更新时间:2024-06-03 14:14:23
模型简介
本模型是基于Qwen 1.5框架的最新微调版本,专注于进一步优化检索增强生成器(RAG)以及特别提升处理Markdown格式表格的能力。相比之前发布的AIshu-Reader-v1.0版本,该模型在特定任务上展现出了显著的性能提升。
技术创新与特性
检索增强生成器(RAG)优化
- 高质量微调数据:为了优化RAG任务处理能力,我们采用了ChatGPT生成了高质量数据。通过精心设计的拒答数 据集和指令模板,显著减少了模型的幻觉现象,提高了答案的相关性和准确性。在构建训练数据时,经过多种不同指令模板实验,最终选定效果 最优的模板进行数据生成。
- 偏好数据构造与DPO策略:利用线上日志数据,结合多个开源模型生成的答案,构建了偏好数据集。采用直接偏好优化(DPO)训练策略优化和对齐模型的回答偏好,从而确保回答的多样性和准确性。
Markdown表格处理能力
- COT思维链优化:针对Markdown格式表格问答任务,实施了COT(Chain of Thought)思维链方案,模拟人类解决问题的逻辑思维过程,以提高问题解答的深度和准确性。
- Markdown格式优化:统一表格表示格式,增强了模型解析和理解Markdown表格的能力,尤其是在处理复杂查询时的性能。
Benchmark数据集介绍
RAG任务数据集
- InternalQA RAG Dataset (IntQA-RAG):基于企业内部文件制作的问答数据集,为模型提供了丰富的行业特定问题和答案。
- InternalQA RAG Dataset (IntQA-RAG):基于企业内部文件制作的问答数据集,为模型提供了丰富的行业特定问题和答案。
表格问答数据集
- China Book Awards Table Dataset (CBATD):涵盖历届中国图书政府奖获奖信息的Markdown表格数据集,用于评估模型在特定领域表格数据处理的精准性。
- NL2SQL Markdown Dataset (N2S-MD):将公开的NL2SQL数据集转换为Markdown格式,专为测试模型在从自然语言查询到表格数据检索的能力而设计。
评估结果 Evaluation
展示模型微调后的性能评估结果,包括特定任务的Benchmark及通用能力数据集上的对比,证明模型在提升特定任务能力的同时,保持其通用处理能力。
特定任务数据集评估
| model | IntQA-RAG | PubDocs-RAG | CBATD | N2S-MD |
| GPT4-32k | 82.3 | 94.16 | 86.58 | 64.93 |
| Yi-34B-Chat | 61.9 | 75 | 70.73 | 72.3 |
| Qwen-14B-Chat-1.5 | 71.49 | 82.5 | 67.07 | 78.64 |
| Qwen-32B-Chat-1.5 | 76.419 | 87.5 | 71.95 | 77.6 |
| Baichuan2-13B-Chat | 68.55 | 62.5 | 65.85 | 53.81 |
| AIshu-Reader-14B-v1 | 66.3 | 78.3 | 59.7 | 73.7 |
| AIshu-Reader-14B-v2.0 | 86.24 | 91.66 | 81.7 | 80.03 |
通用能力保持评估
| model | Ceval | Cmmlu |
| Qwen-14B-Chat-1.5 | 75.48 | 76.63 |
| AIshu-Reader-14B-v2.0 | 73.03 | 72.43 |
要求(Requirements)
- python 3.9及以上版本
- pytorch>=1.13.1 推荐2.0及以上版本
- 建议使用CUDA 12.2及以上
- transformers >=4.37.2
附录
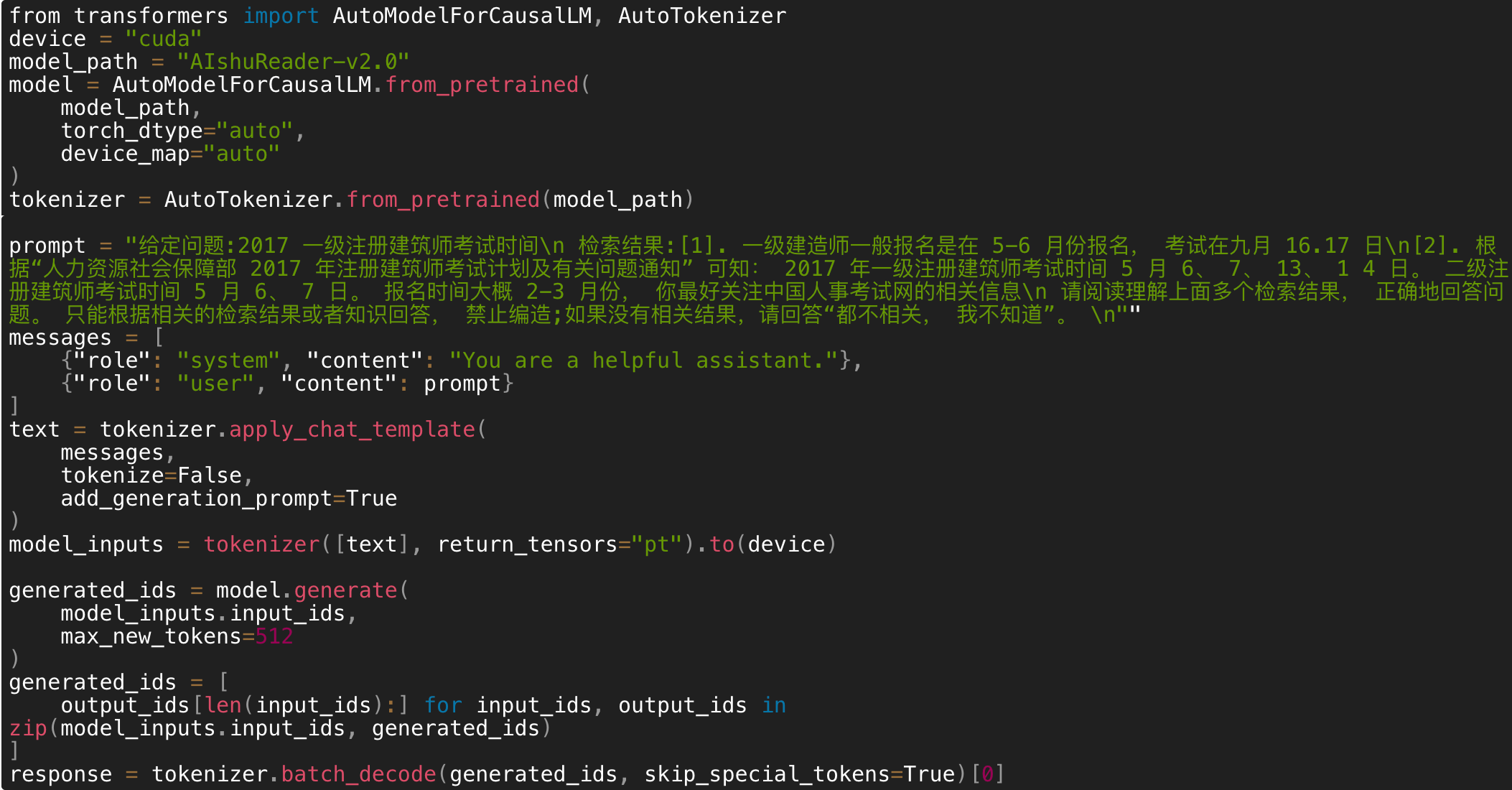
Prompt 参考
1.检索增强(RAG)
![]()
2.表格问答

Example
< 上一篇:
下一篇: >