更新时间:2022-08-13 21:11:37
搜索条件方式可包含:分词全文检索、短语检索、字段值检索、逻辑运算符检索以及 SPL 命令检索。
► 分词全文检索:
检索一个或多个查询词时,系统不区分大小写。查询多个关键词时不区分关键词的先后顺序,查询结果将同时包含这些词。
示例:输入“测试 节点”后进行搜索,结果会包含测试、节点、测试节点,且匹配的词高亮显示,如下所示:

► 短语检索
若需要查询短语,需要用双引号把短语括起来,查询结果不区分大小写。
示例:查询“normal”,匹配的日志也必须包含“normal”。

► 字段值检索
若需根据特定的字段值过滤数据时,用户可以采用字段值检索的方式过滤数据。
格式为:field:value,其中 field 为字段,字段类型为字符串,搜索时区分大小写字母,不允许使用 ?* 等字符;value 可为字符串或数值,字符串区分大小写字母,可使用 * 字符。
示例如下:
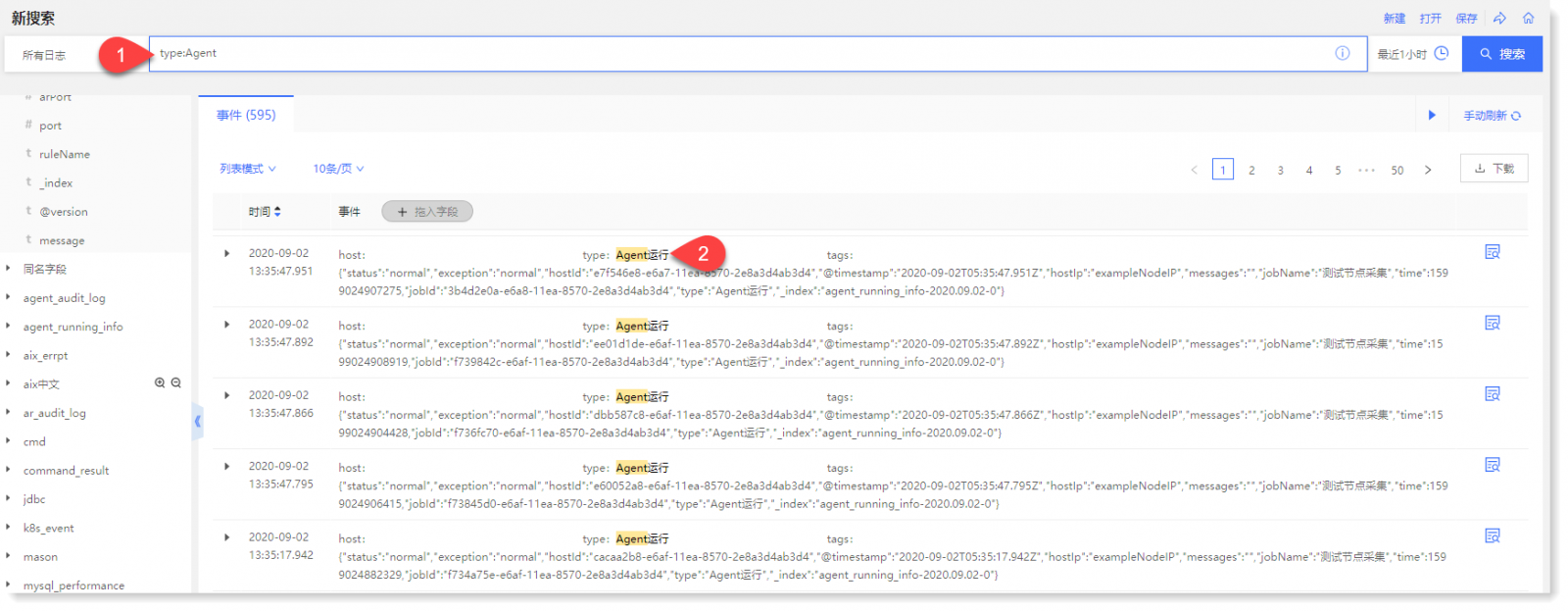
• 示例 1:type:Agent:表示过滤日志类型为 Agent 的数据;
• 示例 2:IP:192.*.*.*:表示采用通配符的方式过滤以 192 开头的 IP 地址。
► 逻辑运算符检索
逻辑运算符包含:AND、OR、NOT、(),其中 AND、OR、NOT 必须大写,逻辑运算符搜索可更有效的提高搜索效率。
• 示例 1:测试 AND Agent:表示 测试 和 Agent 需在日志中同时出现才匹配搜索条件,AND 默认可缺省;
• 示例 2:测试 OR Agent:表示 测试 或 Agent 需在日志中出现 1 个即可匹配搜索条件;
• 示例 3:NOT 测试:表示不包含 测试 字段的日志才匹配搜索条件;
• 示例 4:测试 AND (Agent OR aix):表示日志中必须包含测试,和 Agent、aix 中的任意 1 个,即可匹配搜索条件,其中()可改变布尔运算规则。

► SPL 命令
SPL 命令包含:rename 命令、parse 命令、join 命令、top 命令、stats 命令,命令之间支持组合使用。SPL 命令可以对日志数据进行字段重命名、动态抽取、关联性分析等操作。
• rename 命令:主要用于解决对已采集数据的再处理问题,用户可通过 rename 命令将字段重命名为所需的字段名。
_15.png) 说明:重命名只在 rename 命令运行时生效,运行结束重命名失效。
说明:重命名只在 rename 命令运行时生效,运行结束重命名失效。
格式:* | rename 字段 as 重命名名称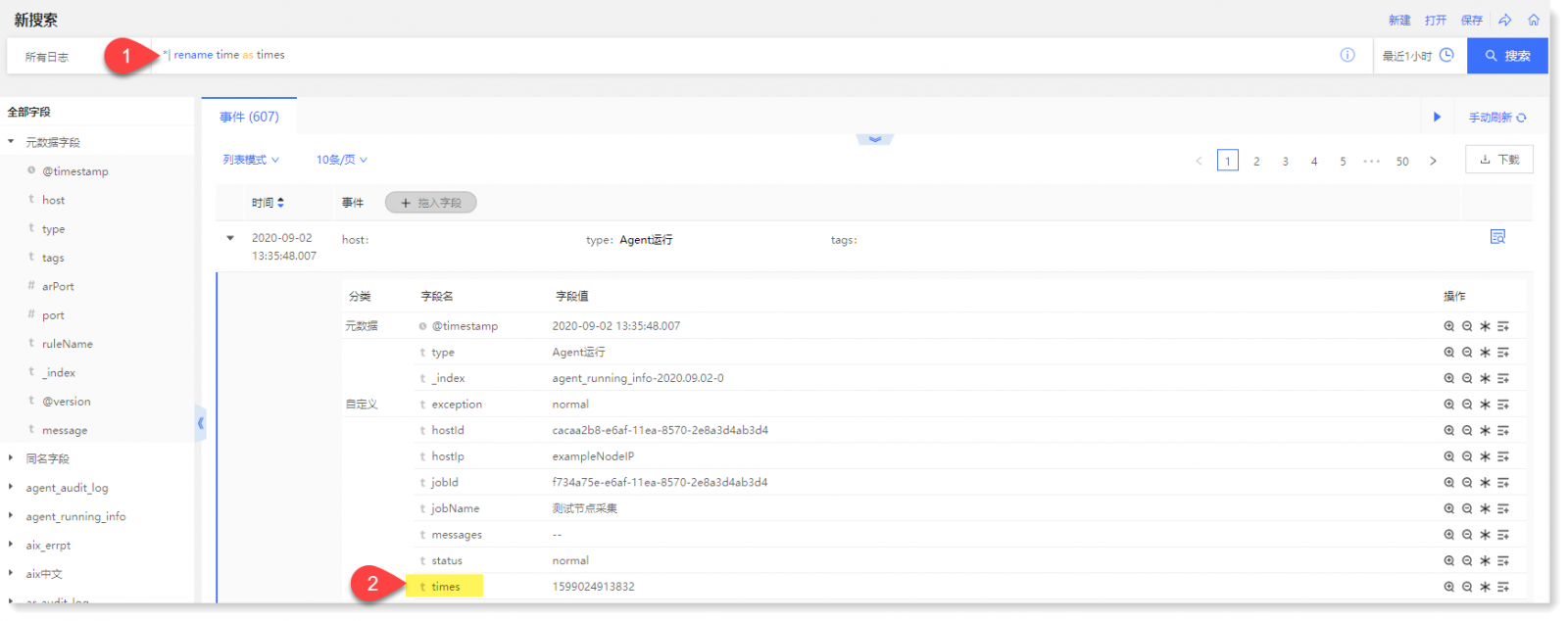

• parse 命令
用于搜索时动态抽取字段,对已进入系统的数据进行新字段提取过滤。
注意:正则表达式(regex)中新提取的字段不能与已有的字段重名。
格式:* | parse <field>"<regex>"
• 用法 3:与 Rename 命令联用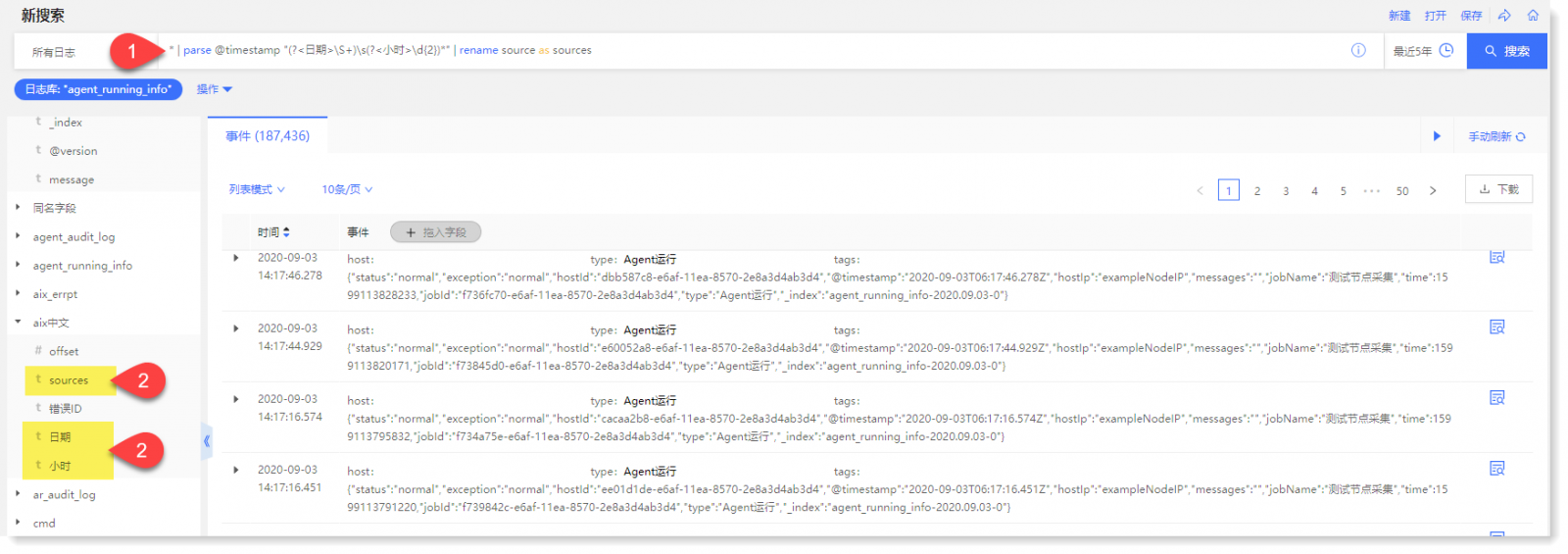
• join 命令
用于提供便捷的数据关联功能,供临时的分析场景、数据清洗使用。用户可在 AnyRobot 系统内,通过 join 命令将主查询的结果(字段集)和子查询的结果(字段集),通过关键字段关联。
格式:* | join type=left field-list [sub-search]
⇒ type:连接类型,包含内连接 inner、左连接 left 两种,默认为左连接(非必填项)。
其中,内连接表示:主查询和子查询的数据库表中必须同时存在连接字段值的记录,数据才会被检索出来;左连接表示:只需在主查询数据库中存在连接字段值的记录,数据就会被检索出来;
⇒ field-list:连接字段(必填项);
⇒ sub-search:子查询(必填项),将子查询的结果与主查询进行连接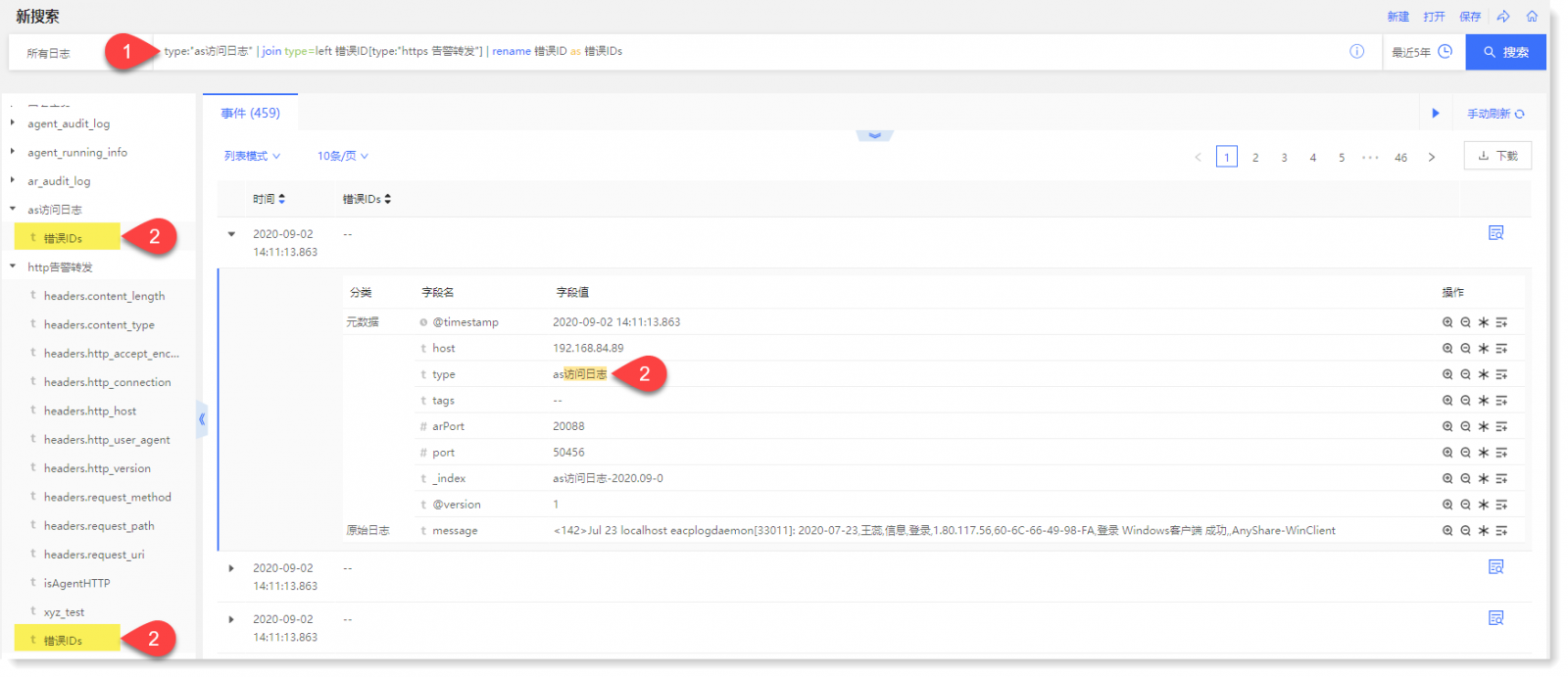
• 用法 2:与 parse 命令联用提取字段,再使用 join 命令进行关联
用于统计指定字段的所有值中出现频次最高的字段值的集合。命令返回搜索结果中包含字段值出现次数 (count) 计数以及所占百分比 (percentage);并支持根据字段分组后,再进行频次的统计。
• stats 命令
stats 是一个基础性命令,是进行搜索、可视化重构的前置需求。用于对搜索的结果集进行聚合统计,聚合方式包括:计数、最大值、最小值、平均值、总和、百分比分布、百分等级。还可以使用 by 语句对指定的字段进行分类,再对每个分类进行聚合统计计算,返回的结果为每个分类对应的结果集。
格式:*| stats stats-function (field1,field2,…..) AS field BY field-list
⇒ stats-function:eval 函数表达式
⇒ (field1,field2,…..):聚合字段
⇒ AS field:指定字段用于保存聚合统计的结果集
⇒ BY field-list:可选参数,用于设置指定字段进行分类聚合统计计算
State-function总结如下:
说明:min、max、avg、extended_stats、sum、percentiles、percentile_ranks 函数仅允许统计数值型字段。
► 分词全文检索:
检索一个或多个查询词时,系统不区分大小写。查询多个关键词时不区分关键词的先后顺序,查询结果将同时包含这些词。
示例:输入“测试 节点”后进行搜索,结果会包含测试、节点、测试节点,且匹配的词高亮显示,如下所示:
► 短语检索
若需要查询短语,需要用双引号把短语括起来,查询结果不区分大小写。
示例:查询“normal”,匹配的日志也必须包含“normal”。
► 字段值检索
若需根据特定的字段值过滤数据时,用户可以采用字段值检索的方式过滤数据。
格式为:field:value,其中 field 为字段,字段类型为字符串,搜索时区分大小写字母,不允许使用 ?* 等字符;value 可为字符串或数值,字符串区分大小写字母,可使用 * 字符。
示例如下:
• 示例 1:type:Agent:表示过滤日志类型为 Agent 的数据;
• 示例 2:IP:192.*.*.*:表示采用通配符的方式过滤以 192 开头的 IP 地址。
► 逻辑运算符检索
逻辑运算符包含:AND、OR、NOT、(),其中 AND、OR、NOT 必须大写,逻辑运算符搜索可更有效的提高搜索效率。
• 示例 1:测试 AND Agent:表示 测试 和 Agent 需在日志中同时出现才匹配搜索条件,AND 默认可缺省;
• 示例 2:测试 OR Agent:表示 测试 或 Agent 需在日志中出现 1 个即可匹配搜索条件;
• 示例 3:NOT 测试:表示不包含 测试 字段的日志才匹配搜索条件;
• 示例 4:测试 AND (Agent OR aix):表示日志中必须包含测试,和 Agent、aix 中的任意 1 个,即可匹配搜索条件,其中()可改变布尔运算规则。
► SPL 命令
SPL 命令包含:rename 命令、parse 命令、join 命令、top 命令、stats 命令,命令之间支持组合使用。SPL 命令可以对日志数据进行字段重命名、动态抽取、关联性分析等操作。
• rename 命令:主要用于解决对已采集数据的再处理问题,用户可通过 rename 命令将字段重命名为所需的字段名。
说明:重命名只在 rename 命令运行时生效,运行结束重命名失效。格式:* | rename 字段 as 重命名名称
• 用法 1:重命名字段
• 示例 1:输入:* | rename time as times,将字段“time”重命名为“times”,如下所示:
• 示例 1:输入:* | rename time as times,将字段“time”重命名为“times”,如下所示:
• 用法 2:重命名多个字段;
• 示例 2:输入:* | rename time as times,jobId as jobIds,将“time”重命名为“times”,同时将“jobId”重命名为“jobIds”,如下所示:
• 示例 2:输入:* | rename time as times,jobId as jobIds,将“time”重命名为“times”,同时将“jobId”重命名为“jobIds”,如下所示:
• parse 命令
用于搜索时动态抽取字段,对已进入系统的数据进行新字段提取过滤。
注意:正则表达式(regex)中新提取的字段不能与已有的字段重名。格式:* | parse <field>"<regex>"
• 用法 1:对原始日志进行字段提取
• 示例 1:输入:* | parse “(?\d+\.\d+\.\d+\.\d+)”,用于将日志数据 ip 信息提取出来并生成 ip 字段,并对 ip 字段值进行统一抽取。
• 示例 1:输入:* | parse “(?\d+\.\d+\.\d+\.\d+)”,用于将日志数据 ip 信息提取出来并生成 ip 字段,并对 ip 字段值进行统一抽取。
• 用法 2:对已解析字段再次进行字段提取
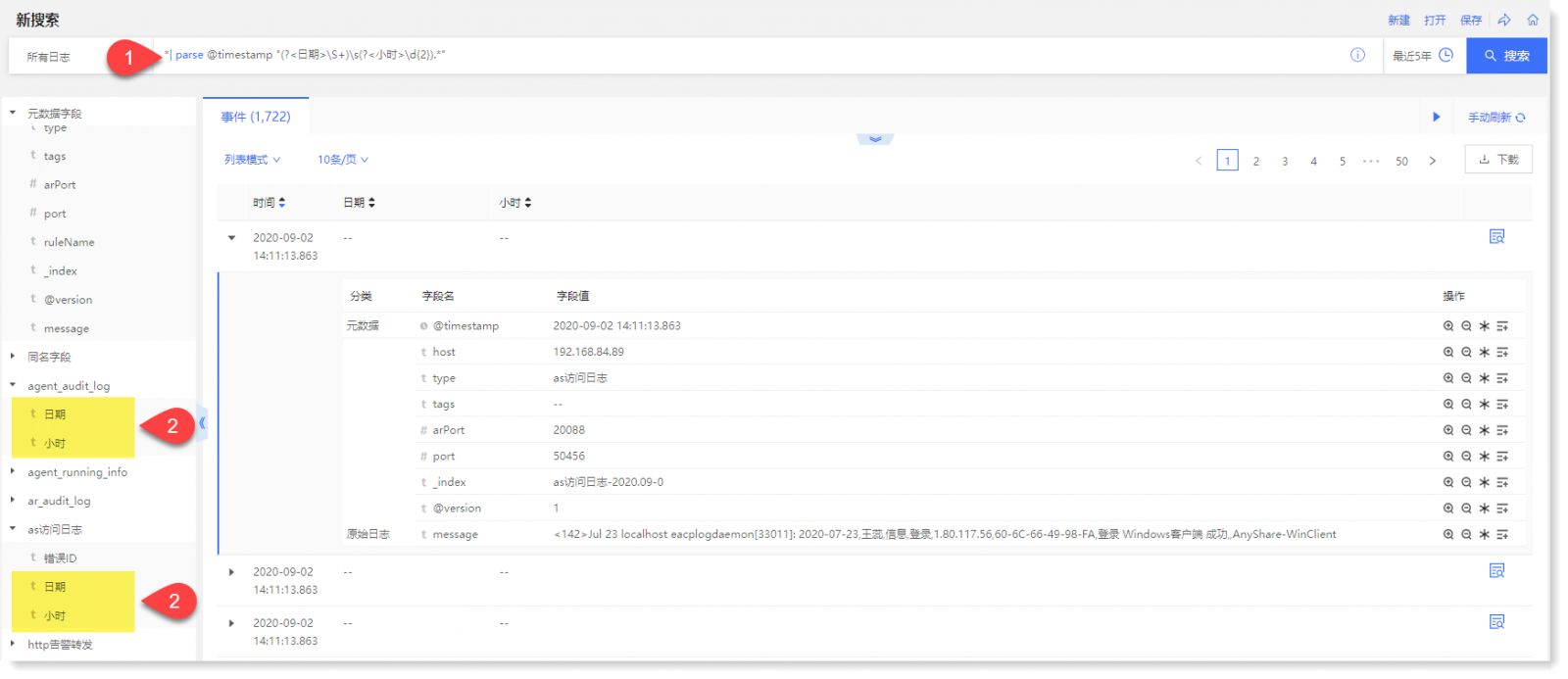
• 示例 2:输入:* | parse @timestamp “(?<日期>\S+)\s(?<小时>\d{2}).*”,将“时间”字段进行二次抽取分别抽取“日期”和“小时”字段,如下所示:
• 示例 2:输入:* | parse @timestamp “(?<日期>\S+)\s(?<小时>\d{2}).*”,将“时间”字段进行二次抽取分别抽取“日期”和“小时”字段,如下所示:
• 用法 3:与 Rename 命令联用
• 示例 3:输入:* | parse @timestamp “(?<日期>\S+)\s(?<小时>\d{2})*” | rename source as sources,将 @timestamp 字段抽取,并通过 rename 命令将“source”重命名为“sources",如下所示:
• join 命令
用于提供便捷的数据关联功能,供临时的分析场景、数据清洗使用。用户可在 AnyRobot 系统内,通过 join 命令将主查询的结果(字段集)和子查询的结果(字段集),通过关键字段关联。
格式:* | join type=left field-list [sub-search]
⇒ type:连接类型,包含内连接 inner、左连接 left 两种,默认为左连接(非必填项)。
其中,内连接表示:主查询和子查询的数据库表中必须同时存在连接字段值的记录,数据才会被检索出来;左连接表示:只需在主查询数据库中存在连接字段值的记录,数据就会被检索出来;
⇒ field-list:连接字段(必填项);
⇒ sub-search:子查询(必填项),将子查询的结果与主查询进行连接
• 用法 1:与 rename 命令联用,重命名关联字段
• 示例 1:输入:type:"as访问日志"| join type=left 错误ID[type:”https 告警转发”] | rename 错误ID as 错误IDs,表示对“as访问日志”包含“错误ID”的数据,与“https 告警转发”包含“错误ID”的数据进行左连接,并将“错误ID”重命名为“错误IDs”,如下所示:
• 示例 1:输入:type:"as访问日志"| join type=left 错误ID[type:”https 告警转发”] | rename 错误ID as 错误IDs,表示对“as访问日志”包含“错误ID”的数据,与“https 告警转发”包含“错误ID”的数据进行左连接,并将“错误ID”重命名为“错误IDs”,如下所示:
• 用法 2:与 parse 命令联用提取字段,再使用 join 命令进行关联
• 示例 2:输入:type:"as访问日志" | parse 用户 "(?<用户名>.*)" | join type=inner 用户名[type:”as 操作日志”] | rename 用户 as 用户名
• top 命令用于统计指定字段的所有值中出现频次最高的字段值的集合。命令返回搜索结果中包含字段值出现次数 (count) 计数以及所占百分比 (percentage);并支持根据字段分组后,再进行频次的统计。
• stats 命令
stats 是一个基础性命令,是进行搜索、可视化重构的前置需求。用于对搜索的结果集进行聚合统计,聚合方式包括:计数、最大值、最小值、平均值、总和、百分比分布、百分等级。还可以使用 by 语句对指定的字段进行分类,再对每个分类进行聚合统计计算,返回的结果为每个分类对应的结果集。
格式:*| stats stats-function (field1,field2,…..) AS field BY field-list
⇒ stats-function:eval 函数表达式
⇒ (field1,field2,…..):聚合字段
⇒ AS field:指定字段用于保存聚合统计的结果集
⇒ BY field-list:可选参数,用于设置指定字段进行分类聚合统计计算
State-function总结如下:
说明:min、max、avg、extended_stats、sum、percentiles、percentile_ranks 函数仅允许统计数值型字段。
• 用法 1:返回每个主机的平均传输速率
• 示例 1:sourcetype=access* | stats avg(kbps) BY host
• 示例 1:sourcetype=access* | stats avg(kbps) BY host
• 用法 2:搜索 access 日志,计算 “referer_domain”字段中值 top 100 的总数
• 示例 2:输入:sourcetype=access_combined | top limit=100 referer_domain | stats sum(count) AS total
• 示例 2:输入:sourcetype=access_combined | top limit=100 referer_domain | stats sum(count) AS total
• 用法 3:假设有一个字段【销售额】,字段值为 15、15、30、40、50
• 示例 3:
• 计数:返回目标字段(任意类型字段)的计数。stats count (销售额)=5
• 最大值:返回目标字段(数值型字段)中值最大的字段值。stats max (销售额)=50
• 最小值:返回目标字段(数值型字段)中值最小的字段值。stats min (销售额)=15
• 平均值:返回目标字段(数值型字段)的平均值。stats avg (销售额)=30
• 总和:返回目标字段(数值型字段)的总和。stats sum (销售额)=150
• 去重计数:返回目标字段(任意类型字段)的去重计数。stats cardinality (销售额)=4
• 统计目标字段(数值型字段)的计数、最大值、最小值、平均值、总和、平方和、方差、标准差。stats extended_stats(销售额)=5(计数)、50(最大值)、15(最小值)、30(平均值)、150(总和)、5450(平方和)、237.5(方差)、15.41104(标准差)
• 百分位数:返回目标字段(数值型字段)的自定义百分位数。stats percentiles (销售额,70)=38,表示:70% 的销售额是小于 38 的。stats percentiles (销售额,20,50,90)=15,30,46,表示:20%的销售额小于 15;50%的销售额小于 30;90%的销售额小于 46
• percentile_ranks:返回指定字段值(数值型)对应的百分位数。stats percentile_ranks (销售额,50)=100%,表示销售额 50 对应的百分位数是 100%,即销售额 100% 小于 50。
• 最大值:返回目标字段(数值型字段)中值最大的字段值。stats max (销售额)=50
• 最小值:返回目标字段(数值型字段)中值最小的字段值。stats min (销售额)=15
• 平均值:返回目标字段(数值型字段)的平均值。stats avg (销售额)=30
• 总和:返回目标字段(数值型字段)的总和。stats sum (销售额)=150
• 去重计数:返回目标字段(任意类型字段)的去重计数。stats cardinality (销售额)=4
• 统计目标字段(数值型字段)的计数、最大值、最小值、平均值、总和、平方和、方差、标准差。stats extended_stats(销售额)=5(计数)、50(最大值)、15(最小值)、30(平均值)、150(总和)、5450(平方和)、237.5(方差)、15.41104(标准差)
• 百分位数:返回目标字段(数值型字段)的自定义百分位数。stats percentiles (销售额,70)=38,表示:70% 的销售额是小于 38 的。stats percentiles (销售额,20,50,90)=15,30,46,表示:20%的销售额小于 15;50%的销售额小于 30;90%的销售额小于 46
• percentile_ranks:返回指定字段值(数值型)对应的百分位数。stats percentile_ranks (销售额,50)=100%,表示销售额 50 对应的百分位数是 100%,即销售额 100% 小于 50。
< 上一篇:
下一篇: >