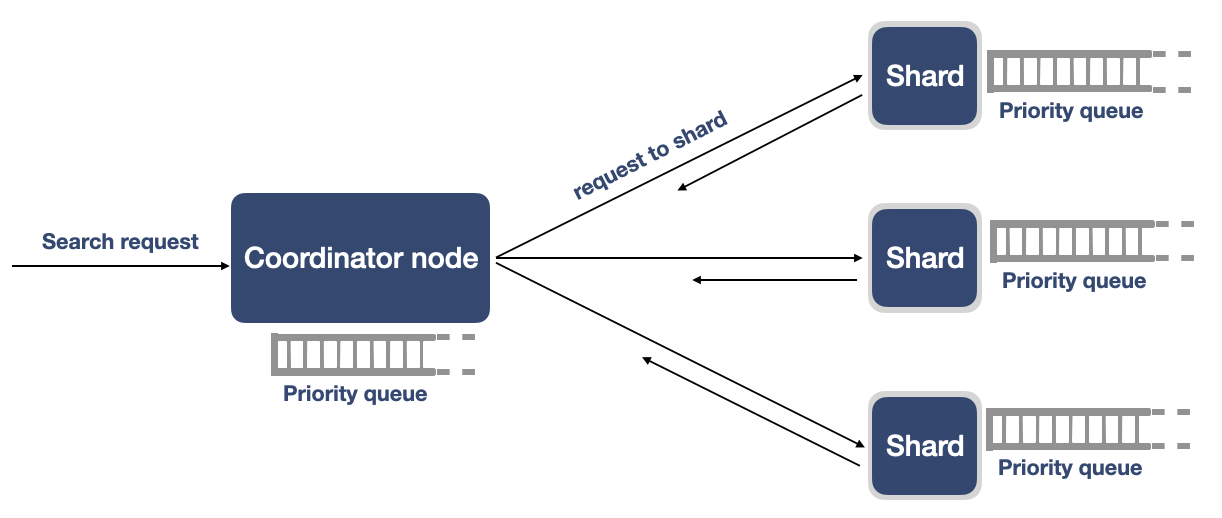
OpenSearch底层数据以分片为基本的存储单元,一个搜索请求往往会涉及到对多个分片的处理操作。OpenSearch默认采用Query_Then_Fetch两阶段的查询方式。首先一个查询请求会发送到协调节点,协调节点根据内部路由信息获取到本次查询需要遍历的分片,然后以一个分片封装成一个线程的方式分别对分片执行Query操作,得到每个分片上符合条件的DocID,然后由协调节点统一处理并计算出需要遍历的DocID列表,最后根据DocID列表再次向分片发送Fetch操作的请求,并最终获取到查询的结果集。
在高性能查询方面,OpenSearch内核采用了很多高阶的数据结构与算法,比如:LRU缓存技术、BKD范围搜索技术、字典树查找技术等。在使用层面上,因为AnyRobot处理的是日志数据,日志数据具有时间与类型2大基本特点,因此在高性能检索上首先通过时间与类型聚焦查询的数据范围,往往具有比较高效的查询性能。查询精准度方面,OpenSearch内部提供了Dfs_Query_Then_Fetch的查询模式,该模式会对涉及到的每个分片执行全部的打分计算并得到精确的全局得分,最终得到精准的查询结果集。
OpenSearch内核执行数据搜索的原理图,如下所示:
➢ 应对高性能检索
应对高性能检索的挑战,根据OpenSearch底层搜索原理并结合实际数据场景,AnyRobot系统在如下几个方面做了进一步的优化工作:
-
- 为OS Cache预留足够的内存;
- Hot节点使用更快的硬件;
- 为只读索引执行force-merge操作;
- 基于索引名称的时间与类型信息,按需缩小搜索的索引集合。
以上是AnyRobot系统结合实际数据场景做出的4点搜索优化工作,搜索性能较之前有了很大的提升。
说明:上述4个方面的优化工作的说明,详细可参见 OpenSearch性能优化 > 搜索优化 章节。
依据日志带有的时序属性,AnyRobot系统OpenSearch集群引入了Hot-Warm架构对搜索实行分级处理。最近时间段且搜索频次高的数据存储在Hot节点(分配足够的CPU、内存资源;若客户资源允许,存储会配置SSD);时间较久且搜索频次很低的数据存储在Warm结点上(分配一定的CPU、内存资源;存储使用机械盘)。这样根据数据访问频次的不同,分级搜索有效提升了搜索性能。
说明:OpenSearch集群Hot-Warm架构的描述,详细可参见 OpenSearch介绍 > Hot-Warm分层架构描述 章节。
➢ 应对搜索精确度
应对搜索精确度的挑战,当前AnyRobot系统主要依赖OpenSearch的Dfs_Query_Then_Fetch模式进行探索,搜索精确度最本质的体现是搜索结果的打分是否准确。OpenSearch底层存储的最小可执行单元是分片,各分片之间彼此独立,且默认打分机制是以分片为单位做TF-IDF的计算,这种以分片为单位的计算方式往往会不准确(会出现打分倾斜的现象)。Dfs_Query_Then_Fetch的方式底层会对所有的分片进行TF-IDF的统一计算,然后基于此进行打分,所以这种打分是非常准确的。
AnyRobot系统当前处理的日志场景中,搜索结果的首要排序方式依然是时间属性。一些数据场景也尝试过对搜索结果依据打分高低进行排序,因此后续AnyRobot系统在处理搜索结果的精确展示方面主要会依赖OpenSearch底层的Dfs_Query_Then_Fetch模式进行探索并落地。
综上,分别阐述了AnyRobot系统为应对海量日志数据的挑战所做的工作。不管是结合OpenSearch内核原理进行优化还是依据数据场景进行调优,最本质的首要条件是确保OpenSearch集群的稳定性。OpenSearch是典型的中心化分布式架构:Master节点主要负责管理集群元数据、同步集群节点信息,Data节点主要负责数据存储、数据搜索。
说明:
1. OpenSearch资源使用说明 章节,从OpenSearch内核原理的角度阐述了最佳配置方式以确保海量数据下OpenSearch集群的稳定性;
2. FAQs 章节,罗列出AnyRobot系统的常见问题以及详细解决方案。若能够确保OpenSearch集群的稳定性,且遵循模块中罗列的最佳配置选项与最佳实践方式,则这些常见问题大多不会遇见。