更新时间:2022-08-13 21:11:37
海量平台资源数据采集用于实现海量平台资源 vSphere 数据采集配置(如:数据中心、集群、资源池等),通过 API 方式获取 vSphere 数据。
_15.png) 说明:支持采集的 vSphere 版本:vSphere 5.5+。
说明:支持采集的 vSphere 版本:vSphere 5.5+。
具体操作如下:
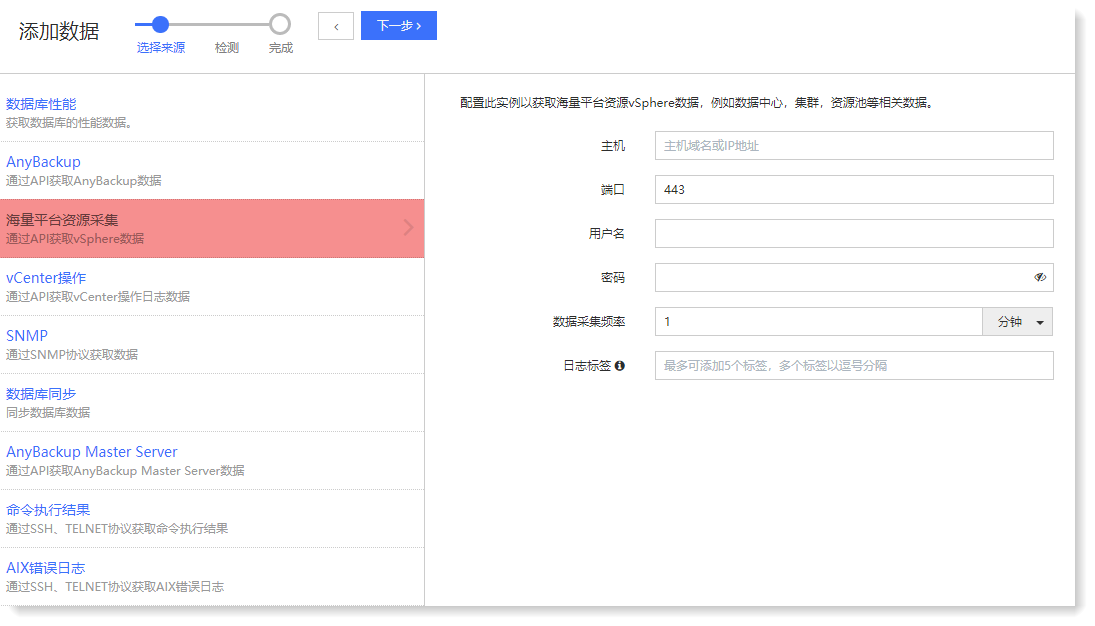
1. 在远程采集页面点击【新建】进入选择来源页面,选择【海量平台资源采集】进入配置页面,如下所示:
2. 点击【下一步】进入检测阶段,检测主机和端口、用户和密码是否匹配:
• 情况一:检测失败-存在相同的主机配置;
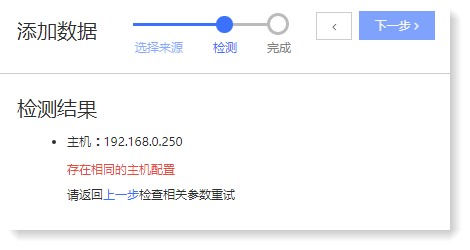
• 情况二:检测失败-无法连接远程主机和端口,可能存在主机和端口不匹配或连接超时的情况;

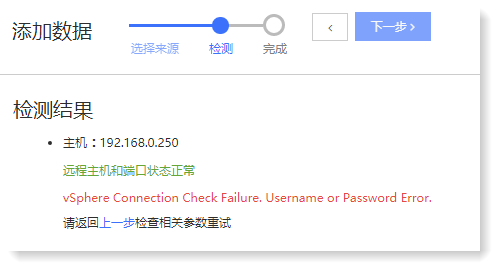
• 情况三:检测失败-用户或密码输入错误;
• 当主机首次添加;且主机和端口、用户和密码匹配,则检测成功。
3. 检测成功后点击【下一步】进入完成页面,在此页面可进行以下操作:
• 点击【开始搜索】:可跳转至搜索页面,自动搜索已采集的海量平台服务器运行日志数据;
• 点击【查看列表】:可跳转至远程采集列表页面,查看采集任务状态;
• 点击【添加更多数据】:可再次进入选择来源页面,继续添加配置新的远程采集任务。
说明:支持采集的 vSphere 版本:vSphere 5.5+。具体操作如下:
1. 在远程采集页面点击【新建】进入选择来源页面,选择【海量平台资源采集】进入配置页面,如下所示:
| 元素名称 | 元素说明 |
| 主机 | 设置海量平台服务器 的 IP 地址 |
| 端口 | 设置海量平台服务器开放访问的端口,默认为 443 |
| 用户名 | 设置登录服务器的用户名 |
| 密码 | 设置登录服务器的密码 |
| 数据采集频率 | 设置采集日志数据的执行频率,默认采集间隔为 1 小时 |
| 日志标签 | 添加采集日志的标签标识,点击回车或逗号即可生成标签 |
• 情况一:检测失败-存在相同的主机配置;
• 情况二:检测失败-无法连接远程主机和端口,可能存在主机和端口不匹配或连接超时的情况;
• 情况三:检测失败-用户或密码输入错误;
• 当主机首次添加;且主机和端口、用户和密码匹配,则检测成功。
3. 检测成功后点击【下一步】进入完成页面,在此页面可进行以下操作:
• 点击【开始搜索】:可跳转至搜索页面,自动搜索已采集的海量平台服务器运行日志数据;
• 点击【查看列表】:可跳转至远程采集列表页面,查看采集任务状态;
• 点击【添加更多数据】:可再次进入选择来源页面,继续添加配置新的远程采集任务。
< 上一篇:
下一篇: >