更新时间:2022-08-22 16:13:12
1. 进入机器学习页面,点击【新建】进入新建机器学习任务页面,点击【查看帮助】可查看异常检测机器学习任务的简介和应用场景示例,如下所示:
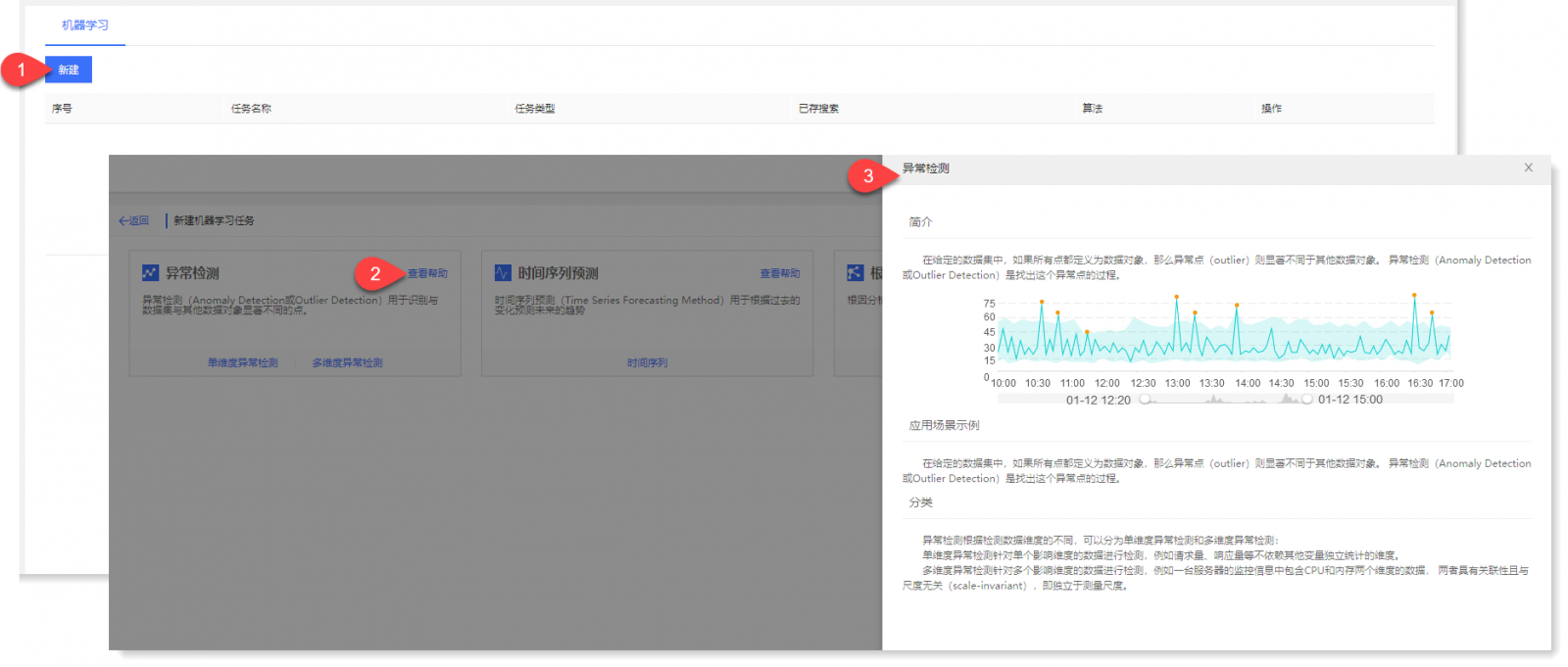
2. 点击【单维度异常检测】进入单维度异常检测参数配置页面,点击右上角【查看帮助】按钮,可翻页查看单维度异常检测的简介、使用帮助、参数配置指导、算法介绍;
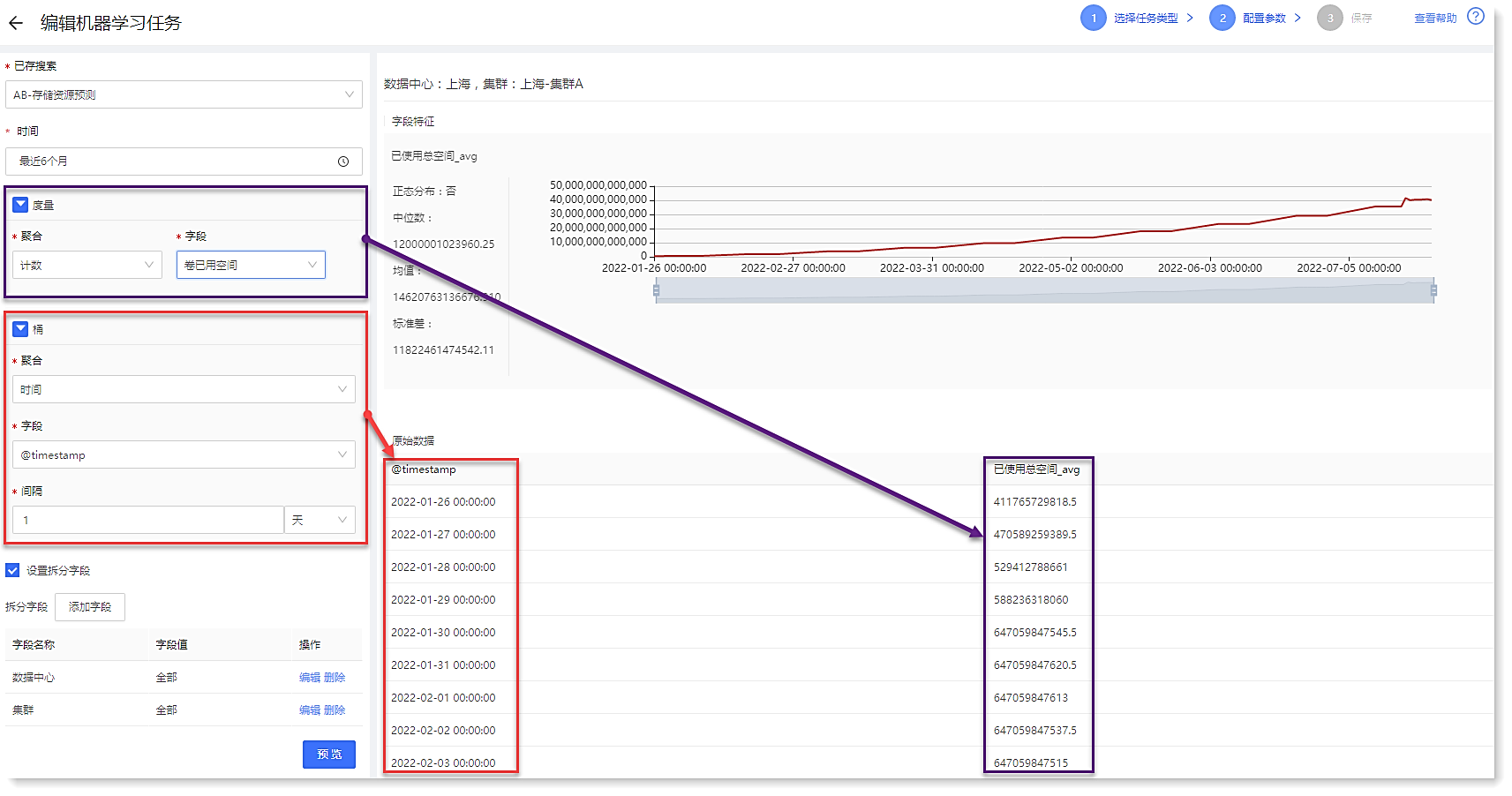
3. 配置数据源:通过配置数据源,可预览数据的统计信息、趋势图以及原始日志数据,如下所示:
2. 点击【单维度异常检测】进入单维度异常检测参数配置页面,点击右上角【查看帮助】按钮,可翻页查看单维度异常检测的简介、使用帮助、参数配置指导、算法介绍;
3. 配置数据源:通过配置数据源,可预览数据的统计信息、趋势图以及原始日志数据,如下所示:
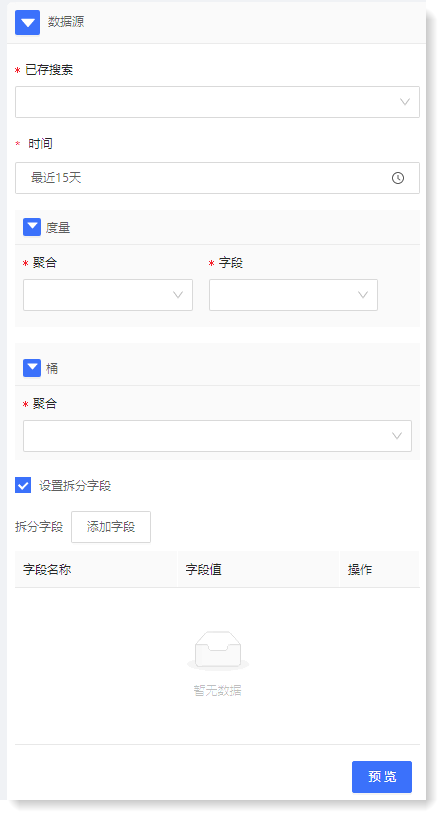
► *已存搜索:
在已存搜索下拉列表中,选择所需的已存搜索,实现数据源筛选;
在已存搜索下拉列表中,选择所需的已存搜索,实现数据源筛选;
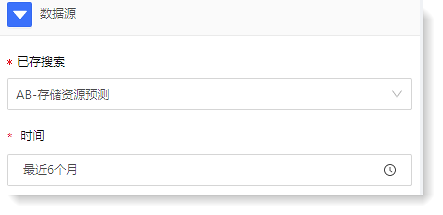
► *时间:用于对数据源进行时间过滤,支持快速选择和时间段选择;
► 度量:由聚合方式和聚合字段 2 个部分组成,表示需分析的影响维度;例:若需分析存储资源的已使用空间,则可选择计数+已使用空间;
► 度量:由聚合方式和聚合字段 2 个部分组成,表示需分析的影响维度;例:若需分析存储资源的已使用空间,则可选择计数+已使用空间;
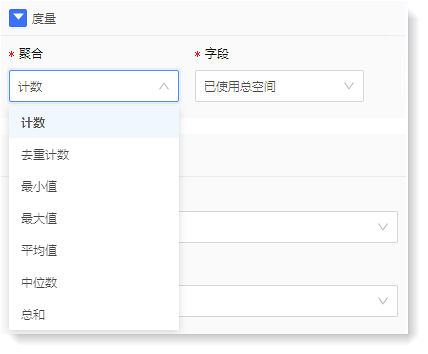
• *聚合:表示分析字段的聚合方式。对于 String 类型字段提供计数、去重计数、最小值、最大值、平均值、中位数、总和;对于非 String 类型字段提供计数和去重计数;
• *字段:表示需聚合的字段。
► 桶-*聚合:桶表示 X 轴的信息,聚合表示桶的类型,提供时间和词条2种:
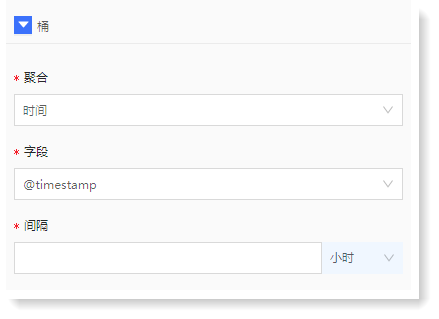
• 时间:表示 X 轴按照时间进行聚合,需设置时间字段和间隔;
• 词条:表示 X 轴按照词条进行聚合,需设置聚合字段和排序方式。
► 拆分字段:
表示是否需要按字段对所选数据进行分组计算。设置拆分字段后会根据字段和字段值对数据进行分组,并针对每组数据进行单独计算;若未设置拆分字段,则会对所有数据进行聚合,预览展示所有数据结果,如下所示:
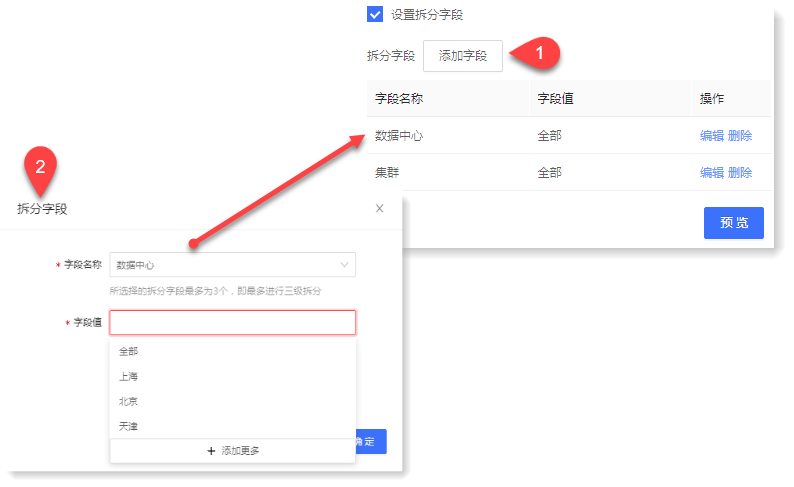
• 字段名称:表示需要拆分的字段,字段来源于已存搜索内已解析的字段。
• 示例:期望对不同数据中心、集群的已用存储空间值进行计算;
• 解析:以上实例中拆分字段为数据中心、集群字段,度量的聚合方式为计数,度量聚合字段则为已使用空间。
• 字段值:表示基于拆分字段,设置需展示的字段值。示例:拆分出来的数据中心结果,只想展示其中的两个数据中心,可在拆分字段值中添加这两个数据中心的字段值即可。
• 示例:期望对不同数据中心、集群的已用存储空间值进行计算;
• 解析:以上实例中拆分字段为数据中心、集群字段,度量的聚合方式为计数,度量聚合字段则为已使用空间。
• 字段值:表示基于拆分字段,设置需展示的字段值。示例:拆分出来的数据中心结果,只想展示其中的两个数据中心,可在拆分字段值中添加这两个数据中心的字段值即可。
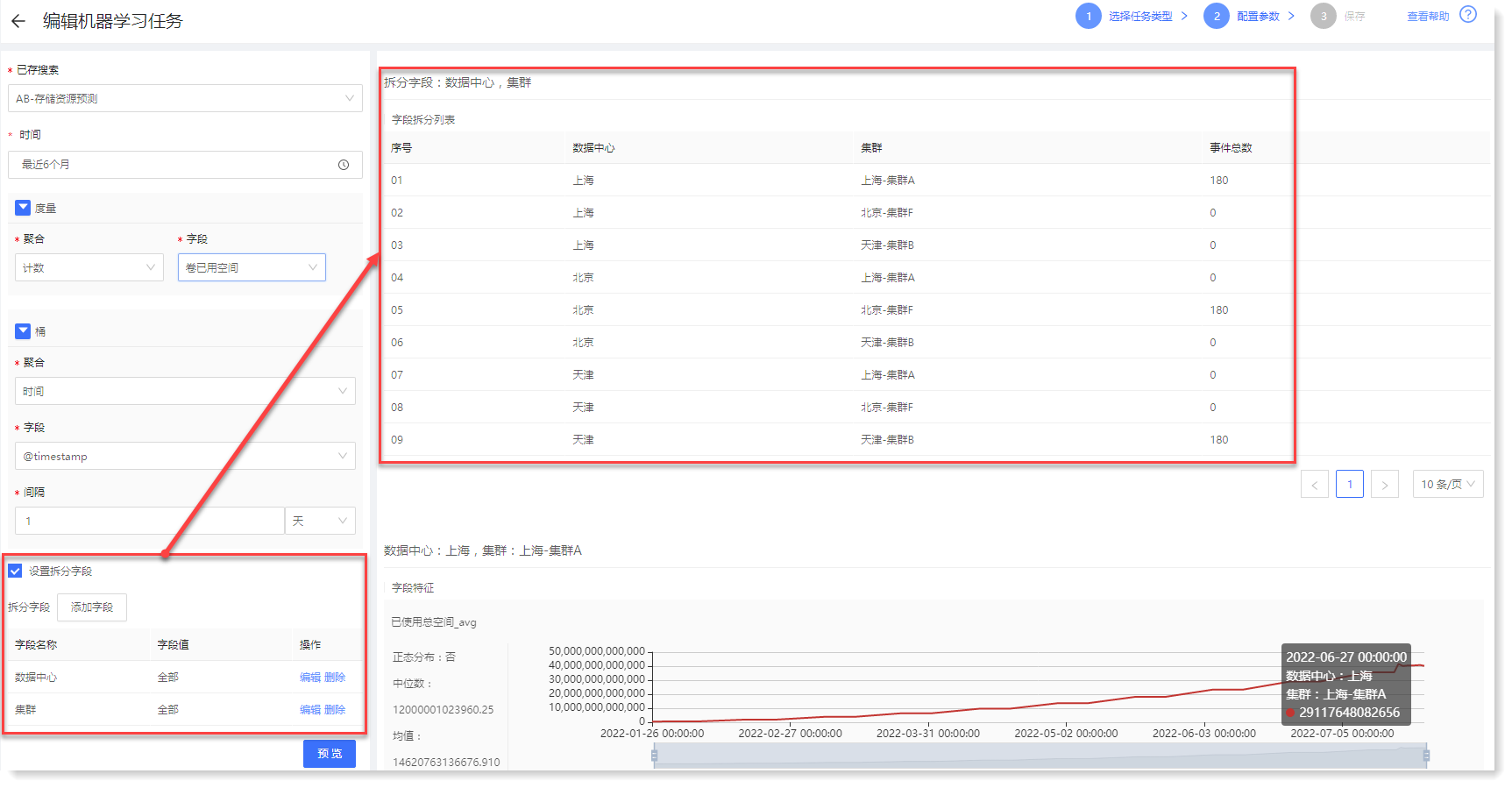
_58.png) 注意:最多只能添加3个拆分字段。
注意:最多只能添加3个拆分字段。参数配置完成后,点击【预览】可在右侧查看数据预览结果;若已拆分字段,则可查看拆分字段列表,点击拆分字段列表中的每一行都会展示其相应的趋势图,如下所示:
4. 配置数据预处理:
数据预处理用于提高数据的质量,以提升后续模型计算的精度和性能,具体配置如下:
1)配置数据预处理部分的*缺失值处理方法:通过选择不同的缺失值处理方法可以对数据中的缺失值进行填充,提升数据质量;
2)点击【应用】,执行成功后显示【查看结果】按钮,点击可查看数据预处理后的字段结果,如下所示: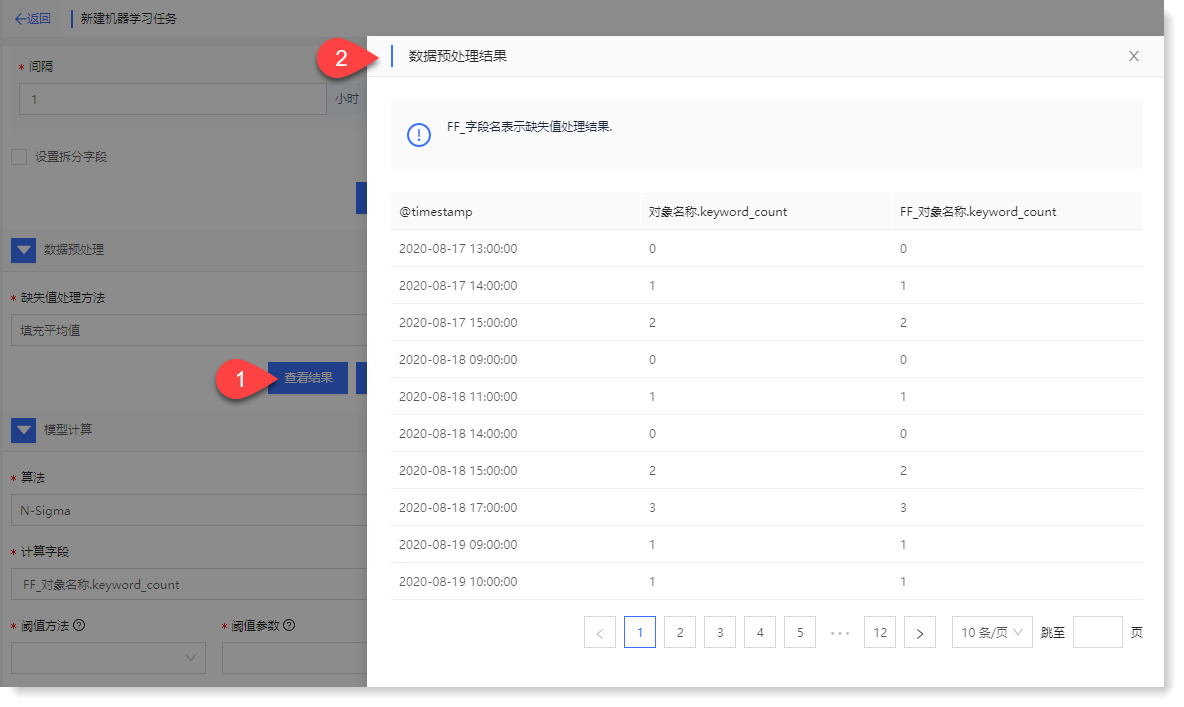
5. 配置模型计算:
单维度异常检测支持 N-Sigma 算法,用户可通过计算字段、阈值计算方法、阈值参数以及滑动窗口配置,实现数据模型计算。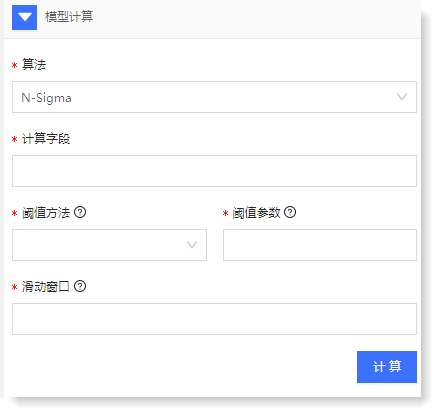
1)填写配置参数如下:
2)点击【计算】可查看单维度异常检测结果,如下所示: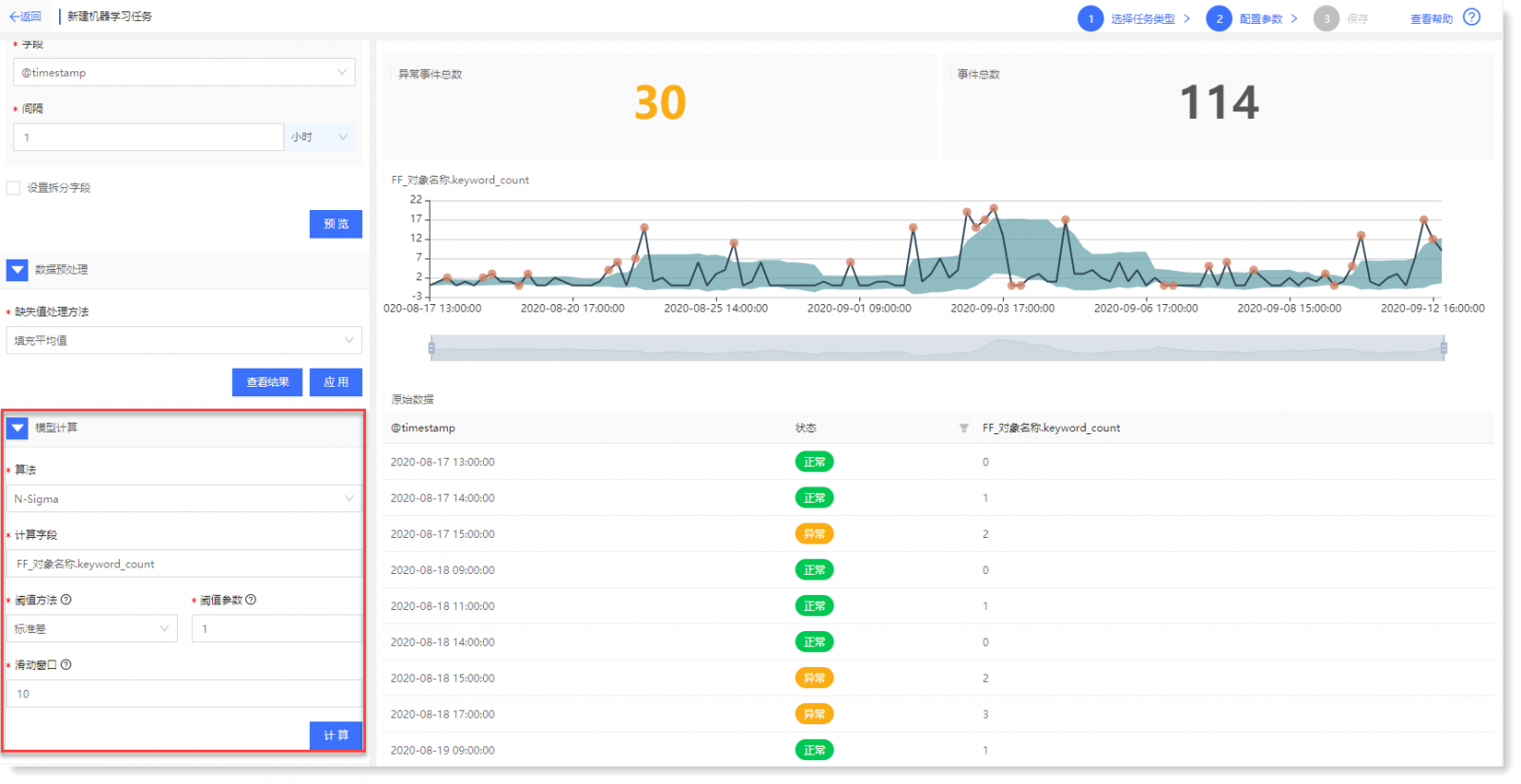
异常检测模型计算结果说明:
6. 完成上述所有配置后,点击【保存】填写机器学习任务名称,点击【确认】即可完成机器学习任务创建操作。
< 上一篇:
下一篇: >