




















新建任务流程
1.进入“Benchmark”页面,左侧菜单选中“Benchmark任务”。单击【新建】按钮,进入新建任务流程。

2.填写如下信息:
| 参数 | 说明 |
| 任务名称 | 名称只能由中英文、数字、特殊字符组成,长度为1-50位。 |
| Benchmark配置 | 支持用户选择Benchmark配置。 |
| 算法类型 | 支持用户选择大模型、小模型、自定义应用、外部接入。 |
| 选择算法 | 详见下文。 |
| Adapter文件 | 上传的文件格式仅支持要求python,且单个文件大小不超过2M。 |
| 描述 | 描述只由中英文、数字、特殊字符组成,长度为0-255位。 |
| 颜色 | 单击选择任务颜色。 |
3.选择算法
(1)大模型:选择一个大模型和一个提示词为一组算法
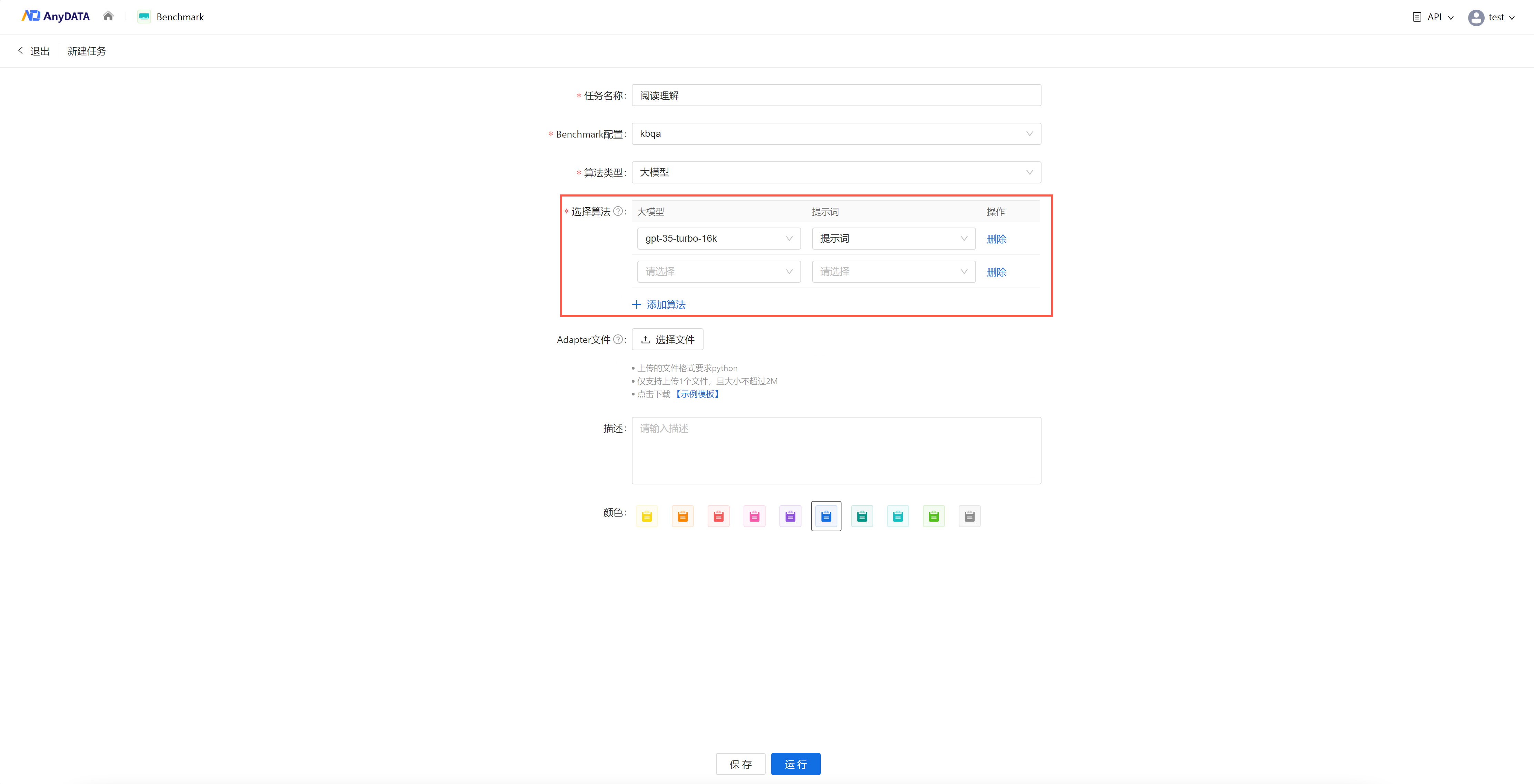
- 单击【添加算法】,新增一行以选择算法
- 单选大模型和单选提示词
- 单击【删除】,删除该行算法
(2)小模型:支持选择多个小模型

(3)自定义应用:支持选择多个自定义应用
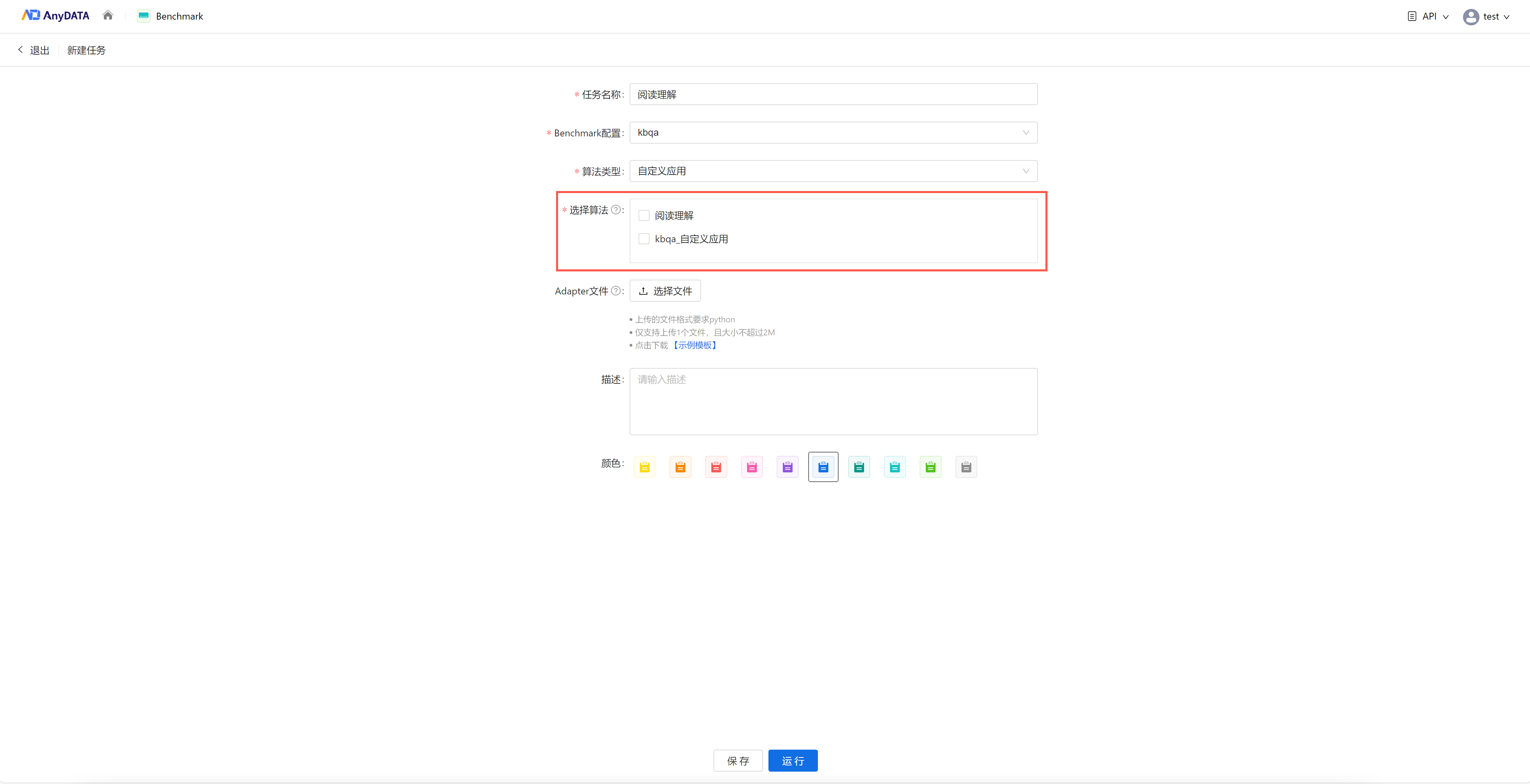
(4)外部接入:每个算法需要输入算法名称和URL

- 单击【添加算法】,新增一行输入算法名称和URL
- 参数说明
| 参数 | 说明 |
| 算法名称 | 名称只能由中英文、数字、特殊字符组成,长度为1-50位。 |
| URL | URL只能由英文、数字及键盘上的特殊字符组成,长度为1-150位。 |
- 单击【删除】,删除该行算法
4.Adapter文件上传
(1)单击【选择文件】按钮,出现系统对话框,选择需要上传的文件
(2)文件上传完成,可在下方预览文件内容
(3)悬停文件时出现删除按钮,单击【删除】以删除文件
5.填写完信息后,可以选择保存任务或者运行任务:
- 单击【保存】,保存任务
- 单击【运行】,运行任务
Adapter如何编写
注意:Adapter用于适配数据集、算法、指标的输入输出格式,使数据可以顺利流转。Benchmark任务中Adapter是将数据集Input转换为算法的Input。Adapter编写格式主要取决于算法的Input。
| 算法 | 情况 | Adapter |
| 提示词+大模型 | 数据的Input和提示词的参数完全一致 | ❌无需配置 |
| 提示词+大模型 | 数据的Input和提示词的参数不一致 | ✅ 手动修改配置 |
| 小模型、自定义应用、外部接入 | 数据中只能存在一个Input | 可能存在配置情况 |
注意事项
1.内置的Adapter会将所有数据转化为字符串格式。若需要保留原始格式:
(1) 单击下载【示例模板】,在示例中将如下片段代码删除

(2)并替换为下方代码片段
dictInfo[column_name] = info[column_name]
2.内置的Adapter会将所有数据转化为键值对。若不需要键值对数据结构:
(1)将文件如下片段代码删除

(2)并替换为下方代码片段

场景一:提示词+大模型(数据的Input与提示词的参数完全一致)
1.test数据示例:
| language | content |
| 中文 | apple |
| 中文 | banana |
| 英文 | 苹果 |
| 英文 | 香蕉 |
2.提示词:
下面我让你来充当翻译家,你的目标是把任何语言翻译成{{language}},请翻译时不要带翻译腔,而是要翻译得自然、流畅和地道,使用优美和高雅的表达方式。请翻译下面这句话{{content}}
3.使用以上数据和提示词时,无需编写Adapter。
4.此时,Adapter输出结果如下:

场景二:提示词+大模型(数据的Input与提示词的参数不一致)
1.翻译数据示例:
| 语言 | 内容 |
| 中文 | apple |
| 中文 | banana |
| 英文 | 苹果 |
| 英文 | 香蕉 |
2.翻译工具提示词:
下面我让你来充当翻译家,你的目标是把任何语言翻译成{{language}},请翻译时不要带翻译腔,而是要翻译的自然、流畅和地道,使用优美和高雅的表达方式。请翻译下面这句话{{content}}
3.编写Adapter
(1)Benchmark任务选择算法时,大模型选择“AISHU READER”,提示词选择“翻译器”
(2)单击下载【示例模板】,在示例中找到“对数据进行处理”。并将示例中

替换为如下,即可完成Adapter编辑。

4.Adapter输出结果

注意事项:
(1)若未选择Benchmark配置或算法并直接下载示例,则需要手动将“DatasetName”替换成数据集名称、“AlgorithmName”替换为算法名称
(2)若配置数据集名称中含除中文、英文及数字以外的字符,系统将自动替换为“_”
