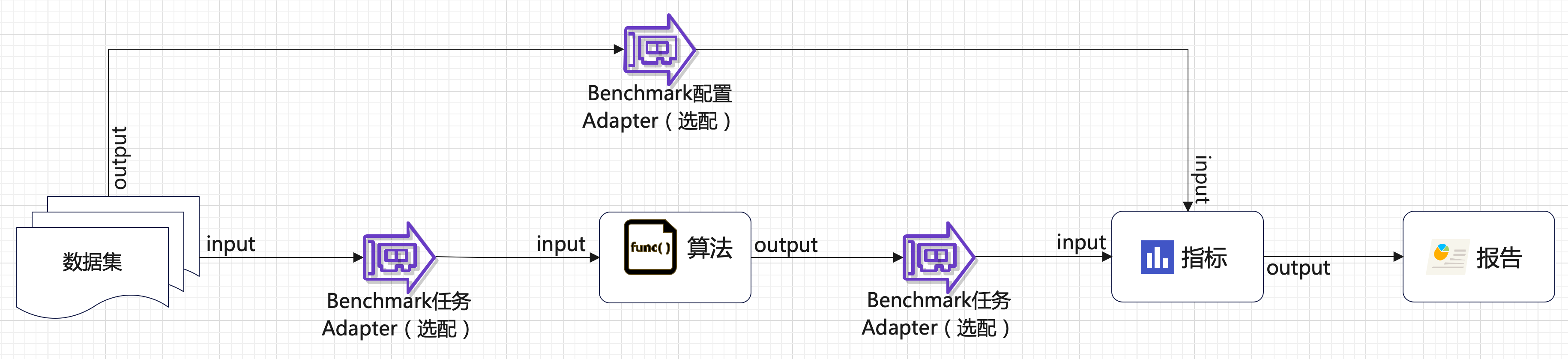
流程介绍
(1)添加大模型 –> (2)添加Prompt –> (3)准备/上传测试数据集 –> (4)添加Benchmark配置 –> (5)添加Benchmark 任务 –> (6)运行评测任务,查看日志/报告
(1)数据集
需要包含输入数据(input)、期望的数据结果/金标准(output),input传递给测试对象(即算法)作为输入,output作为评测指标传递给Metric。数据通过数据集模块上传/管理。
(2)内置指标(Metric)
内置指标有7种,其中intelliqa_keypoint、intelliqa_answer、long_bench、matc以及fuzzy_match为大模型评估指标,model_ie和kbqa为内置小模型评估指标。具体说明如下:
| Metric名称 | intelliqa_keypoint |
| 描述 | 评估模型的问答能力:将模型返回答案与数据集中keypoints字段进行匹配,如果符合要求则判定为回答正常,否则回答错误。acc越高则表示回答正确的问题数越多,所以acc越高越好。 |
| 输入参数说明 |
Keypoints:数据集中理想结果字段。 数据示例: {"$and": ["周转率","损耗率","标准化率"]} -- 理想结果需要同时包含3个关键字 {"$or": ["1m", "1米"]} -- 理想结果需要包含其中1个 {"$or":[{"$and": ["大鼠","犬"]},{"$and": ["大鼠","狗"]}]} -- 组合形式,理想结果希望包含其中一组答案 answer:内置benchmark任务 adapter将模型返回答案以list形式提供给内置metric的参数 |
| 指标输出 |
average_ans_len:平均答案长度 sample_num:样例个数 answer_num:有回答个数 model_predicts_no_answer:模型返回无答案的精确率,公式:(数据集keypoints、模型返回均无答案的数量)/模型返回无答案数量 model_predicts_an_answer:模型返回有答案的精确率,公式:(模型返回有答案且答案正确的数量)/模型返回有答案总数 ground_truth_no_answer:无答案问题的召回率,公式:(数据集keypoints、模型返回均无答案的数量)/数据集预期无答案的数量 ground_truth_have_an_answer:有答案问题的召回率,公式:(模型返回有答案且答案正确的数量)/数据集预期有答案的问题数量 reject_rate:拒答率(有答案的情况下),公式:(数据集有答案、模型返回无答案的数量)/数据集预期有答案的问题数量 acc:准确率,回答正确问题数量/总问题数量 |
| Metric名称 | intelliqa_answer |
| 描述 | |
| 输入参数说明 |
ground_truth: answer: 内置benchmark任务 adapter将模型返回答案以list形式提供给内置metric的参数 |
| 指标输出 |
verage_ans_len:平均答案长度 sample_num:样例个数 answer_num:有回答个数 model_predicts_no_answer:模型预测无答案的精确率,公式:(预期无答案,同时模型返回无答案的数量)/模型返回无答案数量 ground_truth_no_answer:无答案问题的召回率,公式:(预期无答案,同时模型返回无答案的数量)/预期无答案的数量 reject_rate:拒答率(有答案的情况下),公式:(预期有答案,模型返回无答案的数量)/预期有答案的问题数量 rouge_l:rouge-l方法计算出的rouge f1_score:f1值,精确率和召回率的调和平均数 f1_r:f1 值的一种变体,通常用于处理类别不平衡的情况 |
| Metric名称 | long_bench |
| 描述 | |
| 输入参数说明 |
correct_answers: answer:内置benchmark任务 adapter将模型返回答案以list形式提供给内置metric的参数 |
| 指标输出 | score:longbench得分,rouge |
| Metric名称 | match |
| 描述 | |
| 输入参数说明 |
ideal: answer:内置benchmark任务 adapter将模型返回答案以list形式提供给内置metric的参数 |
| 指标输出 | accuracy:准确率, 正确个数/总数 |
| Metric名称 | fuzzy_match |
| 描述 | |
| 输入参数说明 |
correct_answer:数据集中的正确答案,类型为list[str] algorithm_answer:算法计算得出的答案,类型为list[str] |
| 指标输出 |
accuracy:准确率, 正确个数/总数 f1_score:f1值,精确率和召回率的调和平均数 f1_r:f1 值的一种变体,通常用于处理类别不平衡的情况。 |
| Metric名称 | model_ie |
| 描述 | |
| 输入参数说明 |
dataset_spos: 来自数据集本身的标准答案,类型为list[map],需要有o_text键 spos: 算法得出的答案,类型为list[map],需要有o_text键 |
| 指标输出 |
accuracy:准确率, 正确个数/总数 |
| Metric名称 | kbqa_intent |
| 描述 | |
| 输入参数说明 |
Ideal: 理想的答案,来自数据集,类型为list[list[str]] Answer: 算法给出的答案,类型为list[list[str]] |
| 指标输出 |
accuracy:准确率, 正确个数/总数 |
(3)Benchmark配置 Adapter:使用内置metric时无需上传
(4)算法:即评测对象,DIP Benchmark支持评测的对象支持:
- 大模型:指通过 DIP 模型工厂添加/管理的大模型
- 小模型:指 DIP 模型工厂中内置的小模型
- 自定义应用:指DIP认知应用模块中开发的自定义应用服务
- 外部接入:除了以上3中DIP内部的算法外,还可支持直接对接外部API评测算法。
(5)Benchmark任务 Adapter:使用内置Metric时无需上传
(6)报告:展示Metric评测结果
最佳实践之对接大模型
本章节以爱数发布的AishuReader v2大模型为例。
进入【模型工厂】-【大语言模型】- 点击【新建】,输入配置信息后点击【测试连接】,测试成功后点击【保存】,模型会在列表中展示,模型添加完成。
进入【模型工厂】-【提示词模板】- 点击【新建】,输入对应信息后点击【保存】:
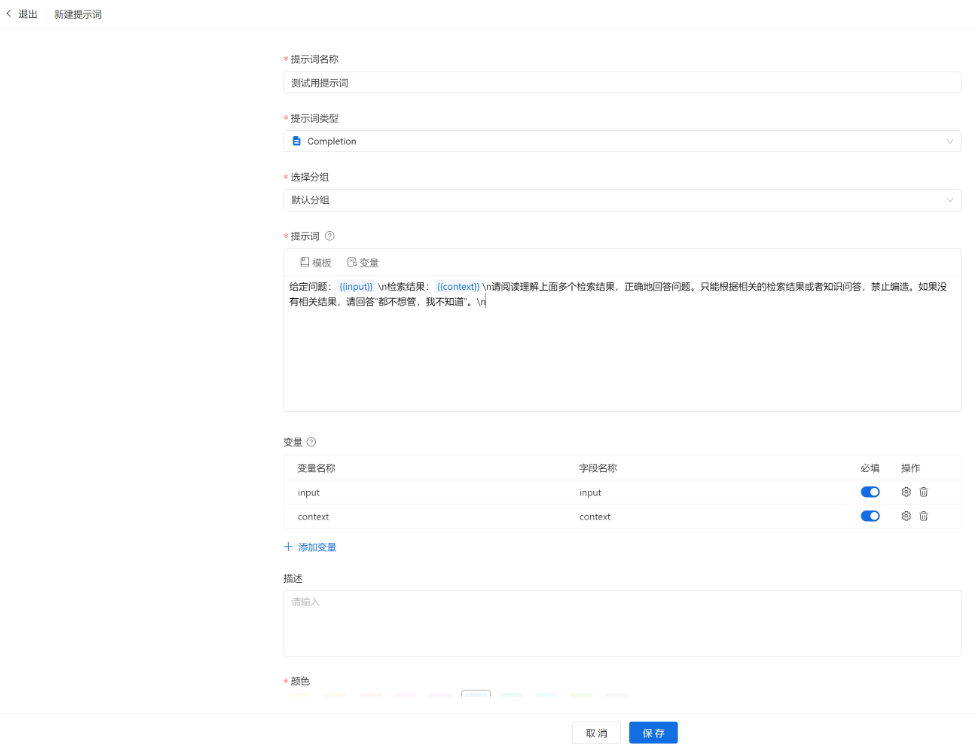
内置Metric只要数据集符合要求即可直接使用内置Adapter,省去写Adapter的过程。不同Metric的数据集格式不同,以下为intelliqa_keypoint数据集格式:
l 数据集文件格式为“.jsonl”,内容参考如下

l 上传数据集:进入【数据集】,点击【新建】,输入数据集名称和描述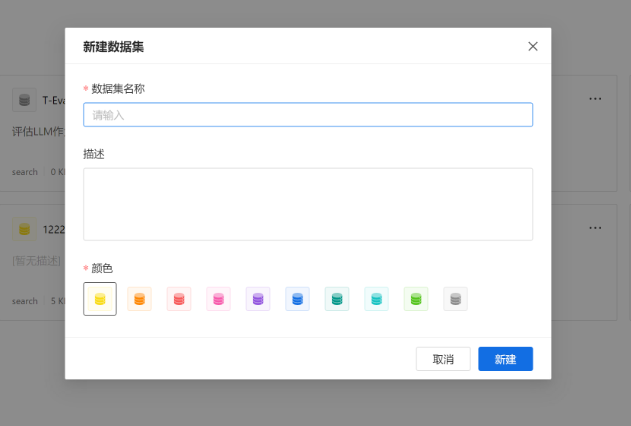
l 编辑数据集描述,切换至【文件与版本】上传文件
注意:本地需要有eceph存储地址证书才能正常访问,如无证书需要先访问eceph存储地址,浏览器添加信任后才能上传成功
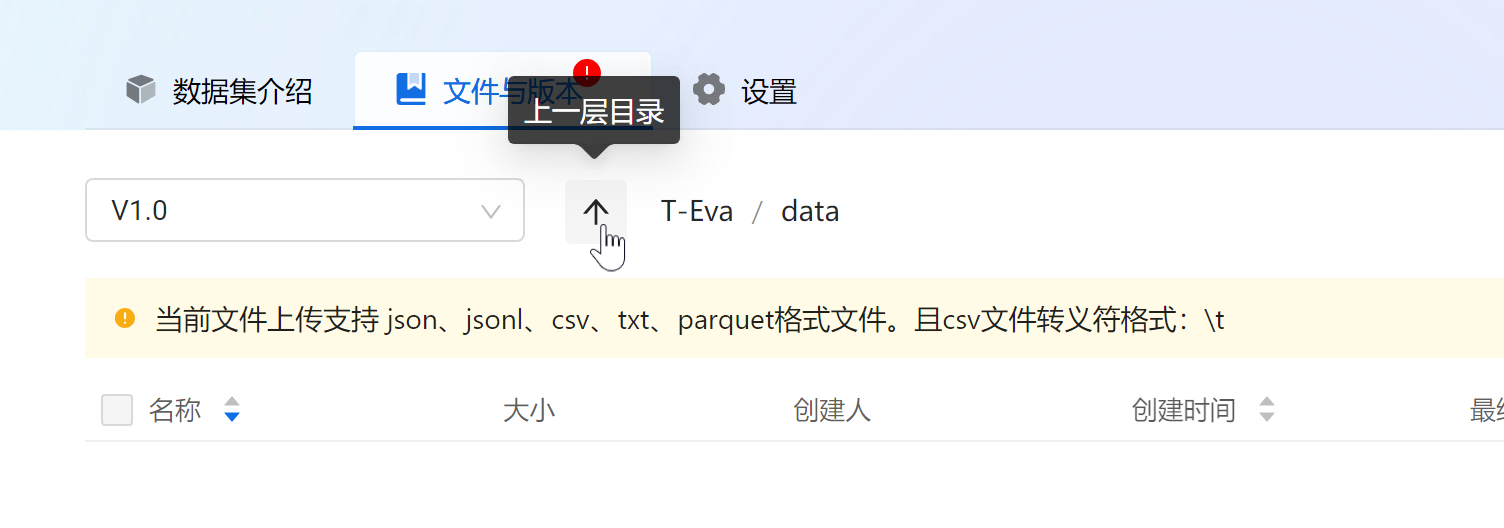
l 预览数据集:点击文件列表中文件名即可预览文件内容,点击“↑”返回上一层
大模型、Prompt、数据集配置完成后,可进入Benchmark配置,具体配置步骤如下:
(1)新建Task
(2)选择数据集
说明:报告中一个Task一条测试结果,一个Task若包含多个测试文件最终会合并为1条结果
(3)选择内置Metric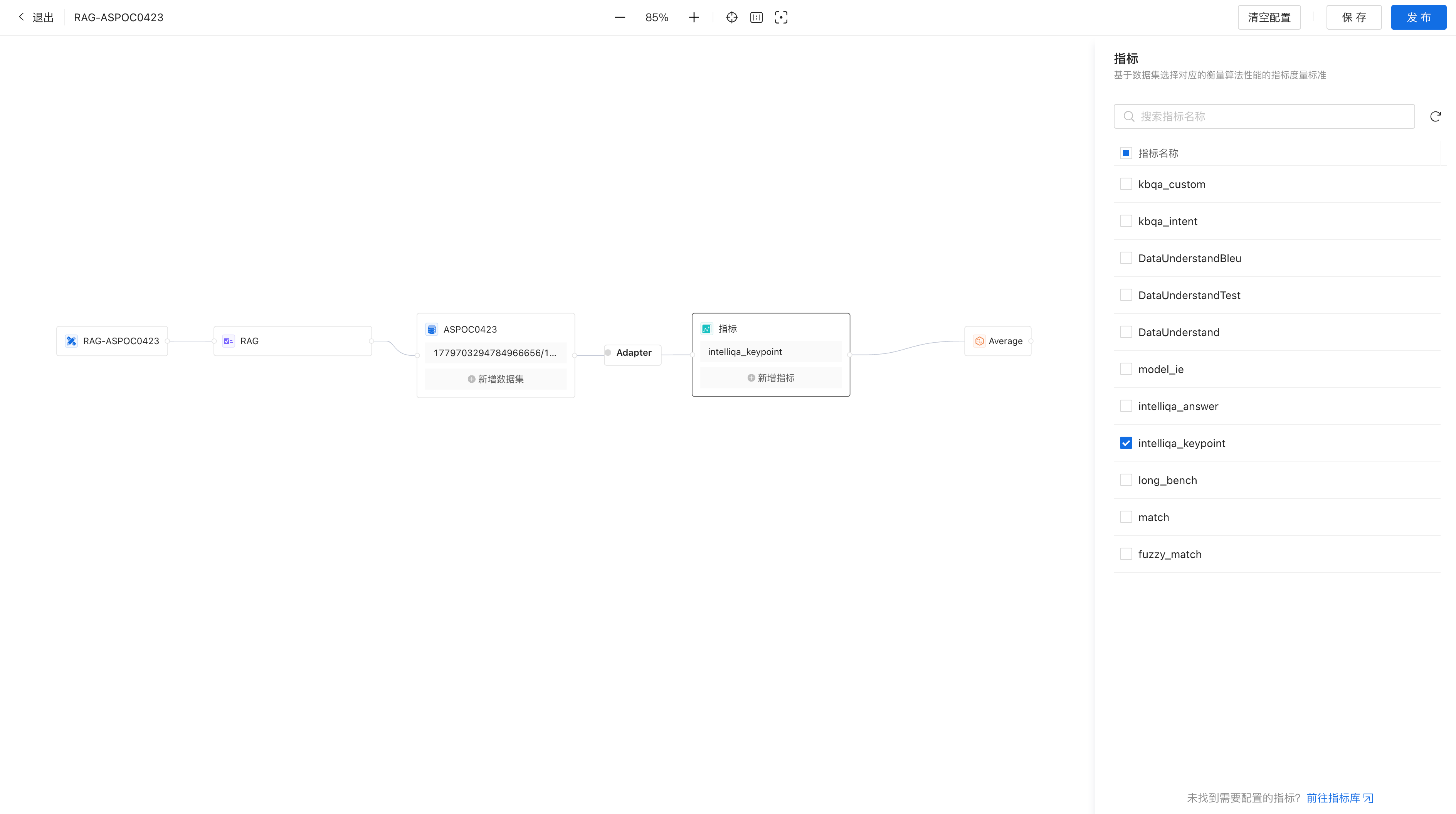
注意:
为保证Benchmark评测的公正性已发布的配置不允许再编辑,故配置完成后建议只保存不发布,等评测任务测试完成后再考虑发布
Benchmark配置完成后,该Benchmark的测试数据集和指标都已确定,接下来是配置Benchmark任务。
(1)添加任务
进入【Benchamark】-【Benchmark任务】新建任务,输入任务名后,
1) 选择对应Benchmark配置、算法类型、评测算法和对应提示词:
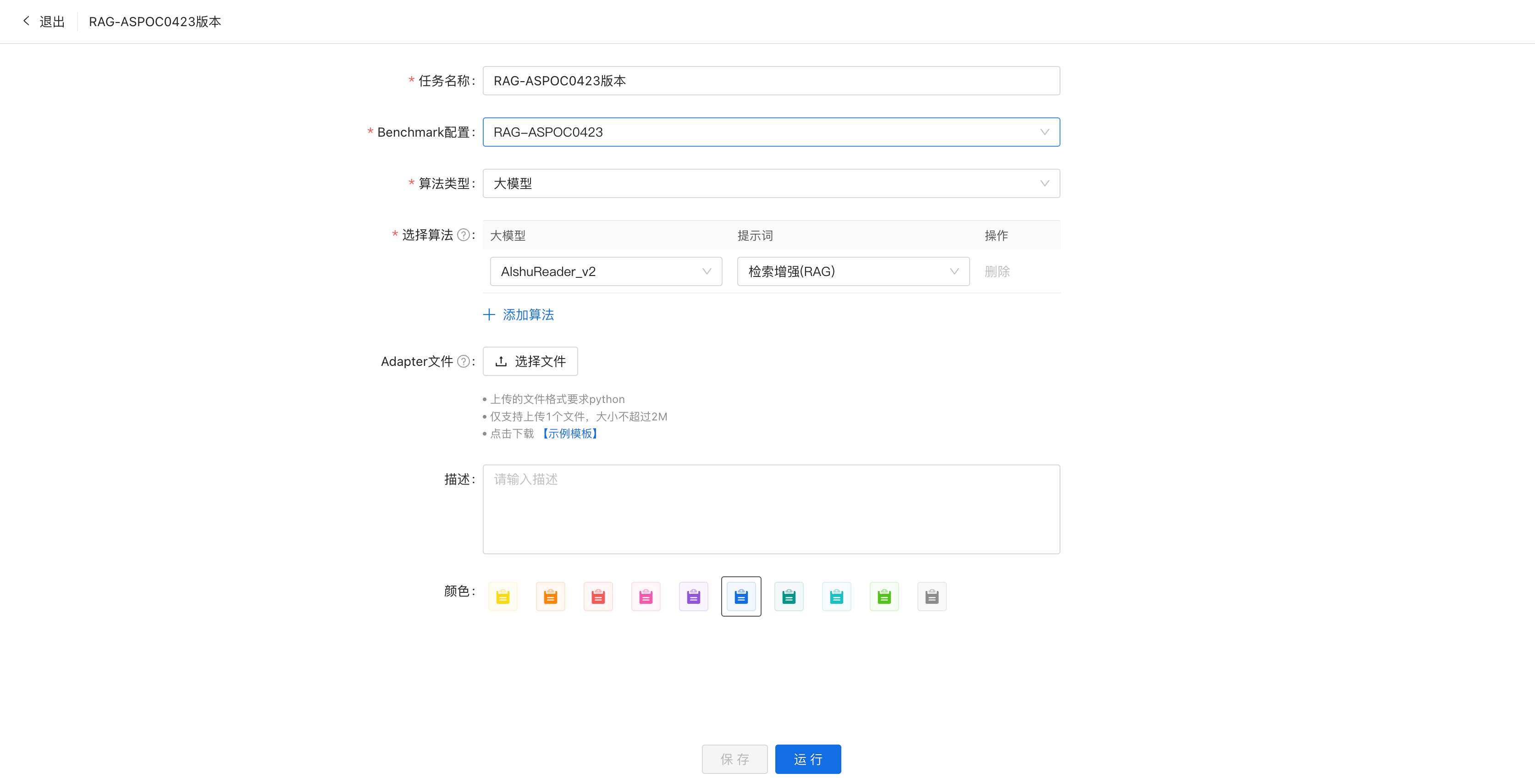
2) 点击运行
(2)查看任务
点击如下区域可查看构建任务:
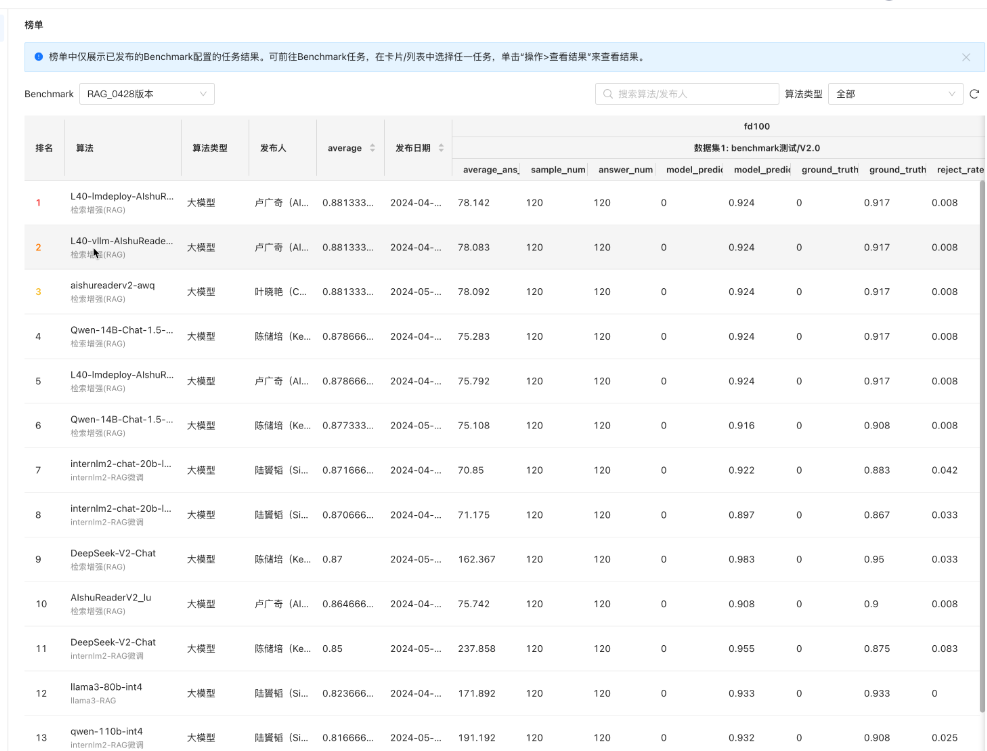
(3)榜单
注意:只有Benchmark配置为“已发布”状态的任务完成后才会进入榜单,其他状态的运行结果可在任务中查看:
稳定的且已发布的Benchmark配置运行出来的任务可在榜单中对比不同模型下的测试结果