更新时间:2022-08-13 21:30:54
根因分析采用了决策树算法,通过统计分析自变量特征对目标变量的影响程度,从而分析出关键性变量。
一个完整的根因分析任务分为 2 个部分:数据源配置和模型计算:
• 数据源配置:用于准备数据,以实现数据分析及分析维度的可视化展示;
• 模型计算:用于提供多种算法,可根据实际需求选择不同的算法及参数进行模型计算。
新建根因分析任务,具体操作如下:
1. 进入机器学习页面,点击【新建】进入新建机器学习任务页面,点击【查看帮助】可查看根因分析学习任务的简介和应用场景示例,如下所示:

2. 点击【根因分析】进入参数配置页面,点击【查看帮助】可查看根因分析的简介、使用帮助、参数配置指导、算法介绍,如下所示:

3. 配置数据源:数据预览部分用于以可视化方式展示特征字段和信息字段的原始数据列表;
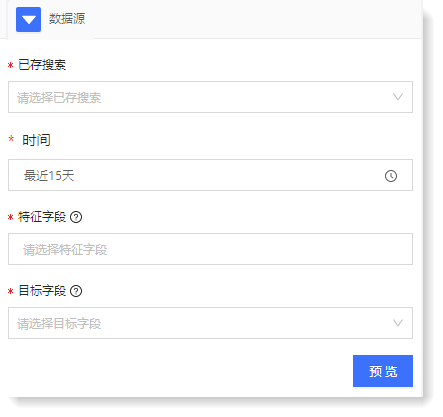
1)配置参数如下: 2)点击【预览】查看数据预览结果,数据预览结果为特征字段和信息字段的原始数据列表,如下所示:
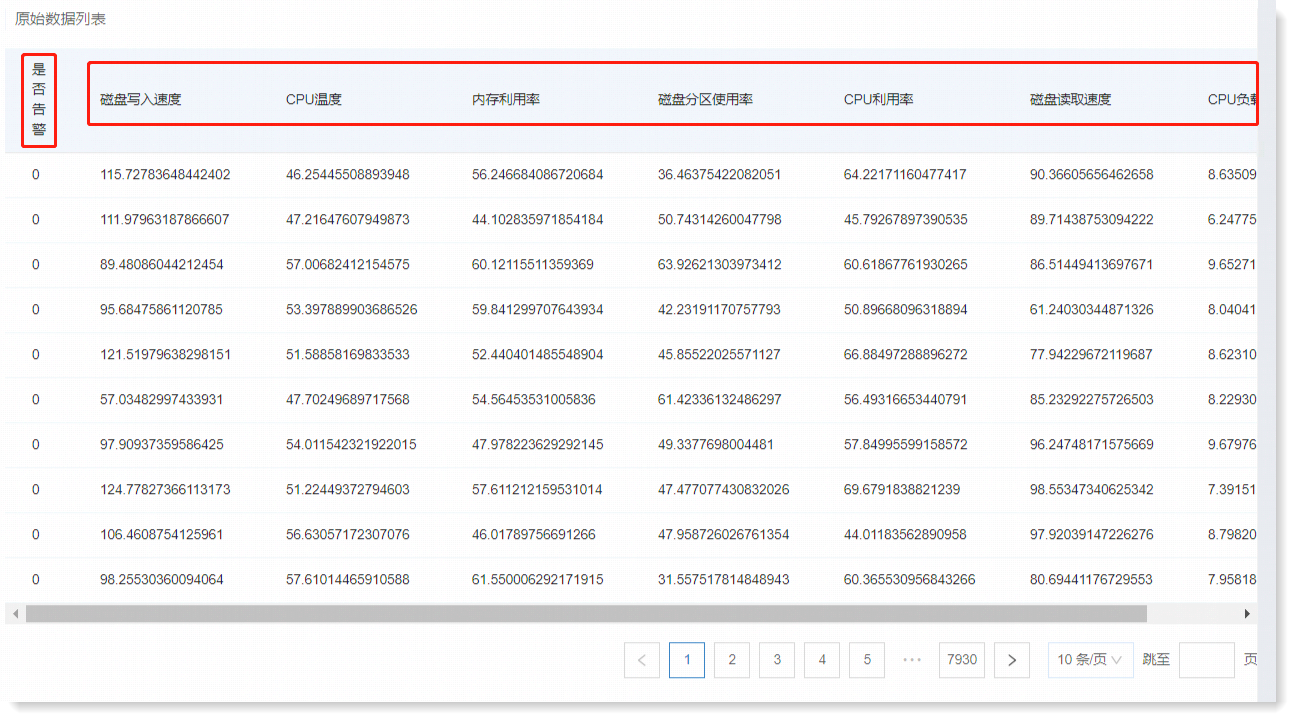
以上示例中:
• 特征字段(原因)包含:磁盘写入速度、CPU 温度、内存利用率、磁盘分区使用率、CPU 利用率、磁盘读取速度、CPU 负载;
• 目标字段(结果)包含:是否告警
4. 配置模型计算
根因分析支持决策树算法,决策树是一种非参数的监督学习方法,通常采用自上而下的设计,每迭代循环一次,就会选择一个特征值进行分叉,直到无法分叉为止;其中,决策树中的分支代表了决策规则(IF THEN 规则),决策树中的叶节点表示 IF THEN 规则的结果,通过 IF THEN 规则可预测目标变量的值。
配置参数如下所示:
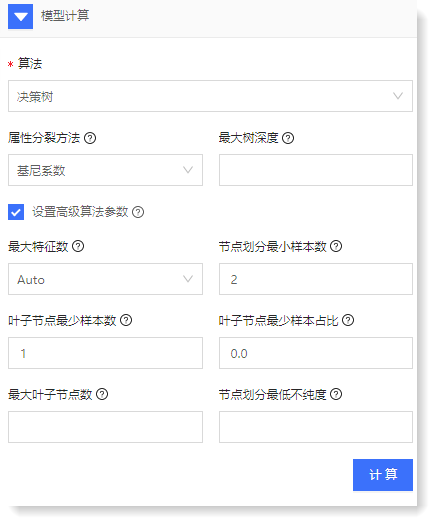
1)配置决策树算法参数: 2)点击【预览】可查看模型计算结果,如下所示:
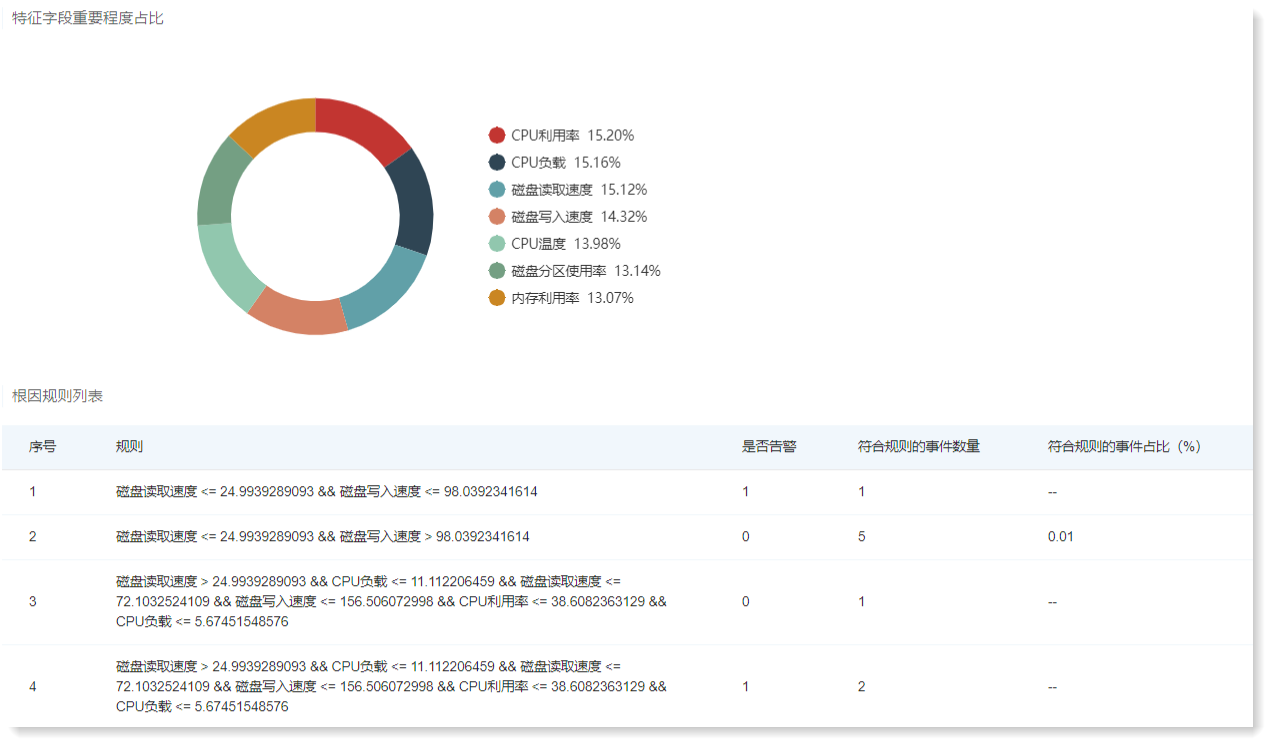
根因分析模型计算结果包括:特征(原因)字段重要程度占比和根因规则列表 2 个部分: 5. 完成上述所有配置后,点击【保存】填写机器学习任务名称,点击【确认】即可完成机器学习任务创建操作。
一个完整的根因分析任务分为 2 个部分:数据源配置和模型计算:
• 数据源配置:用于准备数据,以实现数据分析及分析维度的可视化展示;
• 模型计算:用于提供多种算法,可根据实际需求选择不同的算法及参数进行模型计算。
新建根因分析任务,具体操作如下:
1. 进入机器学习页面,点击【新建】进入新建机器学习任务页面,点击【查看帮助】可查看根因分析学习任务的简介和应用场景示例,如下所示:
2. 点击【根因分析】进入参数配置页面,点击【查看帮助】可查看根因分析的简介、使用帮助、参数配置指导、算法介绍,如下所示:
3. 配置数据源:数据预览部分用于以可视化方式展示特征字段和信息字段的原始数据列表;
1)配置参数如下: 2)点击【预览】查看数据预览结果,数据预览结果为特征字段和信息字段的原始数据列表,如下所示:
以上示例中:
• 特征字段(原因)包含:磁盘写入速度、CPU 温度、内存利用率、磁盘分区使用率、CPU 利用率、磁盘读取速度、CPU 负载;
• 目标字段(结果)包含:是否告警
4. 配置模型计算
根因分析支持决策树算法,决策树是一种非参数的监督学习方法,通常采用自上而下的设计,每迭代循环一次,就会选择一个特征值进行分叉,直到无法分叉为止;其中,决策树中的分支代表了决策规则(IF THEN 规则),决策树中的叶节点表示 IF THEN 规则的结果,通过 IF THEN 规则可预测目标变量的值。
配置参数如下所示:
1)配置决策树算法参数: 2)点击【预览】可查看模型计算结果,如下所示:
根因分析模型计算结果包括:特征(原因)字段重要程度占比和根因规则列表 2 个部分: 5. 完成上述所有配置后,点击【保存】填写机器学习任务名称,点击【确认】即可完成机器学习任务创建操作。
< 上一篇:
下一篇: >