更新时间:2022-08-13 21:23:29
多维度异常检测可基于多个影响维度的数据进行处理和计算,支持马氏距离模型算法。
一个完整的多维度异常检测分为 3 个部分:数据预览、数据预处理和模型计算:
• 数据预览:用于实现数据分析及分析维度的可视化展示;
• 数据预处理:包含缺失值处理以及预处理配置;
新建多维度异常检测,具体操作如下:
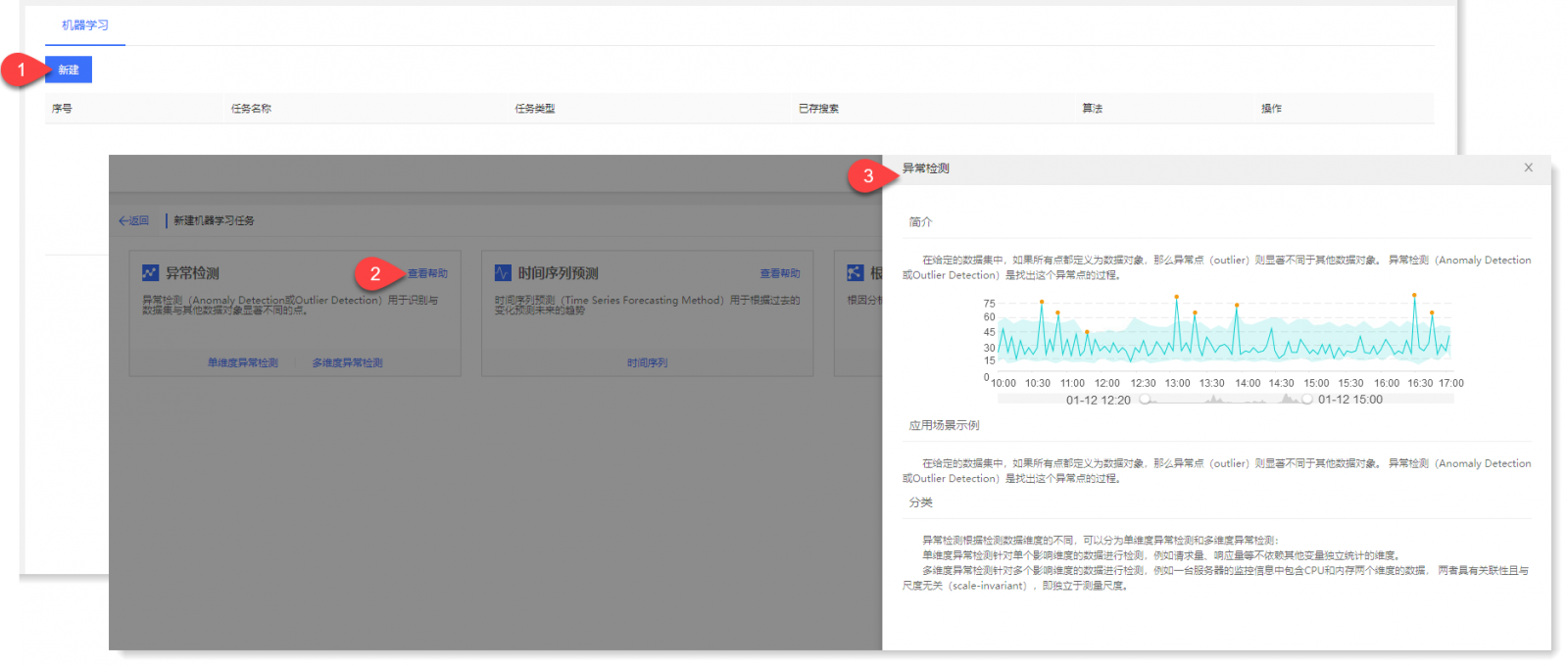
1. 进入机器学习页面,点击【新建】进入新建机器学习任务页面,点击【查看帮助】可查看异常检测机器学习任务的简介和应用场景示例,如下所示:
2. 点击【多维度异常检测】进入参数配置页面,点击右上角【查看帮助】可支持翻页查看多维度异常检测的简介、使用帮助、参数配置指导、算法介绍,如下所示:

3. 配置数据预览:
数据预览部分用于以可视化方式展示原始数据、数据统计信息以及趋势图。
1)配置数据预览:填写数据预览配置信息。多维度数据预览配置,除度量可添加多个字段外,其他与单维度异常检测配置一致,详细请参见 单维度异常检测 章节;
2)点击【预览】可查看数据预览结果,如下所示:
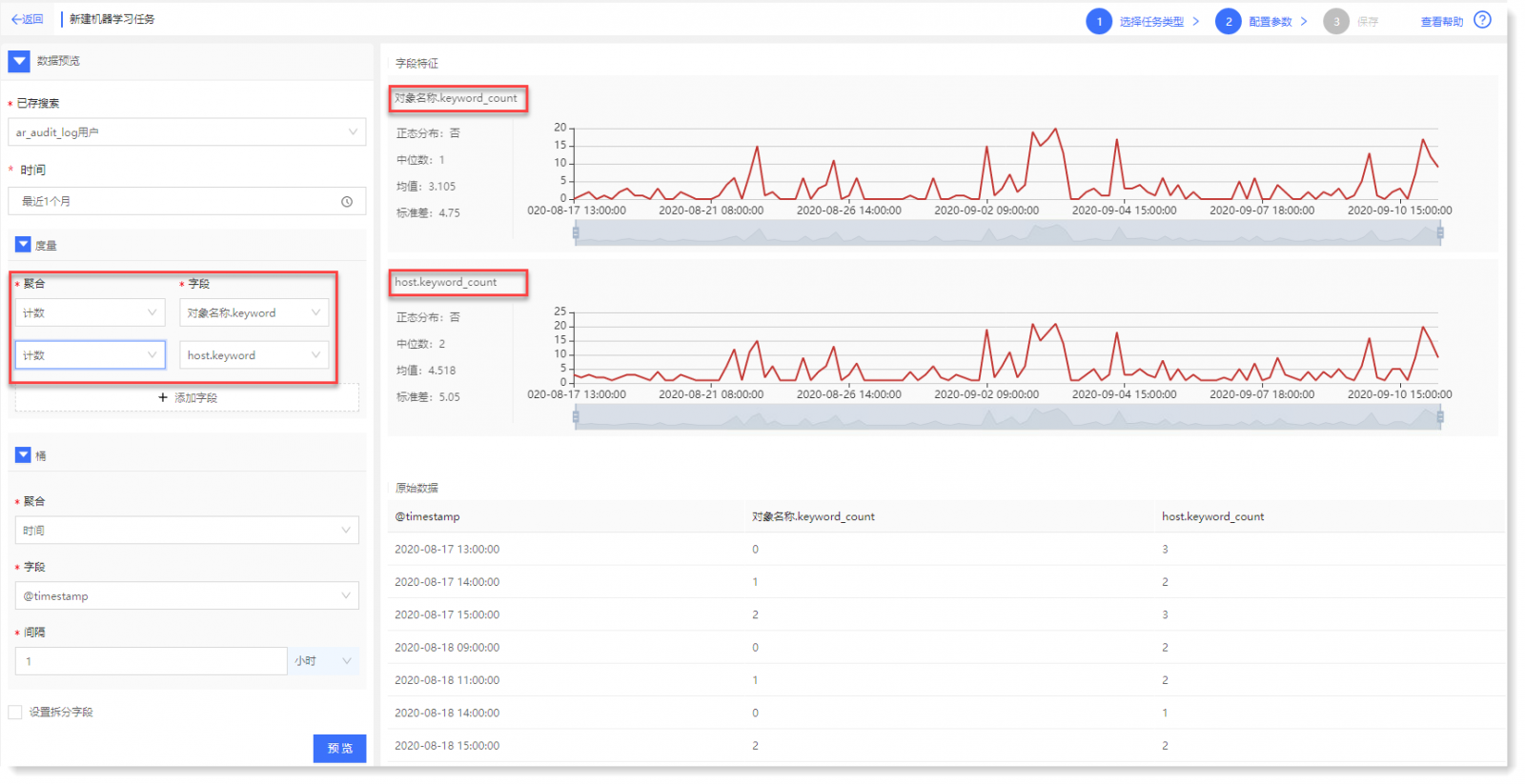
数据预览结果包括:统计信息、趋势图和原始数据列表,如下所示: 4. 配置数据预处理:
多维度异常检测数据预处理分为:缺失值处理和预处理 2 个部分,如下所示:
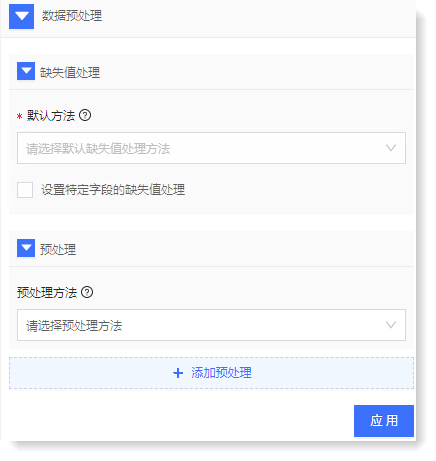
1)配置缺失值处理模块:通过选择不同的缺失值处理方法可以对数据中的缺失值进行填充,提升数据质量;
a) 配置默认方法:默认方法表示除特定字段的缺失值处理外,对其余所有字段均有效;
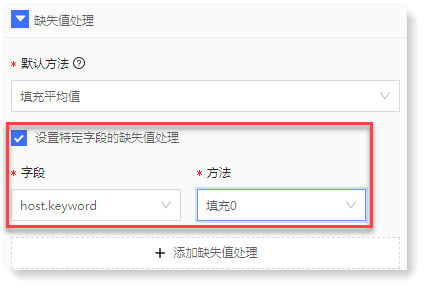
b) 若需对特定字段配置缺失值处理方式,可勾选设置特定字段的缺失值处理进行添加,如下所示:
2)配置预处理部分:可以选择不同的方法进行数据预处理。目前提供标准化和降维 2 种类型,可以添加多个预处理任务;
• 标准化:即方差计算,方差是平均值的对比。多维度异常检测支持极差标准化和 Z-Score 标准化 2 种;
• 极差标准化:极差又称范围误差或全距,用于统计数据中的变异点数量,极差值即为最大值与最小值之间的差距。极差标准化可体现一组数据波动的范围,极差越大,离散程度越大;
• Z-Score 标准化:即零-均值规范化,也称标准差标准化,是数据规范化处理的方式之一。可用于数据分布过于凌乱,无法判断最大值与最小值,或数据中心存在过多变异点的场景。
• 降维:一种能在减少数据集中特征数量的同时,避免丢失太多信息并保持或改进模型性能的方法,有助于数据可视化。多维度异常检测支持 PCA 和核化 PCA 两种:
• PCA:即 Principal Component Analysis 主成分分析,是一种分析、简化数据集的技术。目的是数据维数压缩,尽可能降低源数据的维度(复杂度),即从现有的大量变量中提取一组新的变量,但 PCA 会损失少量信息,可削减回归分析或聚类分析中特征的数量;
• 核化 PCA:即 Kernelized PCA,基于 PCA 增加了 Kernel 函数,以应对数据存在更高维的场景,通过 KPCA 可实现更高维度空间的 PCA 分析,对于在通常线性空间难以线性分类的数据点,可使用 KPCA 在更高维度寻找合适的高维线性分类平面。
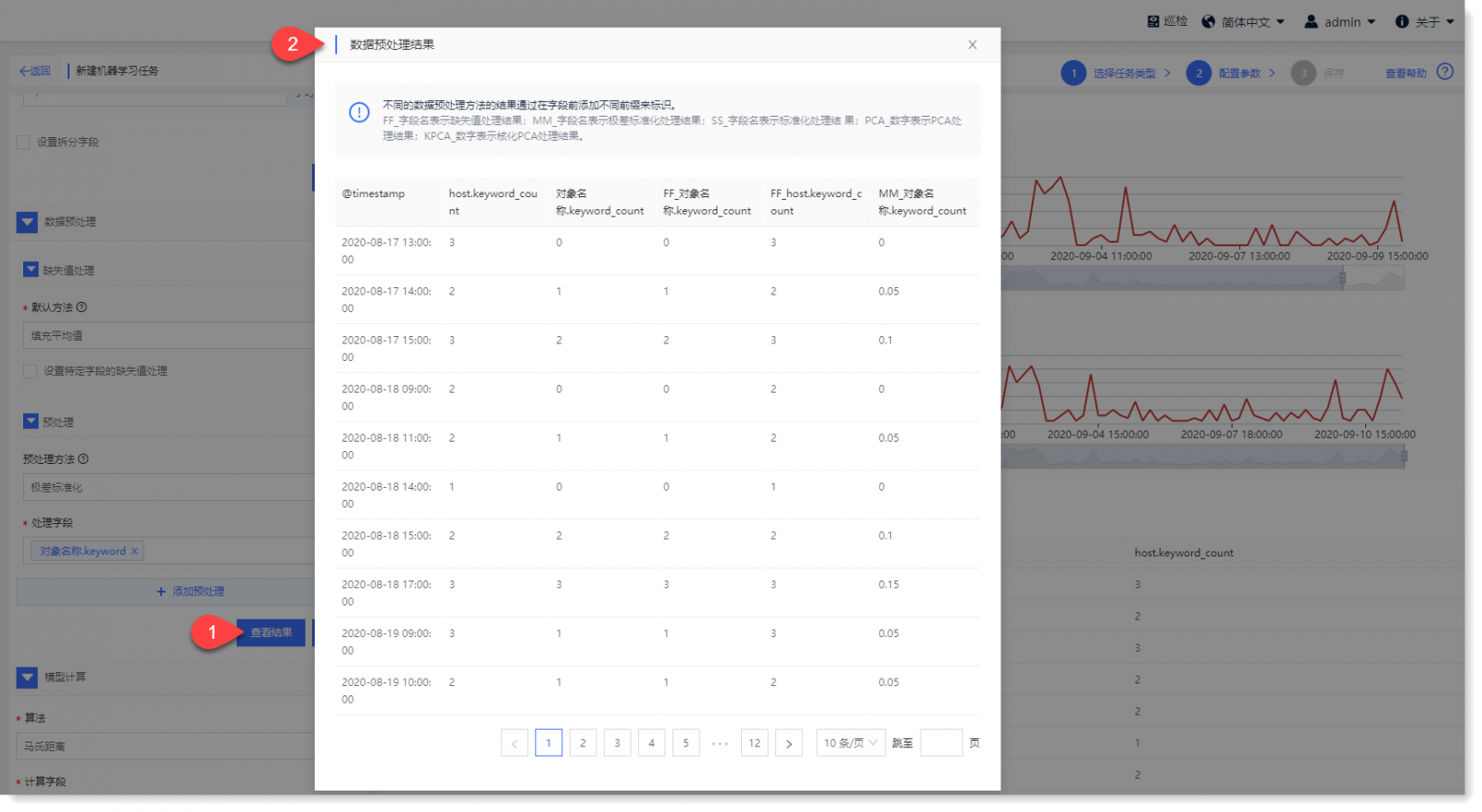
3)点击【应用】,执行成功后显示【查看结果】按钮,点击可查看数据预处理后的字段结果,如下所示:
5. 配置模型计算:
多维度异常检测支持马氏距离算法,用户可通过计算字段、阈值计算方法、阈值参数以及滑动窗口配置,实现数据模型计算。
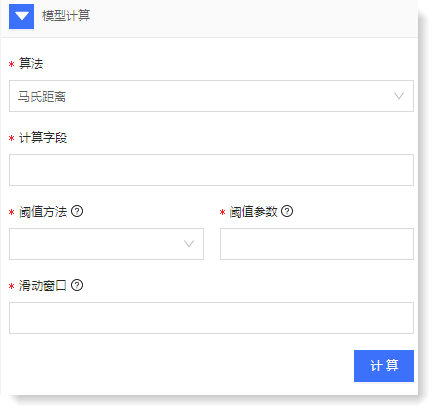
1)填写配置参数: 2)点击【计算】可查看多维度异常检测结果,如下所示:
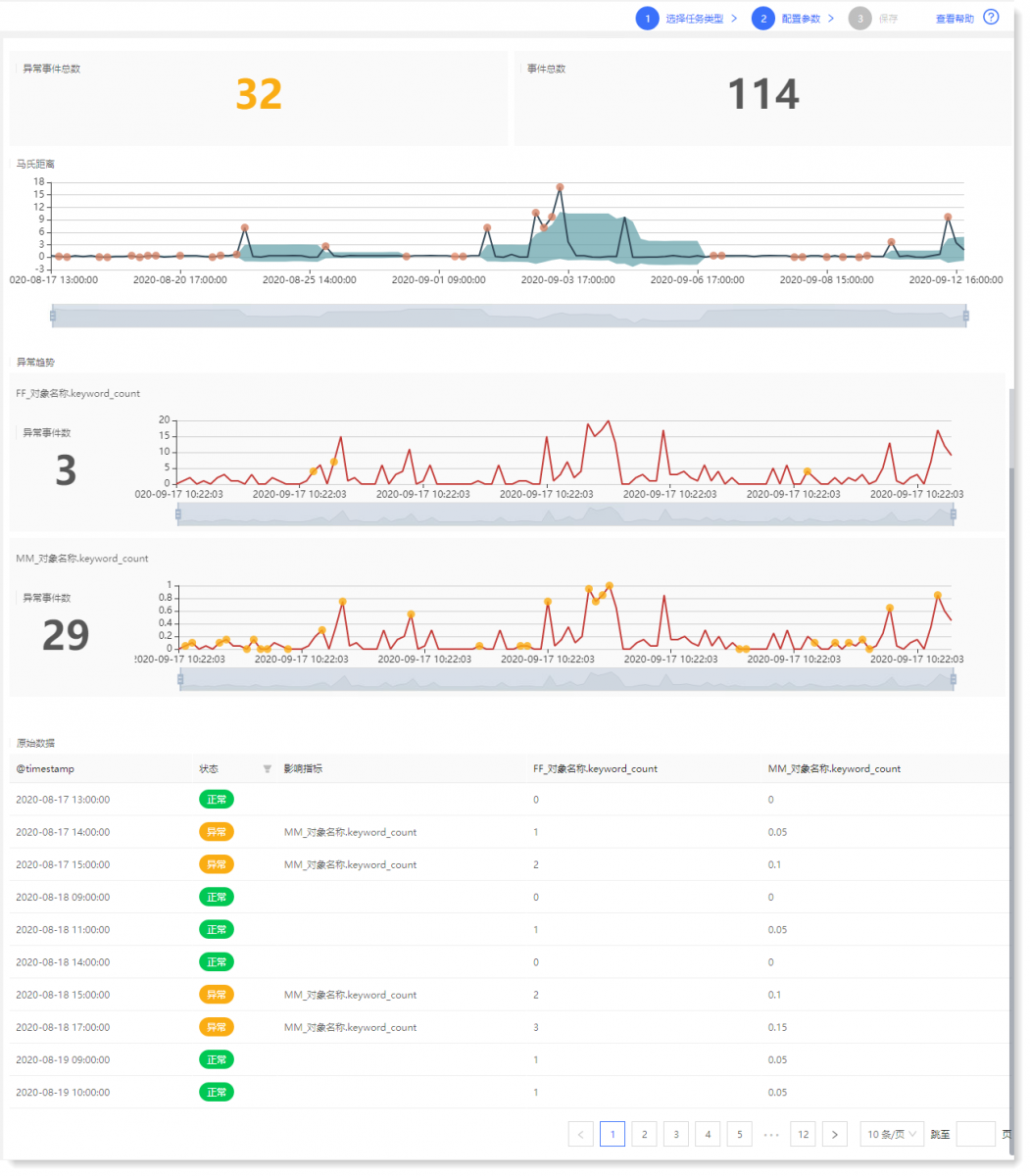
多维度异常检测模型计算结果说明: 6. 完成上述所有配置后,点击【保存】填写机器学习任务名称,点击【确认】即可完成机器学习任务创建操作。
一个完整的多维度异常检测分为 3 个部分:数据预览、数据预处理和模型计算:
• 数据预览:用于实现数据分析及分析维度的可视化展示;
• 数据预处理:包含缺失值处理以及预处理配置;
• 缺失值处理配置:提供 9 种不同的数据缺失值处理方法,可避免因数据缺失导致无法计算的情况;
• 预处理配置:用于提高数据质量,以提升后续模型计算的精度和性能。
• 模型计算:用于提供多种算法,可根据实际需求选择不同的算法及参数进行模型计算。• 预处理配置:用于提高数据质量,以提升后续模型计算的精度和性能。
新建多维度异常检测,具体操作如下:
1. 进入机器学习页面,点击【新建】进入新建机器学习任务页面,点击【查看帮助】可查看异常检测机器学习任务的简介和应用场景示例,如下所示:
2. 点击【多维度异常检测】进入参数配置页面,点击右上角【查看帮助】可支持翻页查看多维度异常检测的简介、使用帮助、参数配置指导、算法介绍,如下所示:
3. 配置数据预览:
数据预览部分用于以可视化方式展示原始数据、数据统计信息以及趋势图。
1)配置数据预览:填写数据预览配置信息。多维度数据预览配置,除度量可添加多个字段外,其他与单维度异常检测配置一致,详细请参见 单维度异常检测 章节;
2)点击【预览】可查看数据预览结果,如下所示:
数据预览结果包括:统计信息、趋势图和原始数据列表,如下所示: 4. 配置数据预处理:
多维度异常检测数据预处理分为:缺失值处理和预处理 2 个部分,如下所示:
1)配置缺失值处理模块:通过选择不同的缺失值处理方法可以对数据中的缺失值进行填充,提升数据质量;
a) 配置默认方法:默认方法表示除特定字段的缺失值处理外,对其余所有字段均有效;
b) 若需对特定字段配置缺失值处理方式,可勾选设置特定字段的缺失值处理进行添加,如下所示:
2)配置预处理部分:可以选择不同的方法进行数据预处理。目前提供标准化和降维 2 种类型,可以添加多个预处理任务;
• 标准化:即方差计算,方差是平均值的对比。多维度异常检测支持极差标准化和 Z-Score 标准化 2 种;
• 极差标准化:极差又称范围误差或全距,用于统计数据中的变异点数量,极差值即为最大值与最小值之间的差距。极差标准化可体现一组数据波动的范围,极差越大,离散程度越大;
• Z-Score 标准化:即零-均值规范化,也称标准差标准化,是数据规范化处理的方式之一。可用于数据分布过于凌乱,无法判断最大值与最小值,或数据中心存在过多变异点的场景。
• 降维:一种能在减少数据集中特征数量的同时,避免丢失太多信息并保持或改进模型性能的方法,有助于数据可视化。多维度异常检测支持 PCA 和核化 PCA 两种:
• PCA:即 Principal Component Analysis 主成分分析,是一种分析、简化数据集的技术。目的是数据维数压缩,尽可能降低源数据的维度(复杂度),即从现有的大量变量中提取一组新的变量,但 PCA 会损失少量信息,可削减回归分析或聚类分析中特征的数量;
• 核化 PCA:即 Kernelized PCA,基于 PCA 增加了 Kernel 函数,以应对数据存在更高维的场景,通过 KPCA 可实现更高维度空间的 PCA 分析,对于在通常线性空间难以线性分类的数据点,可使用 KPCA 在更高维度寻找合适的高维线性分类平面。
3)点击【应用】,执行成功后显示【查看结果】按钮,点击可查看数据预处理后的字段结果,如下所示:
5. 配置模型计算:
多维度异常检测支持马氏距离算法,用户可通过计算字段、阈值计算方法、阈值参数以及滑动窗口配置,实现数据模型计算。
1)填写配置参数: 2)点击【计算】可查看多维度异常检测结果,如下所示:
多维度异常检测模型计算结果说明: 6. 完成上述所有配置后,点击【保存】填写机器学习任务名称,点击【确认】即可完成机器学习任务创建操作。
< 上一篇:
下一篇: >